Greener Deep Reinforcement Learning: Analysis of Energy and Carbon Efficiency Across Atari Benchmarks
作者: Jason Gardner, Ayan Dutta, Swapnoneel Roy, O. Patrick Kreidl, Ladislau Boloni
分类: cs.LG, cs.PF
发布日期: 2025-09-05
备注: Submitted to a journal - under review
💡 一句话要点
评估深度强化学习算法在Atari游戏中能源消耗与碳排放效率,为绿色AI提供基准。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 深度强化学习 能源效率 碳排放 绿色AI 基准测试
📋 核心要点
- 现有DRL研究主要关注算法性能,忽略了训练过程中的能源消耗、碳排放和经济成本。
- 该研究通过系统性实验,对比了七种主流DRL算法在Atari游戏上的能耗和碳排放情况。
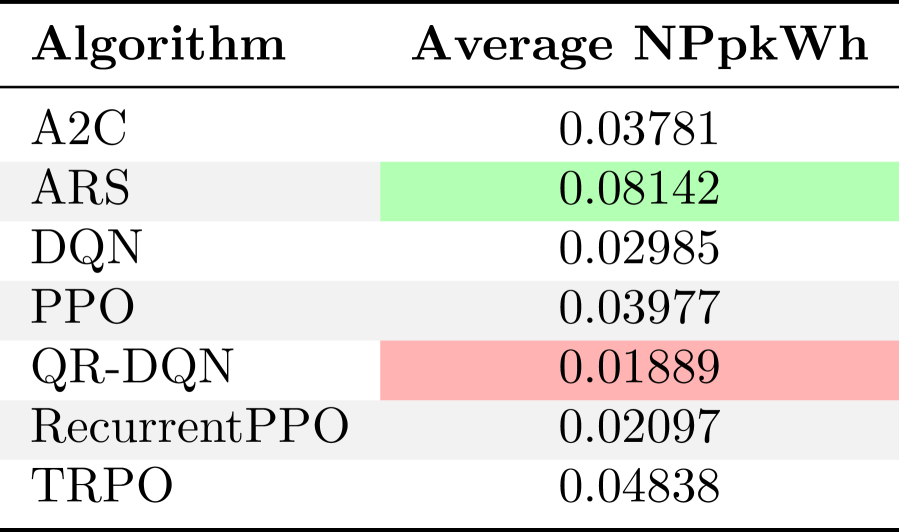
- 实验结果揭示了不同算法在能耗和成本上的显著差异,为绿色DRL算法设计提供了依据。
📝 摘要(中文)
深度强化学习(DRL)日益增长的计算需求引发了人们对训练大规模模型所带来的环境和经济成本的担忧。虽然在学习性能方面的算法效率已被广泛研究,但DRL算法的能源需求、温室气体排放和货币成本在很大程度上仍未被探索。本文对七种最先进的DRL算法(DQN、TRPO、A2C、ARS、PPO、RecurrentPPO和QR-DQN)的能耗进行了系统的基准测试研究,这些算法均使用Stable Baselines实现。每种算法在十个Atari 2600游戏中训练一百万步,并实时测量功耗,以根据美国国家平均电价估算总能源使用量、二氧化碳当量排放量和电力成本。结果表明,不同算法在能源效率和训练成本方面存在显著差异,其中一些算法在消耗高达24%更少能源(ARS vs. DQN)、排放近68%更少二氧化碳以及产生几乎68%更低货币成本(QR-DQN vs. RecurrentPPO)的情况下,实现了相当的性能。我们进一步分析了学习性能、训练时间、能源使用和财务成本之间的权衡,突出了算法选择可以在不牺牲学习性能的情况下减轻环境和经济影响的情况。这项研究为开发具有能源意识和成本效益的DRL实践提供了可操作的见解,并为将可持续性考虑因素纳入未来的算法设计和评估奠定了基础。
🔬 方法详解
问题定义:论文旨在解决DRL算法训练过程中能源消耗高、碳排放量大以及经济成本高的问题。现有研究主要关注算法在学习性能方面的提升,而忽略了其环境和经济影响。因此,需要对现有DRL算法的能源效率进行系统评估,并为开发更绿色的DRL算法提供指导。
核心思路:论文的核心思路是通过对多种主流DRL算法在统一的Atari游戏环境中进行训练,并实时测量其功耗,从而评估其能源效率、碳排放量和经济成本。通过对比不同算法的能耗和性能,揭示算法选择对环境和经济的影响,并为开发更绿色的DRL算法提供依据。
