Neural Breadcrumbs: Membership Inference Attacks on LLMs Through Hidden State and Attention Pattern Analysis
作者: Disha Makhija, Manoj Ghuhan Arivazhagan, Vinayshekhar Bannihatti Kumar, Rashmi Gangadharaiah
分类: cs.LG, cs.AI
发布日期: 2025-09-05
💡 一句话要点
提出memTrace,通过分析LLM内部表征进行成员推断攻击,揭示潜在隐私泄露。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 成员推断攻击 大型语言模型 隐私泄露 隐藏状态分析 注意力机制
📋 核心要点
- 现有成员推断攻击对LLM效果不佳,难以有效检测大规模预训练带来的隐私泄露风险。
- memTrace通过分析LLM内部隐藏状态和注意力模式,提取“神经面包屑”以检测潜在的记忆指纹。
- 实验表明,memTrace在多个模型上实现了平均0.85的AUC,显著提升了成员推断攻击的效果。
📝 摘要(中文)
成员推断攻击(MIAs)旨在揭示特定数据是否被用于训练机器学习模型,是隐私审计和合规评估的重要工具。现有研究表明,MIAs对大型语言模型(LLMs)的攻击效果仅略优于随机猜测,暗示使用海量数据集的现代预训练方法可能不存在隐私泄露风险。本文提出一种互补的视角,探索通过检查LLMs的内部表征(而非仅输出)来获取潜在的成员推断信号。提出的框架memTrace,遵循“神经面包屑”的思想,从Transformer的隐藏状态和注意力模式中提取信息信号。通过分析层间表征动态、注意力分布特征和跨层转换模式,检测传统基于损失的方法可能无法捕获的潜在记忆指纹。该方法在多个模型系列上实现了强大的成员检测,在流行的MIA基准测试中平均AUC得分达到0.85。研究结果表明,即使基于输出的信号看起来受到保护,内部模型行为也可能揭示训练数据暴露的方面,强调需要进一步研究成员隐私,并为大型语言模型开发更强大的隐私保护训练技术。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLMs)的成员推断问题。现有基于输出的成员推断攻击方法在LLMs上表现不佳,无法有效检测模型是否记忆了特定训练数据,这使得评估和防范LLMs的隐私泄露风险变得困难。现有方法的痛点在于,它们忽略了LLMs内部表征中可能存在的隐私信息。
核心思路:论文的核心思路是,即使LLMs的输出看起来是泛化的,其内部隐藏状态和注意力模式仍然可能保留了关于训练数据的记忆痕迹。通过分析这些内部表征,可以更有效地进行成员推断攻击。这种思路类似于追踪“神经面包屑”,即模型在处理输入序列时留下的内部状态信息。
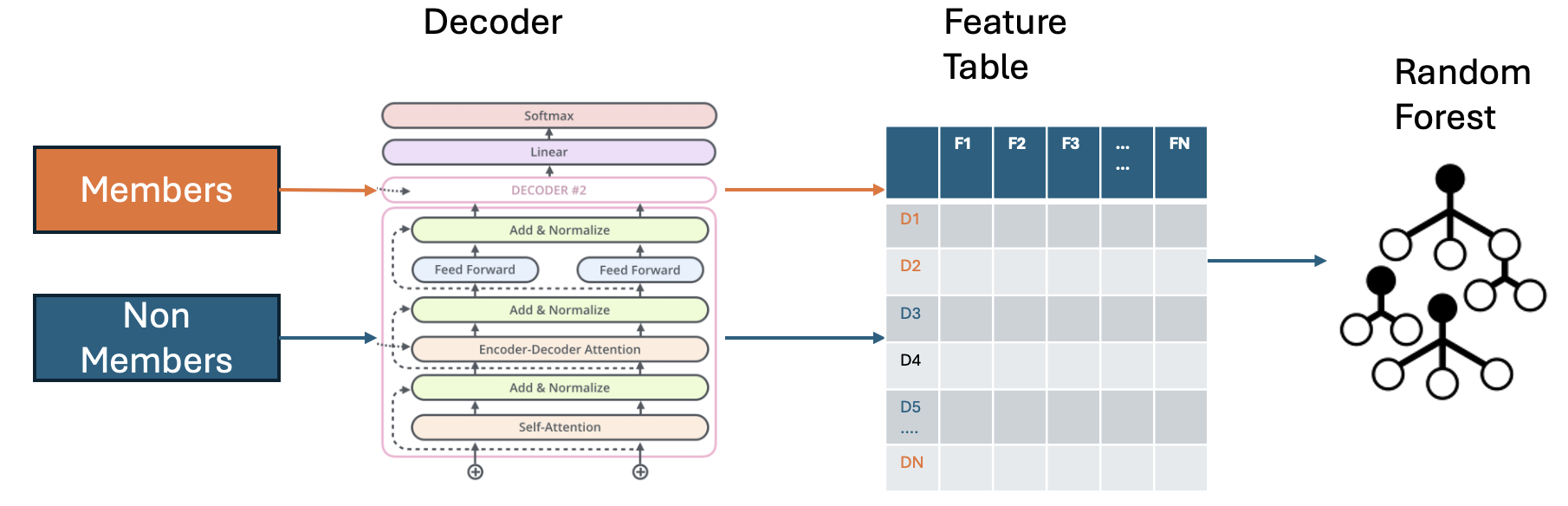
技术框架:memTrace框架主要包含以下几个阶段:1) 数据准备:准备目标模型和候选成员数据。2) 前向传播:将候选序列输入LLM,记录每一层的隐藏状态和注意力权重。3) 特征提取:从隐藏状态和注意力权重中提取特征,例如层间表征动态、注意力分布特征和跨层转换模式。4) 成员推断:使用提取的特征训练分类器,判断候选序列是否为训练集成员。
关键创新:论文最重要的技术创新点在于,它将成员推断攻击的重点从LLMs的输出转移到其内部表征。通过分析隐藏状态和注意力模式,memTrace能够发现传统方法难以捕获的记忆指纹。这种方法能够更有效地利用LLMs的内部信息,从而提高成员推断攻击的成功率。与现有方法相比,memTrace不需要访问模型的训练数据或进行复杂的模型逆向工程。
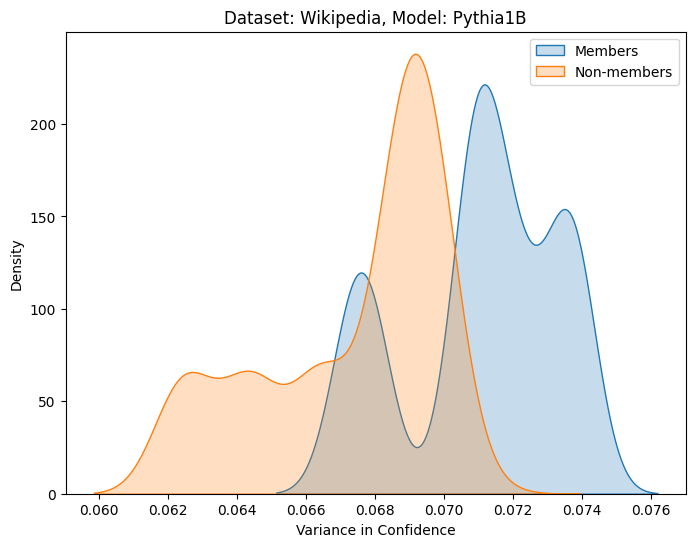
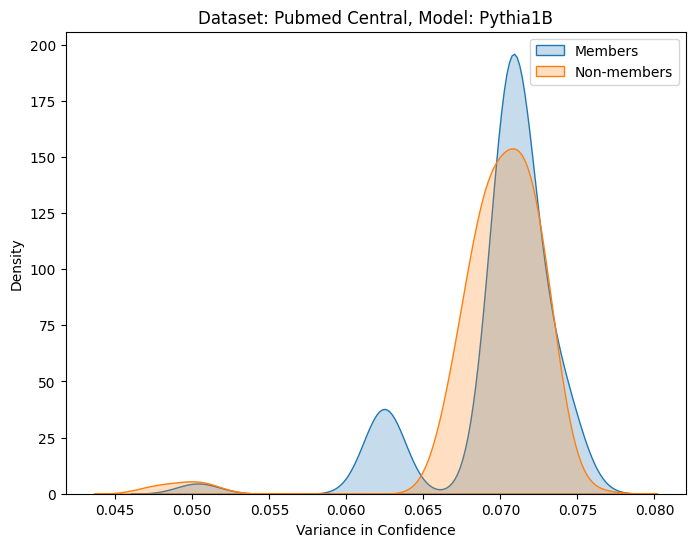
关键设计:在特征提取阶段,论文设计了多种特征来捕捉LLMs的内部行为。例如,层间表征动态可以通过计算相邻层隐藏状态之间的差异来衡量;注意力分布特征可以通过计算注意力权重的统计量(如均值、方差)来衡量;跨层转换模式可以通过分析不同层之间的注意力权重变化来衡量。这些特征被输入到分类器(如逻辑回归或支持向量机)中进行训练,以区分成员数据和非成员数据。论文还探索了不同层和不同特征的组合方式,以优化成员推断的性能。
