Delta Activations: A Representation for Finetuned Large Language Models
作者: Zhiqiu Xu, Amish Sethi, Mayur Naik, Ser-Nam Lim
分类: cs.LG, cs.AI, cs.CL, cs.IR
发布日期: 2025-09-04
🔗 代码/项目: GITHUB
💡 一句话要点
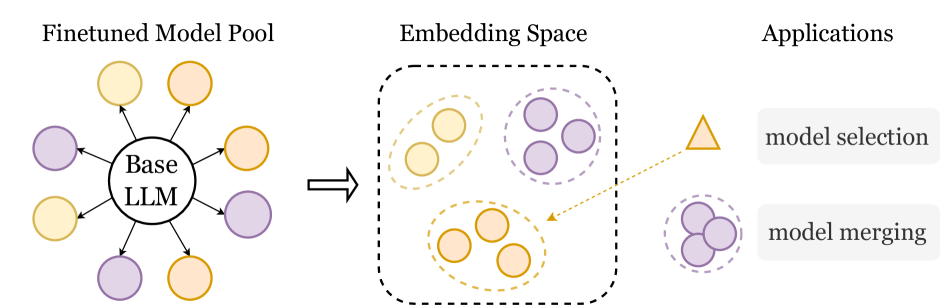
提出Delta Activations,通过激活值变化表征微调LLM,实现模型聚类、选择与合并。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 微调模型 模型表示 激活值 模型聚类 模型选择 模型合并
📋 核心要点
- 现有微调LLM模型库缺乏统一的表示方法,难以有效组织和理解大量模型。
- Delta Activations通过计算微调前后模型内部激活值的差异,将模型表示为向量嵌入。
- 实验表明,该方法在模型聚类、选择和合并方面表现良好,并具有鲁棒性和可加性。
📝 摘要(中文)
大型语言模型(LLM)的开源成功使得社区能够创建大量针对特定任务和领域进行后训练的模型。然而,由于元数据不一致和存储库结构化程度低,导航和理解这些模型仍然具有挑战性。本文提出Delta Activations,一种通过测量微调模型相对于基础模型内部激活值的变化,将其表示为向量嵌入的方法。这种表示能够有效地按领域和任务进行聚类,从而揭示模型格局的结构。Delta Activations还表现出理想的特性:它在不同的微调设置中具有鲁棒性,并且在混合微调数据集时表现出可加性。此外,本文还展示了Delta Activations可以通过少样本微调嵌入任务,并进一步探索其在模型选择和合并中的应用。我们希望Delta Activations能够促进公开可用模型的重用。
🔬 方法详解
问题定义:现有的大型语言模型微调后,产生了大量的模型变体,这些模型针对不同的任务和领域进行了优化。然而,由于缺乏统一的表示方法,难以有效地组织、搜索和理解这些模型。现有的元数据往往不一致,存储库结构化程度低,给模型的重用和组合带来了挑战。
核心思路:论文的核心思路是通过捕捉微调前后模型内部激活值的变化来表征微调后的模型。这种变化反映了模型在特定任务或领域上的适应程度。通过将这些变化表示为向量嵌入,可以利用向量空间中的距离度量来衡量模型之间的相似性,从而实现模型的聚类、选择和合并。
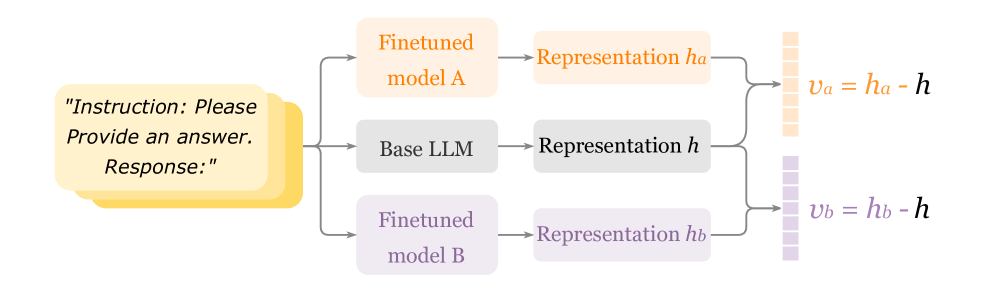
技术框架:Delta Activations 的整体框架包括以下几个步骤:1) 选择一个基础模型(Base Model);2) 对基础模型进行微调,得到微调后的模型(Finetuned Model);3) 选取模型中的若干层(例如 Transformer 层的输出);4) 对于给定的输入,分别计算基础模型和微调模型在这些层上的激活值;5) 计算激活值之间的差异(Delta),并将其向量化,得到 Delta Activations 向量。
关键创新:该方法的核心创新在于使用模型内部激活值的变化来表征微调后的模型。与传统的基于模型参数的表示方法相比,Delta Activations 能够更好地捕捉模型在特定任务上的行为变化。此外,Delta Activations 还具有可加性,这意味着可以将多个任务的 Delta Activations 向量进行组合,从而得到一个能够同时处理多个任务的模型表示。
