Towards a Unified View of Large Language Model Post-Training
作者: Xingtai Lv, Yuxin Zuo, Youbang Sun, Hongyi Liu, Yuntian Wei, Zhekai Chen, Xuekai Zhu, Kaiyan Zhang, Bingning Wang, Ning Ding, Bowen Zhou
分类: cs.LG, cs.AI, cs.CL
发布日期: 2025-09-04 (更新: 2026-01-20)
💡 一句话要点
统一大语言模型后训练视角,提出混合后训练算法HPT,提升数学推理能力。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 后训练 强化学习 监督微调 策略梯度 数学推理 混合训练
📋 核心要点
- 现有后训练方法依赖于在线或离线数据,缺乏统一视角,导致训练策略选择困难。
- 论文提出统一策略梯度估计器,将不同后训练方法视为同一目标函数的不同梯度估计。
- 提出的混合后训练(HPT)算法,动态选择训练信号,在数学推理任务上超越现有方法。
📝 摘要(中文)
现代语言模型的后训练通常使用两种主要的数据来源:在线数据(模型生成的样本)和离线数据(人类或其他模型提供的示范)。这两种数据分别被强化学习(RL)和监督微调(SFT)等方法使用。本文表明,这些方法并非相互矛盾,而是同一优化过程的不同实例。我们推导出一个统一的策略梯度估计器,并将各种后训练方法的计算表示为在不同数据分布假设和各种偏差-方差权衡下,一个共同目标的梯度。该梯度估计器由四个可互换的部分构成:稳定掩码、参考策略分母、优势估计和似然梯度。受理论发现的启发,我们提出了混合后训练(HPT),一种动态选择不同训练信号的算法。HPT旨在有效利用示范数据并实现稳定的探索,同时不牺牲已学习的推理模式。我们进行了广泛的实验和消融研究,以验证我们统一理论框架和HPT的有效性。在六个数学推理基准和两个分布外测试集上,HPT始终优于各种规模和系列的强大基线模型。
🔬 方法详解
问题定义:现有的大语言模型后训练方法通常依赖于两种不同的数据来源:模型生成的在线数据和人工或其它模型提供的离线数据。强化学习(RL)和监督微调(SFT)是分别利用这两种数据的典型方法。然而,这些方法通常被视为独立的训练范式,缺乏一个统一的理论框架来理解它们之间的关系,以及如何有效地结合利用这两种数据。这导致在实际应用中,选择合适的后训练策略变得困难,并且可能无法充分利用不同数据的优势。
核心思路:本文的核心思路是将不同的后训练方法视为同一优化目标的不同实现方式。具体来说,作者推导了一个统一的策略梯度估计器,该估计器可以涵盖包括RL和SFT在内的多种后训练方法。通过分析不同方法在数据分布假设和偏差-方差权衡上的差异,作者揭示了它们之间的内在联系。这种统一的视角为设计更有效的后训练算法提供了理论基础。
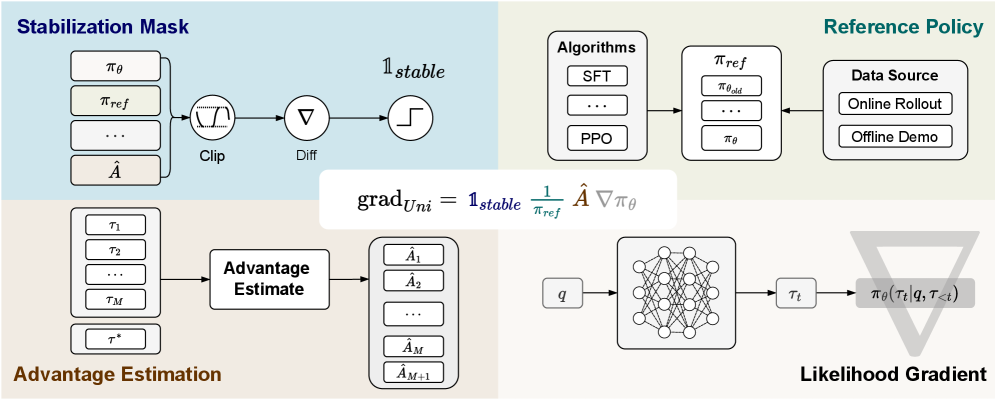
技术框架:论文提出的统一框架的核心是统一策略梯度估计器。该估计器由四个可互换的部分组成:稳定掩码(Stabilization Mask)、参考策略分母(Reference Policy Denominator)、优势估计(Advantage Estimate)和似然梯度(Likelihood Gradient)。不同的后训练方法可以通过选择不同的组件来实现。基于此框架,作者提出了混合后训练(HPT)算法,该算法动态地选择不同的训练信号,以平衡利用示范数据和进行稳定探索。HPT算法的具体流程包括:首先,使用离线数据进行初始化训练;然后,在训练过程中,根据一定的策略动态地选择使用在线或离线数据进行更新。
关键创新:论文最重要的技术创新在于提出了统一的策略梯度估计器,它将不同的后训练方法纳入一个统一的理论框架。这个框架不仅揭示了不同方法之间的联系,还为设计新的后训练算法提供了指导。此外,提出的HPT算法能够动态地选择训练信号,从而在利用示范数据和进行稳定探索之间取得平衡,避免了传统方法中可能出现的过拟合或训练不稳定问题。
关键设计:HPT算法的关键设计在于如何动态地选择训练信号。具体来说,作者使用一个可学习的权重来控制在线和离线数据的比例。这个权重可以根据训练过程中的性能指标进行调整,例如,当模型在验证集上的性能下降时,可以增加离线数据的比例,以防止过拟合。此外,作者还设计了一种稳定掩码,用于控制梯度更新的幅度,以避免训练不稳定。损失函数的设计也至关重要,它需要能够反映在线和离线数据的不同特点,并能够有效地引导模型学习。
