Beyond I-Con: Exploring New Dimension of Distance Measures in Representation Learning
作者: Jasmine Shone, Zhening Li, Shaden Alshammari, Mark Hamilton, William Freeman
分类: cs.LG, cs.AI, cs.CV
发布日期: 2025-09-05 (更新: 2025-12-04)
💡 一句话要点
Beyond I-Con:探索表征学习中距离度量的新维度,提升聚类与降维效果
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 表征学习 对比学习 无监督聚类 降维 KL散度 统计散度 损失函数
📋 核心要点
- 现有I-Con框架依赖KL散度进行表征学习,但KL散度的不对称性和无界性可能导致优化困难,影响学习效果。
- Beyond I-Con框架通过探索不同的统计散度,系统性地寻找更适合表征学习的损失函数,优化模型性能。
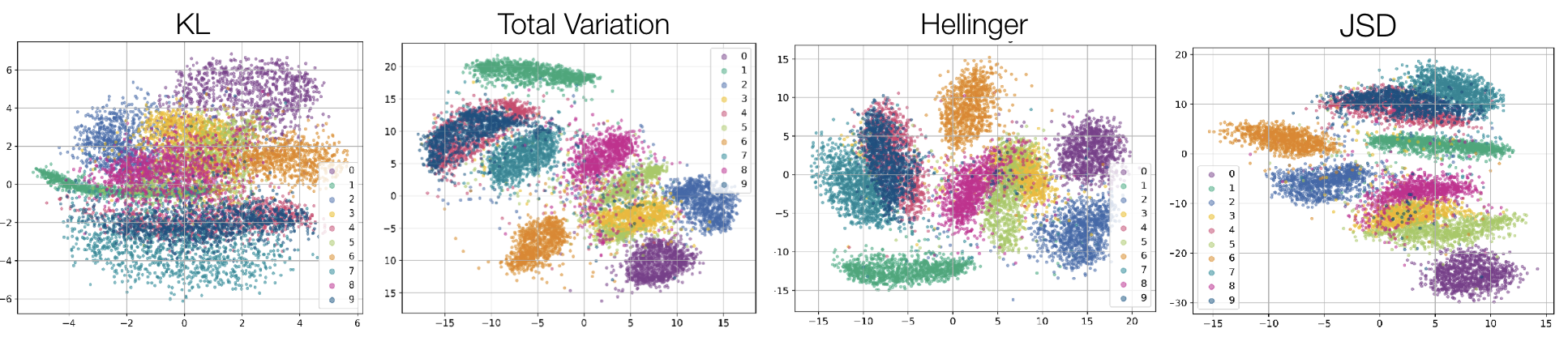
- 实验表明,使用TV距离改进PMI算法,JSD改进监督对比学习,以及有界f-散度替换KL散度,均能显著提升聚类、对比学习和降维效果。
📝 摘要(中文)
Information Contrastive (I-Con) 框架揭示了超过23种表征学习方法隐式地最小化数据分布与学习到的分布之间的KL散度,后者编码了数据点之间的相似性。然而,基于KL的损失可能与真实目标不一致,并且KL散度的非对称性和无界性等特性可能会带来优化挑战。我们提出了 Beyond I-Con,一个通过探索替代统计散度来系统发现新损失函数的框架。主要发现包括:(1)在DINO-ViT嵌入的无监督聚类上,通过修改PMI算法以使用全变差(TV)距离,我们实现了最先进的结果;(2)通过用Jenson-Shannon散度(JSD)替换标准损失函数,改进了以欧几里得距离作为特征空间度量的监督对比学习;(3)在降维方面,通过用有界的$f$-散度替换KL散度,我们实现了优于SNE的定性结果和更好的下游任务性能。我们的结果突出了在表征学习优化中考虑散度选择的重要性。
🔬 方法详解
问题定义:现有表征学习方法,如I-Con框架,大多基于KL散度来衡量数据分布和学习表征之间的差异。然而,KL散度本身的一些性质,例如非对称性和无界性,可能会导致优化过程中的问题,使得学习到的表征并非最优。此外,KL散度可能与实际任务的目标不完全对齐,限制了模型的性能。
核心思路:Beyond I-Con的核心思路是跳出KL散度的限制,探索其他统计散度作为表征学习的损失函数。通过系统性地评估不同散度在不同任务上的表现,寻找更适合特定任务的散度度量。该方法旨在克服KL散度的局限性,并为表征学习提供更灵活和有效的优化策略。
技术框架:Beyond I-Con框架主要包含以下几个阶段:1. 选择不同的统计散度,例如全变差(TV)距离、Jenson-Shannon散度(JSD)和有界的f-散度。2. 将这些散度应用到不同的表征学习任务中,例如无监督聚类、监督对比学习和降维。3. 评估不同散度在各个任务上的性能,并与基于KL散度的传统方法进行比较。4. 分析实验结果,确定哪些散度在哪些任务上表现更好,并解释其原因。
关键创新:该论文的关键创新在于提出了一个通用的框架,用于系统性地探索和评估不同的统计散度在表征学习中的应用。与以往专注于KL散度的研究不同,Beyond I-Con鼓励研究者考虑更广泛的散度选择,并根据具体任务选择最合适的散度度量。这种方法能够发现新的损失函数,并提升表征学习的性能。
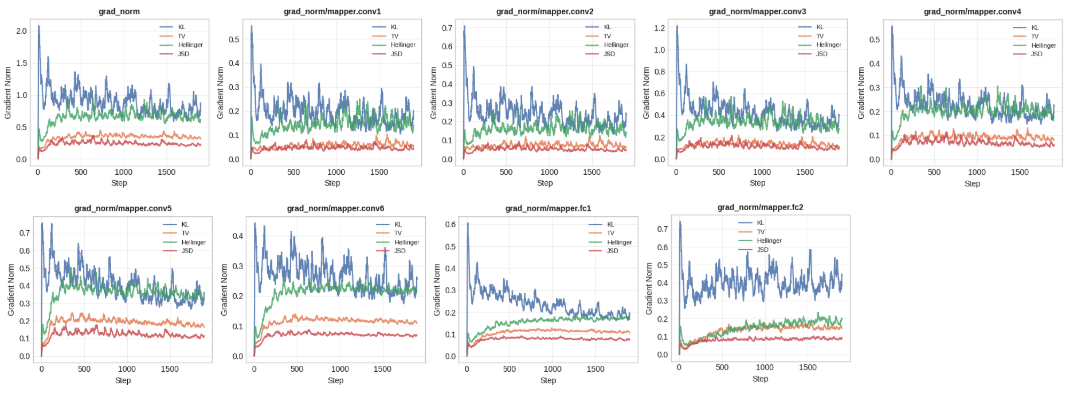
