veScale: Consistent and Efficient Tensor Programming with Eager-Mode SPMD
作者: Youjie Li, Cheng Wan, Zhiqi Lin, Hongyu Zhu, Jiacheng Yang, Ziang Song, Xinyi Di, Jiawei Wu, Huiyao Shu, Wenlei Bao, Yanghua Peng, Haibin Lin, Li-Wen Chang
分类: cs.PL, cs.DC, cs.LG
发布日期: 2025-09-05
备注: 21 pages, 16 figures, 5 tables
💡 一句话要点
veScale:通过Eager模式SPMD实现一致且高效的张量编程
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 分布式训练 SPMD Eager模式 随机数生成 性能优化
📋 核心要点
- 现有分布式训练系统,如PyTorch,在Eager模式下使用SPMD时,存在结果不一致和性能瓶颈问题。
- veScale通过创新的分布式RNG算法保证了与单设备执行结果的一致性,并优化了PyTorch原语和通信效率。
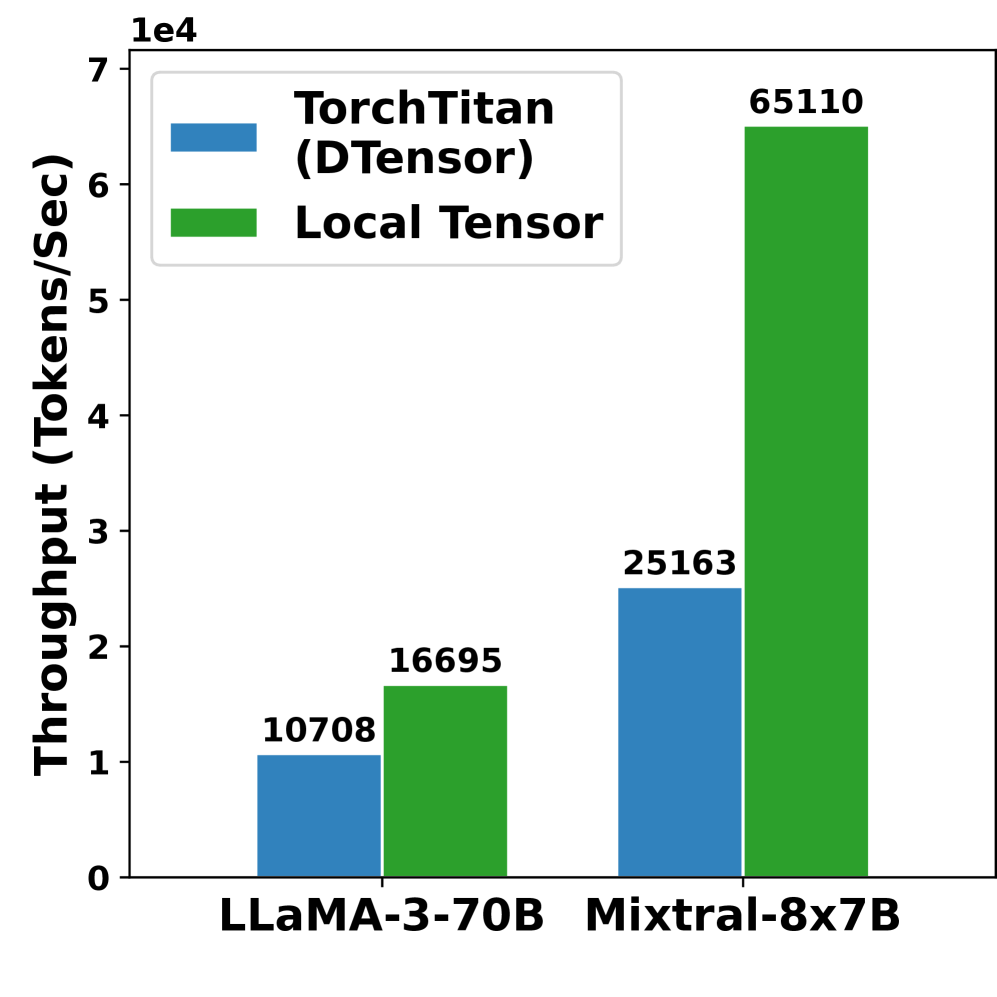
- 实验表明,veScale在训练速度上比TorchTitan提升高达2.2倍,并显著降低了代码复杂性。
📝 摘要(中文)
大型语言模型(LLMs)在规模和复杂性上迅速增长,需要越来越复杂的并行化方法进行分布式训练,例如3D并行。这种复杂性促使人们转向更简单、更易于调试的编程范式,如单程序多数据(SPMD)。然而,Eager模式执行中的SPMD引入了两个关键挑战:确保与单设备执行的一致性,以及实现大规模下的高性能。本文介绍了veScale,一个Eager模式训练系统,它完全采用SPMD范式,以普及分布式张量编程。veScale通过引入一种与任意分片算子兼容的分布式随机数生成(RNG)的新算法,解决了PyTorch等系统中普遍存在的结果不一致问题。veScale还通过减少PyTorch原语的开销和提高通信效率,显著提高了训练性能。评估表明,veScale比最先进的训练系统(如TorchTitan)实现了高达2.2倍的加速,并将代码复杂性降低了78.4%,同时保持了与单设备等效的结果。
🔬 方法详解
问题定义:现有基于Eager模式的SPMD分布式训练系统,例如直接使用PyTorch进行分布式训练,面临着两个主要问题。一是由于不同设备上的随机数生成方式不同,导致训练结果与单设备训练不一致,难以调试和复现。二是PyTorch原语的开销较大,且通信效率不高,限制了大规模分布式训练的性能。