🖼️ 关键图片
📊 实验亮点
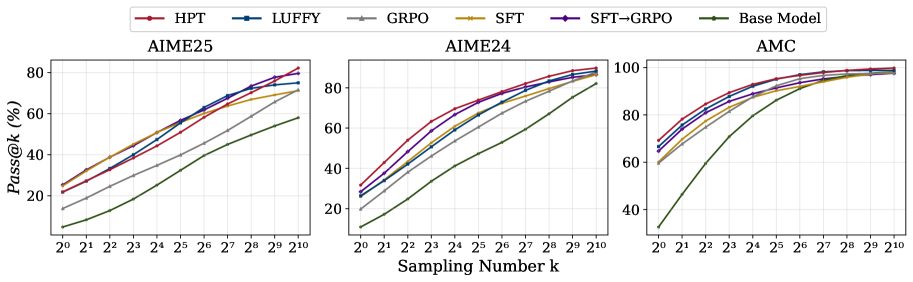
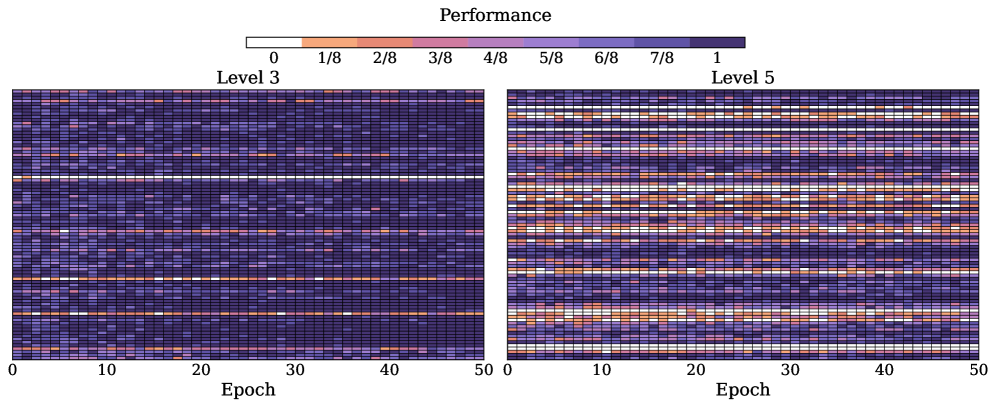
实验结果表明,HPT算法在六个数学推理基准和两个分布外测试集上均优于强大的基线模型。具体来说,HPT在GSM8K数据集上取得了显著的性能提升,超过了现有SOTA模型。消融实验验证了统一理论框架和HPT算法中各个组件的有效性,证明了动态选择训练信号的优势。
🎯 应用场景
该研究成果可广泛应用于大语言模型的后训练,尤其是在需要提升模型推理能力和泛化能力的场景中。例如,可以用于提升模型在数学、逻辑推理等方面的表现,也可以用于提高模型在特定领域的专业知识水平。此外,该方法还可以应用于机器人控制、对话系统等领域,提升智能体的决策能力和交互能力。
📄 摘要(原文)
Two major sources of training data exist for post-training modern language models: online (model-generated rollouts) data, and offline (human or other-model demonstrations) data. These two types of data are typically used by approaches like Reinforcement Learning (RL) and Supervised Fine-Tuning (SFT), respectively. In this paper, we show that these approaches are not in contradiction, but are instances of a single optimization process. We derive a Unified Policy Gradient Estimator, and present the calculations of a wide spectrum of post-training approaches as the gradient of a common objective under different data distribution assumptions and various bias-variance tradeoffs. The gradient estimator is constructed with four interchangeable parts: stabilization mask, reference policy denominator, advantage estimate, and likelihood gradient. Motivated by our theoretical findings, we propose Hybrid Post-Training (HPT), an algorithm that dynamically selects different training signals. HPT is designed to yield both effective exploitation of demonstration and stable exploration without sacrificing learned reasoning patterns. We provide extensive experiments and ablation studies to verify the effectiveness of our unified theoretical framework and HPT. Across six mathematical reasoning benchmarks and two out-of-distribution suites, HPT consistently surpasses strong baselines across models of varying scales and families.