🖼️ 关键图片
📊 实验亮点
实验结果表明,memTrace在多个模型系列(包括GPT-2、GPT-Neo和GPT-J)上实现了强大的成员检测能力,平均AUC得分达到0.85。与传统的基于损失的成员推断攻击方法相比,memTrace能够显著提高攻击成功率。实验还表明,不同层和不同特征对成员推断的贡献不同,选择合适的层和特征组合可以进一步提高攻击性能。
🎯 应用场景
该研究成果可应用于评估和审计大型语言模型的隐私风险,帮助开发者了解模型是否过度记忆了敏感数据。同时,该研究也为开发更强大的隐私保护训练技术提供了新的思路,例如通过正则化内部表征或使用差分隐私技术来防止模型记忆训练数据。此外,该方法还可以用于检测模型是否存在数据污染或后门攻击。
📄 摘要(原文)
Membership inference attacks (MIAs) reveal whether specific data was used to train machine learning models, serving as important tools for privacy auditing and compliance assessment. Recent studies have reported that MIAs perform only marginally better than random guessing against large language models, suggesting that modern pre-training approaches with massive datasets may be free from privacy leakage risks. Our work offers a complementary perspective to these findings by exploring how examining LLMs' internal representations, rather than just their outputs, may provide additional insights into potential membership inference signals. Our framework, \emph{memTrace}, follows what we call \enquote{neural breadcrumbs} extracting informative signals from transformer hidden states and attention patterns as they process candidate sequences. By analyzing layer-wise representation dynamics, attention distribution characteristics, and cross-layer transition patterns, we detect potential memorization fingerprints that traditional loss-based approaches may not capture. This approach yields strong membership detection across several model families achieving average AUC scores of 0.85 on popular MIA benchmarks. Our findings suggest that internal model behaviors can reveal aspects of training data exposure even when output-based signals appear protected, highlighting the need for further research into membership privacy and the development of more robust privacy-preserving training techniques for large language models.