KVCompose: Efficient Structured KV Cache Compression with Composite Tokens
作者: Dmitry Akulov, Mohamed Sana, Antonio De Domenico, Tareq Si Salem, Nicola Piovesan, Fadhel Ayed
分类: cs.LG
发布日期: 2025-09-05 (更新: 2025-09-19)
💡 一句话要点
KVCompose:基于组合Token的高效结构化KV缓存压缩方法
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: KV缓存压缩 长上下文LLM 注意力机制 组合Token 层自适应 模型推理加速
📋 核心要点
- 长文本LLM推理中,KV缓存随上下文长度线性增长,成为内存瓶颈,现有方法存在启发式规则僵化、破坏张量结构或依赖专用计算内核等问题。
- KVCompose通过注意力机制引导,自适应地为每一层选择重要的Token,并将它们组合成统一结构的组合Token,从而实现高效的KV缓存压缩。
- 实验结果表明,KVCompose在显著减少内存占用的同时,保持了模型精度,并且优于现有的结构化和半结构化压缩方法,兼容现有推理流程。
📝 摘要(中文)
大型语言模型(LLMs)依赖于键值(KV)缓存以实现高效的自回归解码;然而,缓存大小随着上下文长度和模型深度的增加而线性增长,成为长上下文推理的主要瓶颈。现有的KV缓存压缩方法要么强制执行严格的启发式方法,要么通过每个注意力头的可变性来破坏张量布局,要么需要专门的计算内核。我们提出了一种简单而有效的KV缓存压缩框架,该框架基于注意力引导的、层自适应的组合Token。我们的方法聚合注意力分数以估计Token的重要性,独立地选择特定于头的Token,并将它们对齐到符合现有推理引擎所需的统一缓存结构的组合Token中。全局分配机制进一步调整跨层的保留预算,为具有信息量Token的层分配更多容量。这种方法在保持精度的同时实现了显著的内存减少,始终优于先前的结构化和半结构化方法。至关重要的是,我们的方法与标准推理管道完全兼容,为高效的长上下文LLM部署提供了一种实用且可扩展的解决方案。
🔬 方法详解
问题定义:论文旨在解决长上下文LLM推理中KV缓存过大导致的内存瓶颈问题。现有KV缓存压缩方法存在以下痛点:一是采用固定的启发式规则,缺乏灵活性;二是破坏了张量的原始布局,引入了额外的计算开销;三是需要定制化的计算内核,通用性较差。这些问题限制了长上下文LLM的实际部署和应用。
核心思路:论文的核心思路是利用注意力机制来评估每个Token的重要性,并基于此选择性地保留重要的Token,从而实现KV缓存的压缩。关键在于,通过将多个Token组合成一个“组合Token”,可以在减少Token数量的同时,保持缓存结构的统一性,避免破坏张量布局。此外,论文还引入了层自适应的Token选择策略,允许不同层根据其Token的重要性分配不同的保留预算。
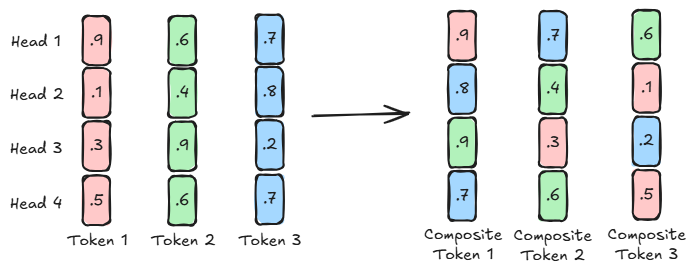
技术框架:KVCompose的整体框架包括以下几个主要阶段:1) 注意力分数聚合:计算每个Token在不同注意力头上的注意力分数,并进行聚合,得到Token的重要性评估;2) 层自适应Token选择:根据Token的重要性,为每一层选择需要保留的Token,并根据全局分配机制调整各层的保留预算;3) 组合Token构建:将选择出的Token组合成统一结构的组合Token,以保持缓存结构的规整性;4) KV缓存更新:利用组合Token更新KV缓存,实现压缩后的KV缓存。
关键创新:KVCompose的关键创新在于:1) 注意力引导的Token选择:利用注意力机制动态评估Token的重要性,避免了固定启发式规则的局限性;2) 组合Token:通过将多个Token组合成一个组合Token,在减少Token数量的同时,保持了缓存结构的统一性,避免了额外的计算开销;3) 层自适应的保留预算:允许不同层根据其Token的重要性分配不同的保留预算,提高了压缩效率。