核心思路:veScale的核心思路是完全拥抱SPMD编程范式,并解决Eager模式下SPMD的固有问题。通过设计一种分布式RNG算法,保证不同设备上生成的随机数序列与单设备一致,从而解决结果不一致的问题。同时,通过优化PyTorch原语的执行效率和通信策略,提升整体训练性能。
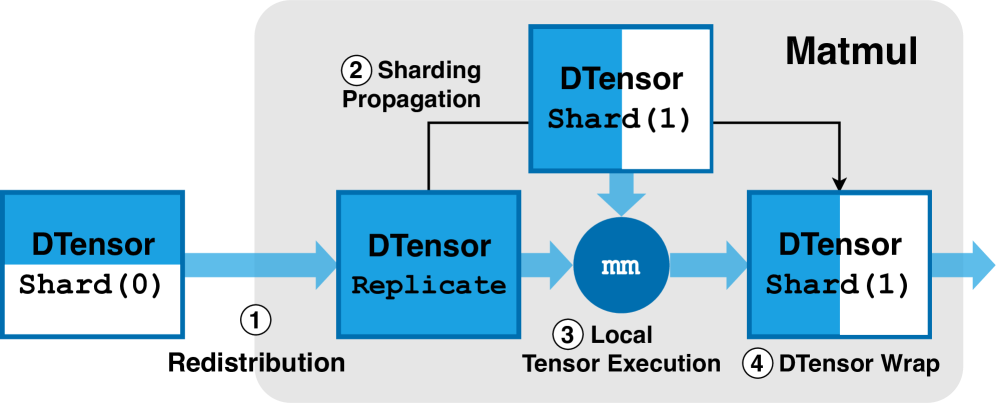
技术框架:veScale是一个基于Eager模式的分布式训练系统,其整体架构包括以下几个主要模块:1) 分布式RNG模块:负责生成与单设备一致的随机数序列。2) 张量分片和重组模块:负责将张量在不同设备上进行分片和重组。3) 通信模块:负责设备之间的通信,例如梯度同步。4) PyTorch原语优化模块:负责优化PyTorch原语的执行效率。训练流程与标准的Eager模式SPMD训练流程类似,但在随机数生成、张量操作和通信等方面进行了优化。
关键创新:veScale最重要的技术创新点在于其分布式RNG算法。该算法能够在保证与单设备RNG一致性的前提下,高效地生成分布式随机数。与现有方法相比,该算法能够兼容任意分片算子,避免了对算子的修改或限制。此外,veScale还通过优化PyTorch原语的执行效率和通信策略,进一步提升了训练性能。
关键设计:veScale的分布式RNG算法基于一种预先计算并分发的策略。首先,在单设备上预先生成一个足够长的随机数序列。然后,将该序列分发到不同的设备上,每个设备根据其分片信息,从序列中选择相应的随机数。为了保证一致性,需要仔细设计分发策略,确保每个设备选择的随机数与单设备执行时相同。此外,veScale还采用了多种优化技术来提升PyTorch原语的执行效率,例如算子融合和内存复用。在通信方面,veScale采用了高效的通信库,例如NCCL,并优化了通信策略,例如梯度压缩。
🖼️ 关键图片
📊 实验亮点
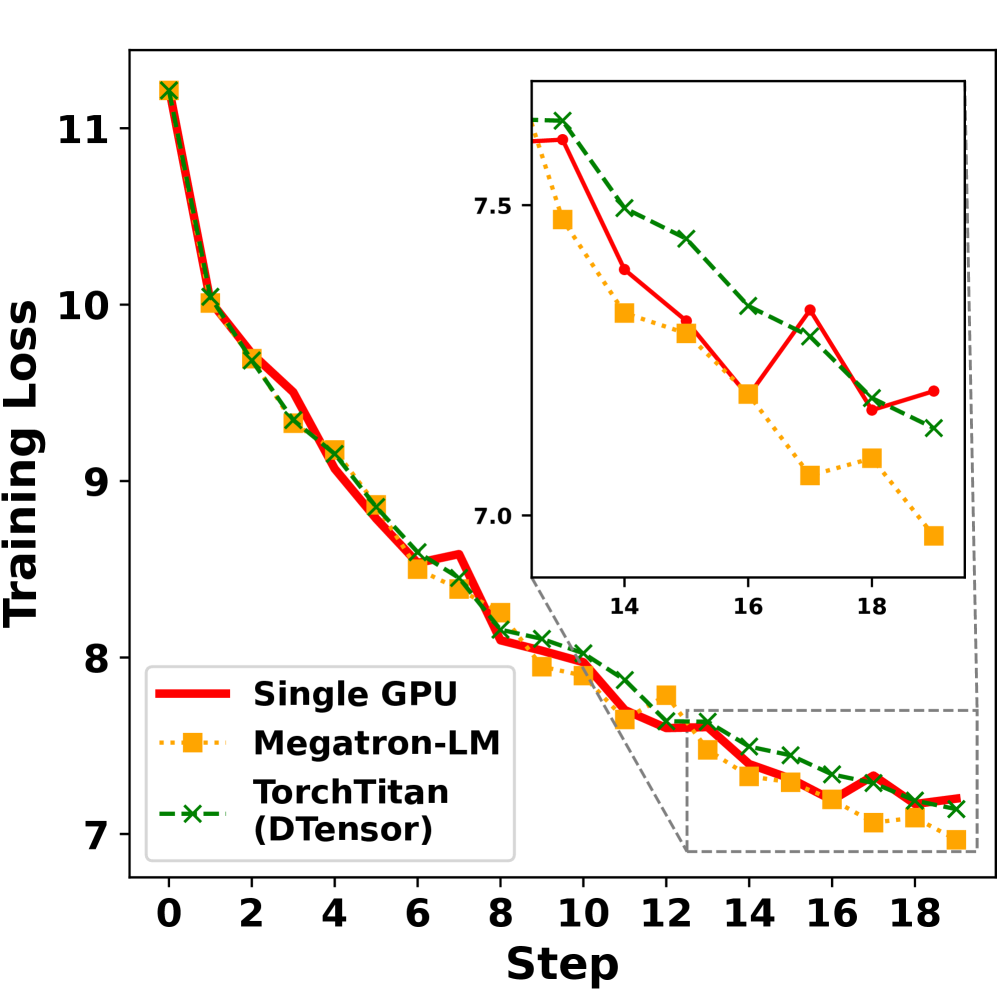
veScale在多个大型语言模型训练任务上进行了评估,实验结果表明,veScale比最先进的训练系统TorchTitan实现了高达2.2倍的加速。此外,veScale还将代码复杂性降低了78.4%,显著提高了开发效率。最重要的是,veScale保证了与单设备训练结果的一致性,解决了分布式训练中的一个关键难题。
🎯 应用场景
veScale可应用于各种需要大规模分布式训练的场景,例如训练大型语言模型、图像识别模型和推荐系统模型。它降低了分布式训练的复杂性,提高了训练效率,使得更多的研究人员和工程师能够轻松地进行大规模模型训练。未来,veScale有望成为分布式训练领域的重要工具,推动人工智能技术的发展。
📄 摘要(原文)
Large Language Models (LLMs) have scaled rapidly in size and complexity, requiring increasingly intricate parallelism for distributed training, such as 3D parallelism. This sophistication motivates a shift toward simpler, more debuggable programming paradigm like Single Program Multiple Data (SPMD). However, SPMD in eager execution introduces two key challenges: ensuring consistency with single-device execution and achieving high performance at scale. In this paper, we introduce veScale, an eager-mode training system that fully embraces SPMD paradigm to democratize distributed tensor programming. veScale addresses the prevalent issue of inconsistent results in systems like PyTorch by introducing a novel algorithm of distributed Random Number Generation (RNG) compatible with arbitrary sharded operators. veScale also significantly boosts training performance by reducing PyTorch primitive's overhead and improving communication efficiency. Evaluations show that veScale delivers up to 2.2x speedup over the state-of-the-art training systems, like TorchTitan, and cuts code complexity by 78.4%, while preserving single-device-equivalent results.