Pre-Forgettable Models: Prompt Learning as a Native Mechanism for Unlearning
作者: Rutger Hendrix, Giovanni Patanè, Leonardo G. Russo, Simone Carnemolla, Giovanni Bellitto, Federica Proietto Salanitri, Concetto Spampinato, Matteo Pennisi
分类: cs.LG, cs.AI
发布日期: 2025-09-05
备注: Accepted at ACM multimedia 2025 BNI track
💡 一句话要点
提出Pre-Forgettable模型,通过Prompt学习实现模型原生可遗忘性,解决数据隐私合规问题。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 可遗忘学习 Prompt学习 数据隐私 模型安全 联邦学习 持续学习 知识擦除
📋 核心要点
- 现有模型遗忘特定数据时,重新训练等方法计算成本高,难以适应实时系统,且可能影响模型性能。
- 提出Pre-Forgettable模型,将类级别语义绑定到Prompt token,通过移除Prompt实现知识遗忘。
- 实验表明,该方法在有效遗忘指定类别的同时,保持了模型在保留类别上的预测性能,并增强了隐私保护。
📝 摘要(中文)
基础模型已经通过在不同模态和任务中实现鲁棒且可迁移的表示,从而改变了多媒体分析。然而,它们的静态部署与日益增长的社会和监管需求相冲突——特别是根据GDPR等隐私框架的要求,需要应要求遗忘特定数据。传统的遗忘方法,包括重新训练、激活编辑或蒸馏,通常计算成本高昂、脆弱且不适合实时或不断发展的系统。在本文中,我们提出了一种范式转变:将遗忘重新思考为一种内置能力,而不是一种追溯干预。我们引入了一种基于Prompt的学习框架,该框架在单个训练阶段统一了知识获取和移除。我们的方法不是将信息编码在模型权重中,而是将类级别的语义绑定到专用的Prompt token。这种设计使得只需删除相应的Prompt即可实现即时遗忘——无需重新训练、模型修改或访问原始数据。实验表明,我们的框架在保留类上的预测性能的同时,有效地擦除了被遗忘的类。除了实用性之外,我们的方法还表现出强大的隐私和安全保证:它能够抵抗成员推理攻击,并且Prompt删除可以防止任何残留知识提取,即使在对抗条件下也是如此。这确保了符合数据保护原则,并防止未经授权访问被遗忘的信息,从而使该框架适合在敏感和受监管的环境中部署。总而言之,通过将可移除性嵌入到架构本身中,这项工作为设计模块化、可扩展且符合伦理的AI模型奠定了新的基础。
🔬 方法详解
问题定义:论文旨在解决大型预训练模型在需要遗忘特定数据时所面临的挑战。现有方法,如重训练、激活编辑和知识蒸馏,计算成本高昂,效率低下,并且可能损害模型在其他任务上的性能。此外,这些方法通常需要访问原始数据,这在某些隐私敏感的场景下是不可行的。
核心思路:论文的核心思路是将知识的存储与模型的权重解耦,而是将特定类别的信息绑定到可移除的Prompt token上。通过这种方式,遗忘特定类别的信息只需要移除对应的Prompt token,而无需修改模型的权重或访问原始数据。这种设计使得遗忘过程变得高效、可控且安全。
技术框架:该框架主要包含以下几个步骤:1) 使用Prompt学习方法训练模型,将每个类别的信息编码到对应的Prompt token中。2) 当需要遗忘某个类别时,直接移除与该类别相关的Prompt token。3) 模型在没有该Prompt token的情况下,将无法访问或利用该类别的信息。整个过程无需重新训练模型或修改模型权重。
关键创新:该方法最重要的创新点在于将遗忘能力内置于模型的架构设计中,而不是将其视为一种事后干预。通过Prompt学习,模型将知识存储在可移除的Prompt token中,从而实现了即时、高效且安全的遗忘。这种方法与传统的遗忘方法相比,具有显著的优势,尤其是在处理大规模预训练模型时。
关键设计:关键设计包括:1) 如何选择合适的Prompt token,使其能够有效地编码类别信息。2) 如何设计损失函数,以确保模型在学习过程中将类别信息绑定到Prompt token上。3) 如何评估遗忘效果,并确保遗忘过程不会对模型在其他任务上的性能产生负面影响。论文可能使用了特定的Prompt模板、损失函数或正则化项来优化Prompt学习过程。
🖼️ 关键图片

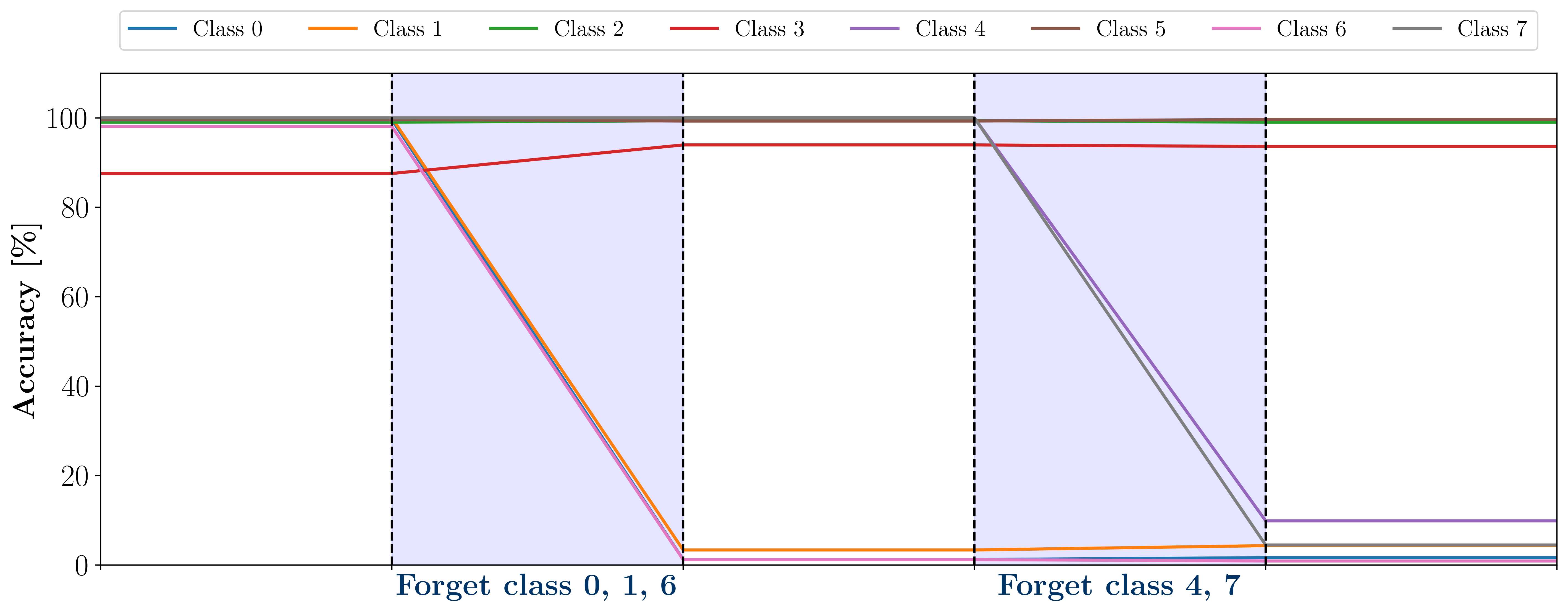
📊 实验亮点
