An Arbitration Control for an Ensemble of Diversified DQN variants in Continual Reinforcement Learning
作者: Wonseo Jang, Dongjae Kim
分类: cs.LG, cs.MA
发布日期: 2025-09-05
备注: 8 pages, 8 figures
💡 一句话要点
提出ACED-DQN,通过仲裁控制多样化DQN集成解决持续强化学习中的灾难性遗忘问题
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 持续强化学习 灾难性遗忘 集成学习 仲裁控制 DQN 深度强化学习 多样性
📋 核心要点
- 深度强化学习在持续学习中面临灾难性遗忘问题,导致模型无法有效保持和利用先前学习的知识。
- 论文提出ACED-DQN框架,通过集成多样化的DQN变体,并采用仲裁控制机制来选择最优策略。
- 实验结果表明,ACED-DQN在静态和持续环境中均能显著提升性能,验证了仲裁控制的有效性。
📝 摘要(中文)
深度强化学习(RL)模型在静态环境中学习最优策略时表现高效,但容易丢失先前学习的知识(即灾难性遗忘)。这导致RL模型在持续强化学习(CRL)场景中表现不佳。为了解决这个问题,我们提出了一种基于RL智能体集成的仲裁控制机制。该机制的灵感来源于人类在前额叶皮层中观察到的,在CRL环境中并行使用多个RL智能体并通过仲裁控制进行决策的方式。我们将两个关键思想融入到我们的模型中:(1)显式训练以具有多样化价值函数的RL集成(即DQN变体);(2)一种仲裁控制,优先考虑在最近试验中具有更高可靠性(即更少误差)的智能体。我们提出了一个用于CRL的框架,即用于多样化DQN集成仲裁控制(ACED-DQN)。实验结果表明,在静态和持续环境中,性能都有显著提高,并且经验证据表明在训练期间对多样化的DQN进行仲裁控制是有效的。这项工作介绍了一个受人脑启发的框架,使RL智能体能够持续学习。
🔬 方法详解
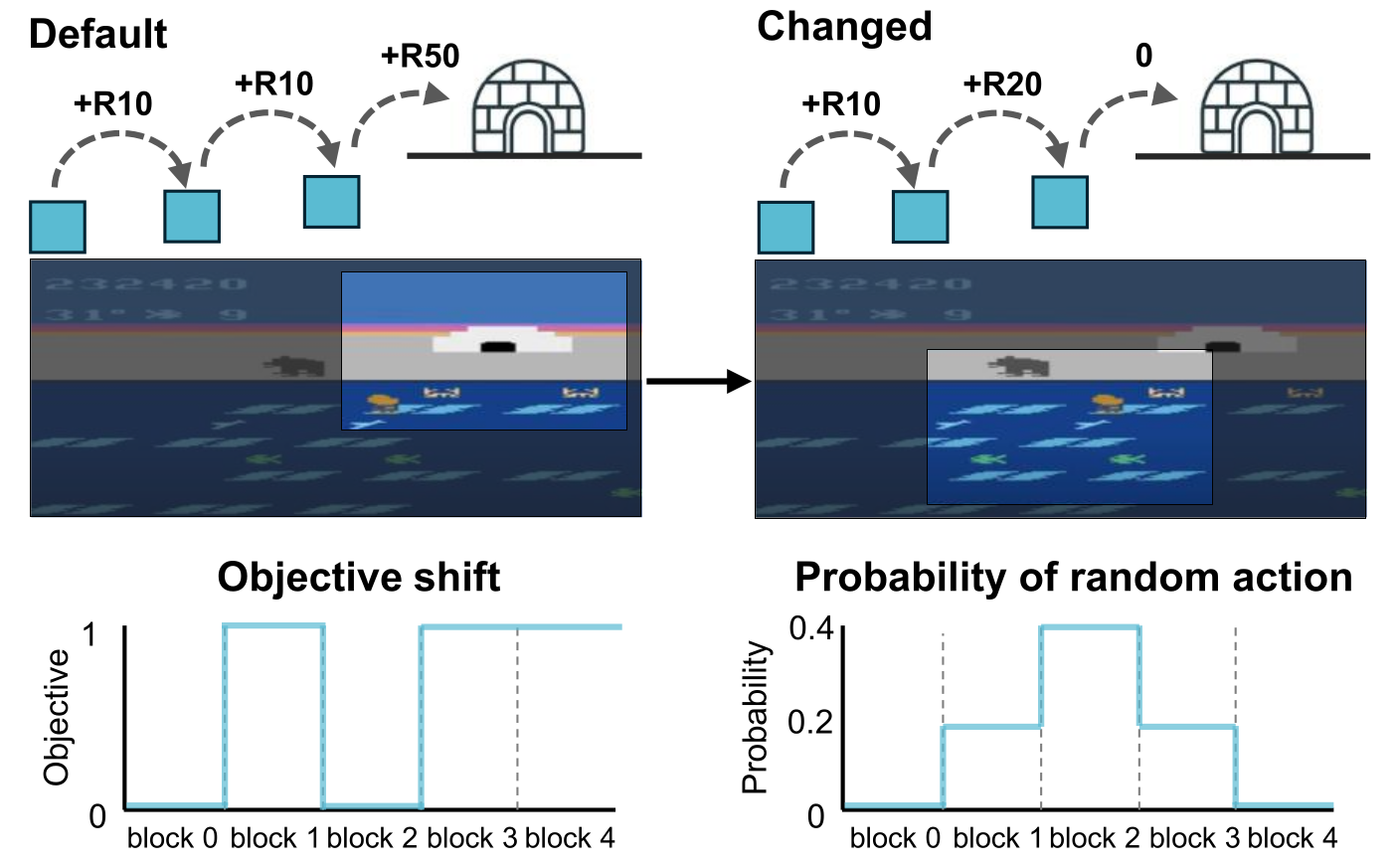
问题定义:论文旨在解决持续强化学习(CRL)中深度强化学习模型面临的灾难性遗忘问题。现有的强化学习模型在静态环境中表现良好,但在持续学习新任务时,会迅速遗忘之前学习的知识,导致性能下降。
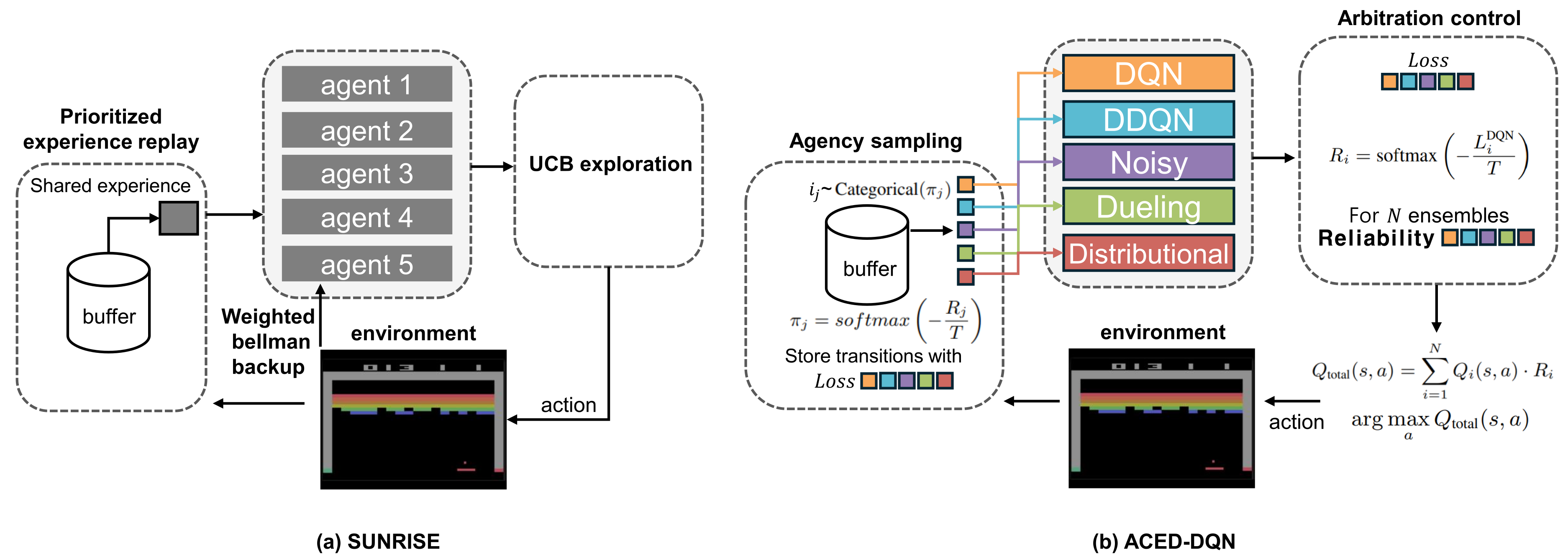