关键设计:在计算激活值差异时,可以使用不同的距离度量方法,例如欧氏距离或余弦相似度。论文中还探讨了不同层的激活值对 Delta Activations 向量的影响,并发现某些层的激活值能够更好地反映模型的行为变化。此外,论文还研究了如何选择合适的输入来计算激活值,以获得更具代表性的 Delta Activations 向量。
🖼️ 关键图片
📊 实验亮点
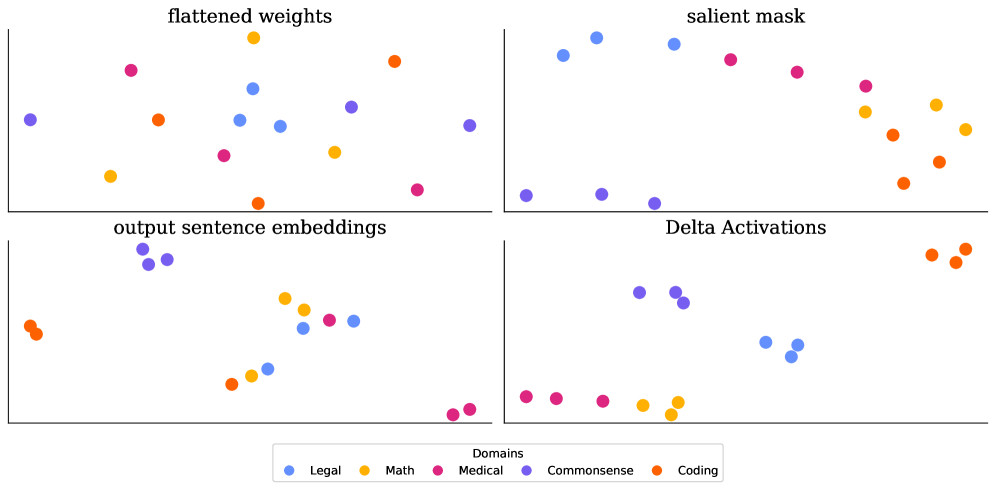
实验结果表明,Delta Activations 能够有效地对微调模型进行聚类,区分不同领域和任务的模型。通过 Delta Activations,可以使用少量样本进行任务嵌入,并用于模型选择。此外,Delta Activations 还表现出良好的可加性,可以用于模型合并。例如,通过混合两个数据集进行微调,得到的 Delta Activations 向量与分别在两个数据集上微调得到的 Delta Activations 向量之和近似。
🎯 应用场景
Delta Activations 可用于构建模型推荐系统,根据用户需求推荐合适的微调模型。它还可用于模型融合,将多个模型的优点结合起来,构建性能更强的模型。此外,该方法还有助于理解模型微调过程,分析不同微调策略对模型行为的影响,从而指导模型训练。
📄 摘要(原文)
The success of powerful open source Large Language Models (LLMs) has enabled the community to create a vast collection of post-trained models adapted to specific tasks and domains. However, navigating and understanding these models remains challenging due to inconsistent metadata and unstructured repositories. We introduce Delta Activations, a method to represent finetuned models as vector embeddings by measuring shifts in their internal activations relative to a base model. This representation allows for effective clustering by domain and task, revealing structure in the model landscape. Delta Activations also demonstrate desirable properties: it is robust across finetuning settings and exhibits an additive property when finetuning datasets are mixed. In addition, we show that Delta Activations can embed tasks via few-shot finetuning, and further explore its use for model selection and merging. We hope Delta Activations can facilitate the practice of reusing publicly available models. Code is available at https://github.com/OscarXZQ/delta_activations.