On Using Large-Batches in Federated Learning
作者: Sahil Tyagi
分类: cs.LG, cs.AI, cs.DC
发布日期: 2025-09-05
💡 一句话要点
探索联邦学习中大批量训练的优势与挑战,提升模型泛化能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 联邦学习 大批量训练 小批量训练 模型泛化 分布式训练
📋 核心要点
- 联邦学习面临并行性能和模型泛化能力之间的权衡,大批量训练虽然加速训练,但可能导致泛化性能下降。
- 论文旨在探索联邦学习中大小批量训练的折衷方案,以期同时获得大批量的并行加速和小批量的良好泛化能力。
- 实验结果表明,所提出的方法在ResNet50和VGG11模型上,相较于小批量训练,测试准确率分别提升了32.33%和3.74%。
📝 摘要(中文)
高效的联邦学习(FL)对于在计算资源和网络带宽受限的设备上训练深度网络至关重要。随着大数据时代的到来,设备生成或收集多模态数据,用于训练通用或局部上下文感知的网络,尤其是在数据隐私和本地性至关重要时。联邦学习算法通常在并行性能和统计性能之间进行权衡,以更高的通信频率为代价来提高模型质量,反之亦然。在高频同步设置下,联邦学习通过处理更大的全局批量大小,从而在每个训练迭代中执行更多的工作,从而获得可观的训练加速。然而,由于与大批量训练相关的泛化退化问题,这可能导致较差的测试性能(即,较低的测试损失或准确性)。为了解决大批量带来的这些挑战,本文提出了利用小批量和大批量训练之间的权衡的愿景,并探索新的方向,以同时享受大批量的并行扩展和小批量训练的良好泛化能力。对于相同的迭代次数,我们观察到我们提出的的大批量训练技术在ResNet50和VGG11模型中分别比小批量训练获得了约32.33%和3.74%的更高的测试准确率。
🔬 方法详解
问题定义:联邦学习中,使用大批量训练可以加速训练过程,但容易导致模型泛化能力下降,即在测试集上的表现不佳。现有方法难以兼顾训练速度和模型泛化性能。
核心思路:论文的核心思路是探索大小批量训练之间的折衷方案。通过某种策略,使得模型既能利用大批量训练的并行加速优势,又能保持小批量训练的良好泛化能力。具体策略未知。
技术框架:论文并未明确给出详细的技术框架,但可以推断其核心在于设计一种自适应的批量大小调整策略,或者采用某种正则化方法来缓解大批量训练带来的泛化问题。整体流程可能包括:初始化模型、客户端本地训练(使用大小批量策略)、服务器聚合模型、评估模型性能等步骤。
关键创新:论文的关键创新在于提出了一个利用大小批量训练折衷的联邦学习训练方法。虽然具体的技术细节未知,但这种思路为解决联邦学习中的泛化问题提供了一个新的方向。与现有方法相比,该方法旨在同时优化训练速度和模型泛化能力。
关键设计:论文中没有明确给出关键设计细节,例如具体的批量大小调整策略、损失函数或网络结构。这些细节是实现大小批量训练折衷的关键,需要进一步的研究来确定最佳方案。批量大小的调整可能依赖于客户端的数据量、计算能力以及训练过程中的模型性能反馈。
🖼️ 关键图片

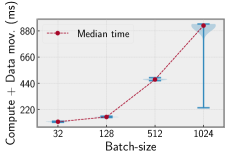
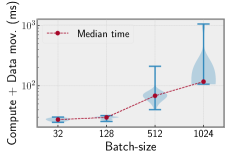
📊 实验亮点
实验结果显示,在ResNet50模型上,所提出的方法比小批量训练的测试准确率提高了32.33%;在VGG11模型上,测试准确率提高了3.74%。这表明该方法在一定程度上缓解了大批量训练带来的泛化问题,并提升了模型的整体性能。
🎯 应用场景
该研究成果可应用于各种需要保护用户数据隐私的联邦学习场景,例如移动设备上的个性化推荐、医疗影像分析、金融风控等。通过提升联邦学习模型的训练效率和泛化能力,可以更好地利用海量分散的数据,为用户提供更优质的服务,同时保障数据安全。
📄 摘要(原文)
Efficient Federated learning (FL) is crucial for training deep networks over devices with limited compute resources and bounded networks. With the advent of big data, devices either generate or collect multimodal data to train either generic or local-context aware networks, particularly when data privacy and locality is vital. FL algorithms generally trade-off between parallel and statistical performance, improving model quality at the cost of higher communication frequency, or vice versa. Under frequent synchronization settings, FL over a large cluster of devices may perform more work per-training iteration by processing a larger global batch-size, thus attaining considerable training speedup. However, this may result in poor test performance (i.e., low test loss or accuracy) due to generalization degradation issues associated with large-batch training. To address these challenges with large-batches, this work proposes our vision of exploiting the trade-offs between small and large-batch training, and explore new directions to enjoy both the parallel scaling of large-batches and good generalizability of small-batch training. For the same number of iterations, we observe that our proposed large-batch training technique attains about 32.33% and 3.74% higher test accuracy than small-batch training in ResNet50 and VGG11 models respectively.