实验结果表明,该方法能够在有效遗忘指定类别的同时,保持模型在保留类别上的预测性能。此外,该方法还具有很强的隐私保护能力,能够抵抗成员推理攻击,并防止任何残留知识提取,即使在对抗条件下也是如此。具体性能数据和对比基线信息未知,需要在论文中查找。
🎯 应用场景
该研究成果可应用于需要数据隐私保护的领域,如医疗、金融等。例如,在用户要求删除个人数据时,可以快速且安全地从模型中移除相关信息,而无需重新训练整个模型。此外,该方法还可用于构建模块化、可扩展的AI系统,方便知识的添加、删除和更新。
📄 摘要(原文)
Foundation models have transformed multimedia analysis by enabling robust and transferable representations across diverse modalities and tasks. However, their static deployment conflicts with growing societal and regulatory demands -- particularly the need to unlearn specific data upon request, as mandated by privacy frameworks such as the GDPR. Traditional unlearning approaches, including retraining, activation editing, or distillation, are often computationally expensive, fragile, and ill-suited for real-time or continuously evolving systems. In this paper, we propose a paradigm shift: rethinking unlearning not as a retroactive intervention but as a built-in capability. We introduce a prompt-based learning framework that unifies knowledge acquisition and removal within a single training phase. Rather than encoding information in model weights, our approach binds class-level semantics to dedicated prompt tokens. This design enables instant unlearning simply by removing the corresponding prompt -- without retraining, model modification, or access to original data. Experiments demonstrate that our framework preserves predictive performance on retained classes while effectively erasing forgotten ones. Beyond utility, our method exhibits strong privacy and security guarantees: it is resistant to membership inference attacks, and prompt removal prevents any residual knowledge extraction, even under adversarial conditions. This ensures compliance with data protection principles and safeguards against unauthorized access to forgotten information, making the framework suitable for deployment in sensitive and regulated environments. Overall, by embedding removability into the architecture itself, this work establishes a new foundation for designing modular, scalable and ethically responsive AI models.