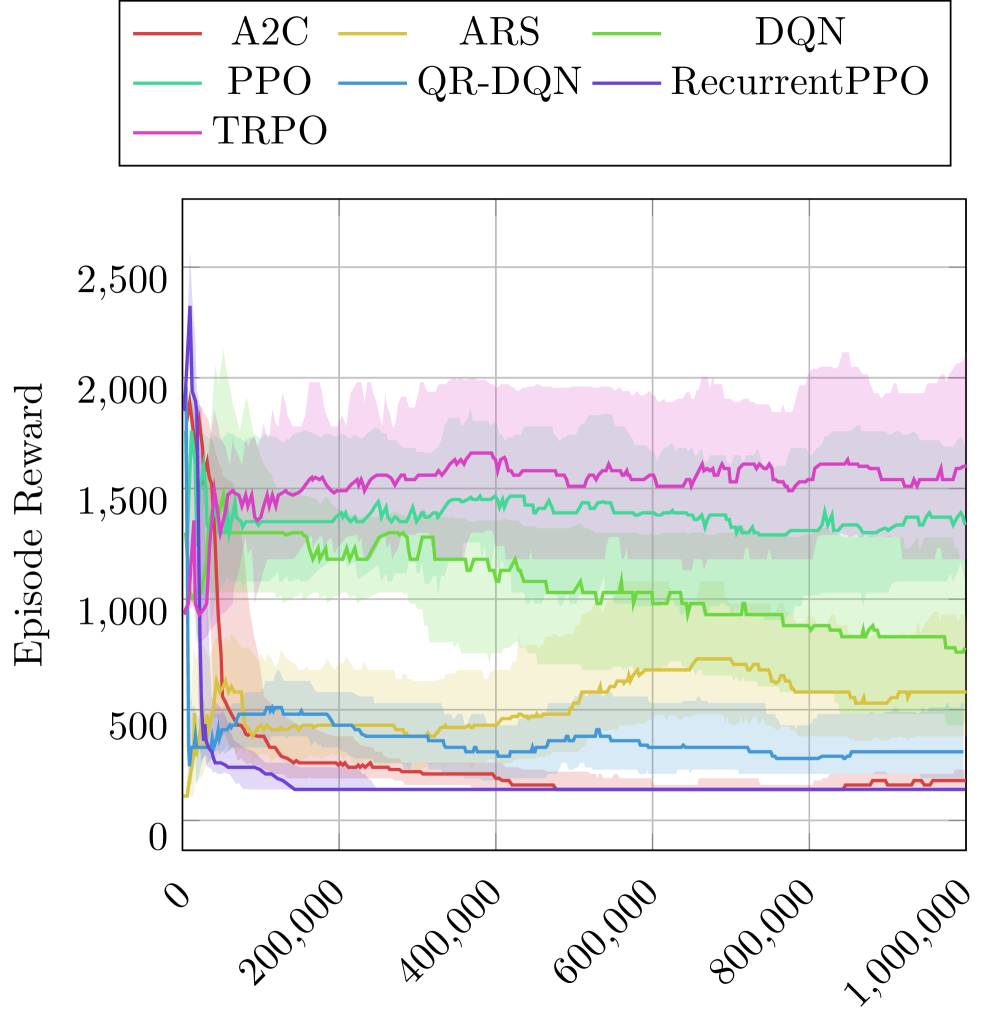
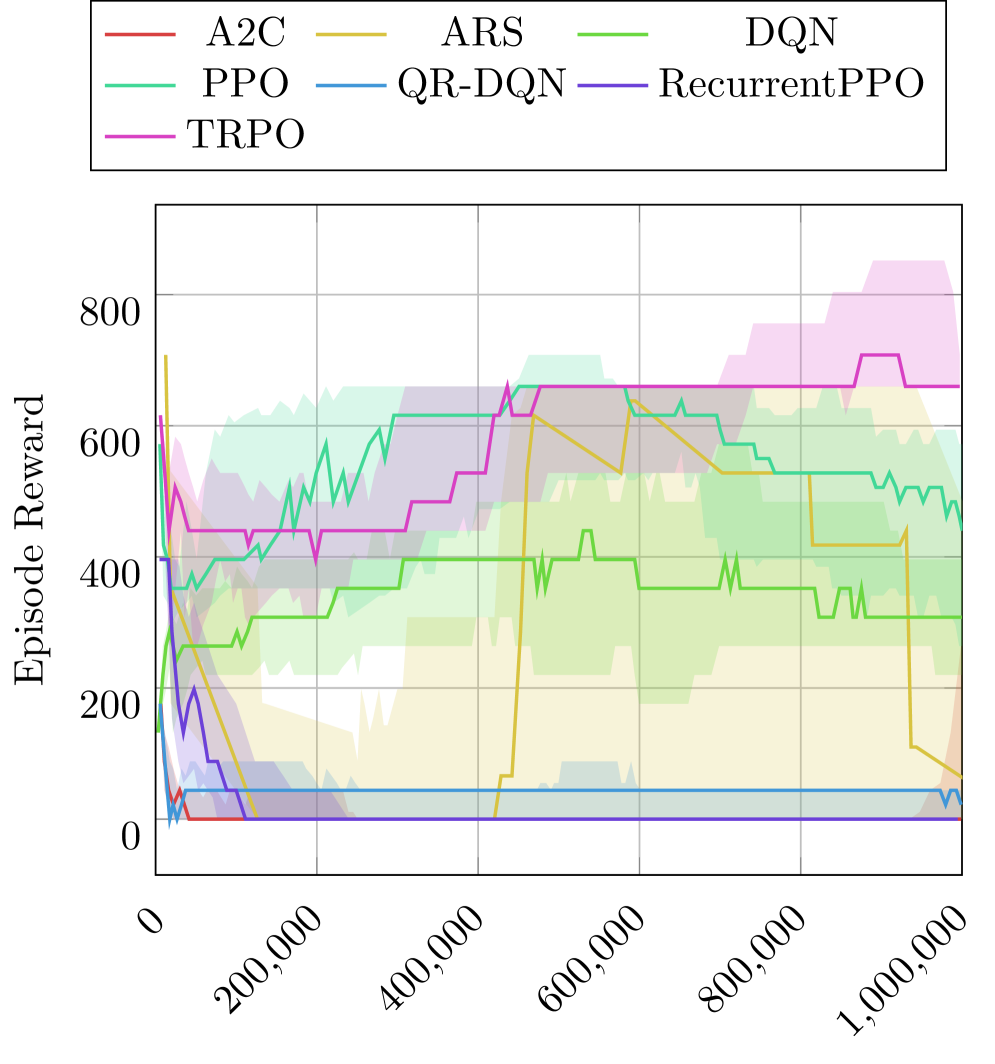
技术框架:该研究的技术框架主要包括以下几个步骤: 1. 选择七种主流DRL算法:DQN、TRPO、A2C、ARS、PPO、RecurrentPPO和QR-DQN。 2. 使用Stable Baselines库实现这些算法。 3. 在十个Atari 2600游戏上训练这些算法,每个算法训练一百万步。 4. 实时测量训练过程中的功耗。 5. 根据功耗数据估算总能源使用量、二氧化碳当量排放量和电力成本。 6. 分析不同算法在能源效率、碳排放量、经济成本和学习性能之间的权衡。
关键创新:该研究的关键创新在于首次对多种主流DRL算法的能源效率、碳排放量和经济成本进行了系统性的基准测试。以往的研究主要关注算法在学习性能方面的提升,而忽略了其环境和经济影响。该研究通过实验数据揭示了不同算法在能耗和成本上的显著差异,为开发更绿色的DRL算法提供了重要的参考依据。
关键设计:该研究的关键设计包括: 1. 选择具有代表性的Atari游戏作为测试环境。 2. 使用Stable Baselines库实现DRL算法,保证实验的可重复性。 3. 实时测量功耗,保证能耗数据的准确性。 4. 使用美国国家平均电价计算电力成本,保证成本估算的合理性。 5. 对能源效率、碳排放量、经济成本和学习性能进行综合分析,揭示算法选择对环境和经济的影响。
🖼️ 关键图片
📊 实验亮点
实验结果表明,不同DRL算法在能源效率和训练成本方面存在显著差异。例如,ARS算法相比DQN算法,能耗降低了24%。QR-DQN算法相比RecurrentPPO算法,二氧化碳排放量和货币成本降低了近68%。这些结果表明,通过选择合适的算法,可以在不牺牲学习性能的情况下显著降低DRL训练的环境和经济成本。
🎯 应用场景
该研究成果可应用于指导DRL算法的选择和设计,从而降低AI系统的能源消耗和碳排放,促进绿色AI的发展。此外,该研究提出的能耗评估方法可推广到其他机器学习算法,为评估AI系统的环境影响提供参考。
📄 摘要(原文)
The growing computational demands of deep reinforcement learning (DRL) have raised concerns about the environmental and economic costs of training large-scale models. While algorithmic efficiency in terms of learning performance has been extensively studied, the energy requirements, greenhouse gas emissions, and monetary costs of DRL algorithms remain largely unexplored. In this work, we present a systematic benchmarking study of the energy consumption of seven state-of-the-art DRL algorithms, namely DQN, TRPO, A2C, ARS, PPO, RecurrentPPO, and QR-DQN, implemented using Stable Baselines. Each algorithm was trained for one million steps each on ten Atari 2600 games, and power consumption was measured in real-time to estimate total energy usage, CO2-Equivalent emissions, and electricity cost based on the U.S. national average electricity price. Our results reveal substantial variation in energy efficiency and training cost across algorithms, with some achieving comparable performance while consuming up to 24% less energy (ARS vs. DQN), emitting nearly 68% less CO2, and incurring almost 68% lower monetary cost (QR-DQN vs. RecurrentPPO) than less efficient counterparts. We further analyze the trade-offs between learning performance, training time, energy use, and financial cost, highlighting cases where algorithmic choices can mitigate environmental and economic impact without sacrificing learning performance. This study provides actionable insights for developing energy-aware and cost-efficient DRL practices and establishes a foundation for incorporating sustainability considerations into future algorithmic design and evaluation.