关键设计:论文的关键设计包括:1) 注意力分数聚合方式:具体如何将不同注意力头上的注意力分数进行聚合,以得到Token的综合重要性评估;2) 层自适应保留预算的分配策略:如何根据各层Token的重要性,动态调整各层的保留预算;3) 组合Token的构建方式:如何将选择出的Token组合成统一结构的组合Token,以保证缓存结构的规整性。这些细节决定了KVCompose的压缩效率和模型精度。
🖼️ 关键图片
📊 实验亮点
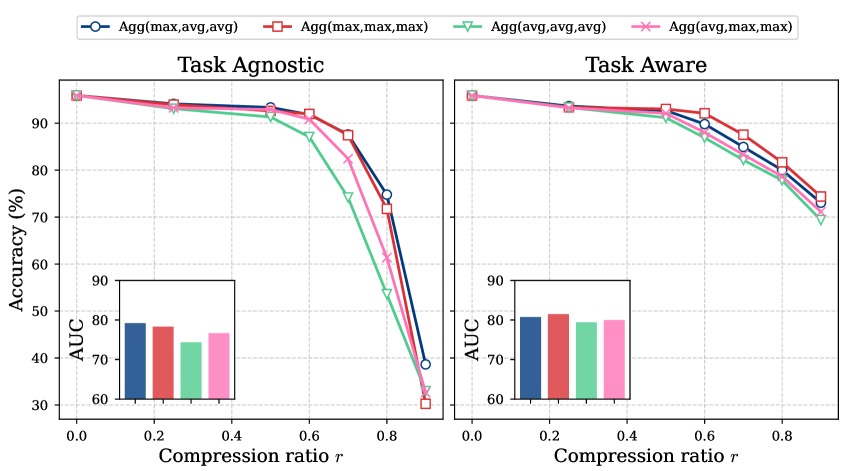
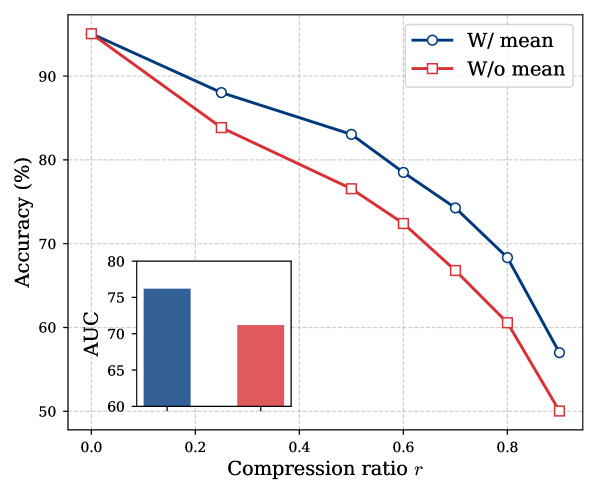
实验结果表明,KVCompose在多个LLM模型上实现了显著的内存压缩,同时保持了模型精度。例如,在某些模型上,KVCompose能够在将KV缓存大小减少50%的情况下,仍然保持与原始模型相当的性能。此外,KVCompose在性能上优于现有的结构化和半结构化压缩方法,证明了其有效性和优越性。
🎯 应用场景
KVCompose可广泛应用于需要处理长上下文的LLM应用场景,例如长文档摘要、机器翻译、代码生成、对话系统等。通过降低KV缓存的内存占用,KVCompose能够支持更大规模的模型和更长的上下文长度,从而提升LLM的性能和应用范围。此外,该方法与现有推理流程的兼容性使其易于部署和应用,具有很高的实际价值。
📄 摘要(原文)
Large language models (LLMs) rely on key-value (KV) caches for efficient autoregressive decoding; however, cache size grows linearly with context length and model depth, becoming a major bottleneck in long-context inference. Prior KV cache compression methods either enforce rigid heuristics, disrupt tensor layouts with per-attention-head variability, or require specialized compute kernels. We propose a simple, yet effective, KV cache compression framework based on attention-guided, layer-adaptive composite tokens. Our method aggregates attention scores to estimate token importance, selects head-specific tokens independently, and aligns them into composite tokens that respect the uniform cache structure required by existing inference engines. A global allocation mechanism further adapts retention budgets across layers, assigning more capacity to layers with informative tokens. This approach achieves significant memory reduction while preserving accuracy, consistently outperforming prior structured and semi-structured methods. Crucially, our approach remains fully compatible with standard inference pipelines, offering a practical and scalable solution for efficient long-context LLM deployment.