关键设计:论文的关键设计包括:1. 在无监督聚类任务中,使用全变差(TV)距离代替KL散度来修改PMI算法。2. 在监督对比学习中,使用Jenson-Shannon散度(JSD)代替传统的损失函数。3. 在降维任务中,使用有界的f-散度代替KL散度。这些设计旨在利用不同散度的特性来优化特定任务的性能。例如,TV距离的有界性可以避免梯度爆炸问题,而JSD的对称性可能更适合对比学习。
🖼️ 关键图片
📊 实验亮点
实验结果表明,在无监督聚类任务中,使用TV距离改进的PMI算法达到了state-of-the-art的性能。在监督对比学习中,使用JSD代替传统损失函数能够提升模型性能。在降维任务中,使用有界的f-散度代替KL散度,获得了优于SNE的定性结果和更好的下游任务性能。这些结果验证了Beyond I-Con框架的有效性。
🎯 应用场景
该研究成果可广泛应用于计算机视觉、自然语言处理等领域,提升图像分类、文本聚类、语义表示等任务的性能。通过选择合适的散度度量,可以优化模型的表征能力,提高下游任务的准确性和鲁棒性。未来,该框架可进一步扩展到更多表征学习任务和领域。
📄 摘要(原文)
The Information Contrastive (I-Con) framework revealed that over 23 representation learning methods implicitly minimize KL divergence between data and learned distributions that encode similarities between data points. However, a KL-based loss may be misaligned with the true objective, and properties of KL divergence such as asymmetry and unboundedness may create optimization challenges. We present Beyond I-Con, a framework that enables systematic discovery of novel loss functions by exploring alternative statistical divergences. Key findings: (1) on unsupervised clustering of DINO-ViT embeddings, we achieve state-of-the-art results by modifying the PMI algorithm to use total variation (TV) distance; (2) supervised contrastive learning with Euclidean distance as the feature space metric is improved by replacing the standard loss function with Jenson-Shannon divergence (JSD); (3) on dimensionality reduction, we achieve superior qualitative results and better performance on downstream tasks than SNE by replacing KL with a bounded $f$-divergence. Our results highlight the importance of considering divergence choices in representation learning optimization.