核心思路:论文的核心思路是模仿人类大脑的决策机制,构建一个由多个具有不同价值函数的DQN变体组成的集成,并通过仲裁控制机制来选择最佳策略。这种方法旨在利用不同DQN变体的优势,同时降低灾难性遗忘的风险。
技术框架:ACED-DQN框架包含以下主要模块:1) 多样化的DQN集成:训练多个DQN变体,每个变体具有不同的网络结构或训练参数,以获得多样化的价值函数。2) 仲裁控制机制:根据每个DQN变体在最近试验中的表现(例如,预测误差),计算其可靠性得分。3) 策略选择:根据仲裁控制机制的输出,选择具有最高可靠性得分的DQN变体的策略作为最终策略。
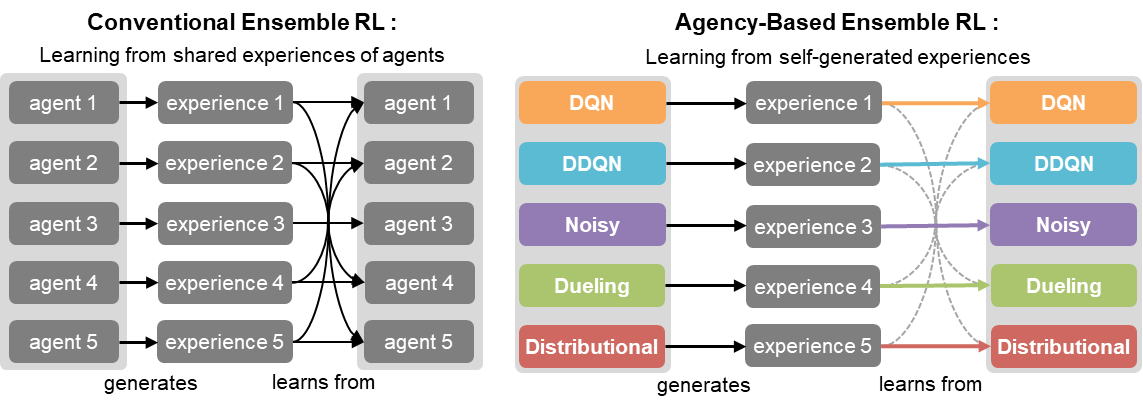
关键创新:该论文的关键创新在于将集成学习和仲裁控制机制相结合,用于解决持续强化学习中的灾难性遗忘问题。与传统的持续学习方法(如正则化或重放缓冲区)不同,ACED-DQN通过显式地训练多样化的DQN变体,并根据其可靠性动态地选择策略,从而更有效地保持和利用先前学习的知识。
关键设计:关键设计包括:1) DQN变体的多样性:可以通过改变网络结构(例如,层数、神经元数量)或训练参数(例如,学习率、探索策略)来实现。2) 可靠性评估:可以使用预测误差(例如,均方误差)作为可靠性指标。3) 仲裁控制机制:可以使用加权平均或门控机制来融合不同DQN变体的策略。4) 损失函数:可以使用标准的DQN损失函数(例如,Temporal Difference误差)来训练每个DQN变体。
🖼️ 关键图片
📊 实验亮点
实验结果表明,ACED-DQN在多个持续强化学习环境中均取得了显著的性能提升。与传统的DQN和一些现有的持续学习方法相比,ACED-DQN能够更有效地保持先前学习的知识,并在新任务上快速学习。具体性能数据未知,但摘要强调了“significant performance improvements”。
🎯 应用场景
该研究成果可应用于机器人、游戏AI、自动驾驶等需要持续学习和适应新环境的领域。例如,机器人可以在不断变化的环境中学习执行不同的任务,自动驾驶系统可以持续学习新的交通规则和驾驶场景。该方法能够提升智能体在复杂和动态环境中的适应性和鲁棒性。
📄 摘要(原文)
Deep reinforcement learning (RL) models, despite their efficiency in learning an optimal policy in static environments, easily loses previously learned knowledge (i.e., catastrophic forgetting). It leads RL models to poor performance in continual reinforcement learning (CRL) scenarios. To address this, we present an arbitration control mechanism over an ensemble of RL agents. It is motivated by and closely aligned with how humans make decisions in a CRL context using an arbitration control of multiple RL agents in parallel as observed in the prefrontal cortex. We integrated two key ideas into our model: (1) an ensemble of RLs (i.e., DQN variants) explicitly trained to have diverse value functions and (2) an arbitration control that prioritizes agents with higher reliability (i.e., less error) in recent trials. We propose a framework for CRL, an Arbitration Control for an Ensemble of Diversified DQN variants (ACED-DQN). We demonstrate significant performance improvements in both static and continual environments, supported by empirical evidence showing the effectiveness of arbitration control over diversified DQNs during training. In this work, we introduced a framework that enables RL agents to continuously learn, with inspiration from the human brain.