IPA: An Information-Reconstructive Input Projection Framework for Efficient Foundation Model Adaptation
作者: Yuan Yin, Shashanka Venkataramanan, Tuan-Hung Vu, Andrei Bursuc, Matthieu Cord
分类: cs.LG, cs.AI
发布日期: 2025-09-04 (更新: 2026-01-06)
备注: Accepted to TMLR
🔗 代码/项目: GITHUB
💡 一句话要点
提出IPA:一种信息重构的输入投影框架,用于高效地适应基础模型
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 参数高效微调 低秩适应 信息重构 特征感知投影 基础模型 迁移学习 模型压缩
📋 核心要点
- LoRA等PEFT方法虽然降低了微调成本,但其随机初始化的下投影会丢失信息,成为性能瓶颈。
- IPA通过特征感知的投影,在降维空间中重建原始输入,从而保留更多信息,提升微调效果。
- 实验表明,IPA在语言和视觉任务上均优于LoRA,且在参数量减半的情况下可匹配LoRA性能。
📝 摘要(中文)
参数高效微调(PEFT)方法,如LoRA,通过将低秩更新注入到预训练权重中来降低适应成本。然而,LoRA的下投影是随机初始化且数据无关的,丢弃了潜在的有用信息。先前的分析表明,这种投影在训练过程中变化很小,而上投影承担了大部分的适应,使得随机输入压缩成为性能瓶颈。我们提出了IPA,一个特征感知的投影框架,它明确地旨在在缩减的隐藏空间内重建原始输入。在线性情况下,我们使用近似于顶部主成分的算法来实例化IPA,从而能够以可忽略的推理开销进行高效的投影器预训练。在语言和视觉基准测试中,IPA始终优于LoRA和DoRA,在常识推理方面平均提高了1.5个百分点,在VTAB-1k上提高了2.3个百分点,同时在投影冻结时,以大约一半的可训练参数匹配了完整LoRA的性能。
🔬 方法详解
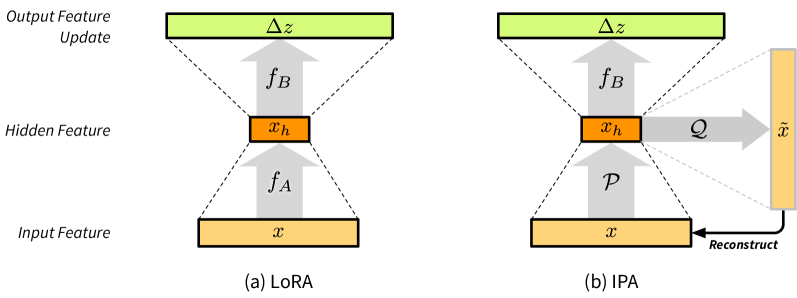
问题定义:论文旨在解决参数高效微调(PEFT)方法中,如LoRA,由于其随机初始化的下投影导致的信息损失问题。LoRA的下投影是数据无关的,并且在训练过程中变化很小,限制了模型的性能。
核心思路:论文的核心思路是设计一种特征感知的投影框架IPA,该框架明确地旨在在缩减的隐藏空间内重建原始输入。通过在投影过程中保留更多信息,IPA能够更有效地适应预训练模型。
技术框架:IPA框架主要包含一个输入投影模块,该模块将原始输入投影到一个低维空间,并尽可能地保留原始输入的信息。在线性情况下,该模块可以使用近似于顶部主成分的算法来实现。整个框架可以与现有的PEFT方法(如LoRA)结合使用,替换其随机初始化的下投影。
关键创新:IPA的关键创新在于其特征感知的投影方法,它不是随机地进行降维,而是有目的地保留输入信息。通过显式地重建原始输入,IPA能够更好地利用预训练模型的知识,并提高微调的效率和性能。与LoRA相比,IPA的投影矩阵是经过预训练的,而不是随机初始化的。
关键设计:IPA的关键设计包括:1) 使用近似于顶部主成分的算法进行投影器预训练,以保证高效的信息重建;2) 在线性情况下,可以使用SVD等方法来计算投影矩阵;3) 可以将IPA的投影层冻结,以进一步减少可训练参数的数量,同时保持性能。
🖼️ 关键图片


📊 实验亮点
实验结果表明,IPA在常识推理任务上平均比LoRA提高了1.5个百分点,在VTAB-1k视觉基准测试上提高了2.3个百分点。更重要的是,当IPA的投影层被冻结时,它仅使用大约一半的可训练参数就能达到与完整LoRA相当的性能,显著提高了参数效率。
🎯 应用场景
IPA框架可广泛应用于各种需要高效微调基础模型的场景,例如自然语言处理中的文本分类、情感分析,以及计算机视觉中的图像识别、目标检测等。该方法能够降低微调成本,提高模型性能,并加速模型部署。尤其适用于资源受限的边缘设备或需要快速迭代的开发环境。
📄 摘要(原文)
Parameter-efficient fine-tuning (PEFT) methods, such as LoRA, reduce adaptation cost by injecting low-rank updates into pretrained weights. However, LoRA's down-projection is randomly initialized and data-agnostic, discarding potentially useful information. Prior analyses show that this projection changes little during training, while the up-projection carries most of the adaptation, making the random input compression a performance bottleneck. We propose IPA, a feature-aware projection framework that explicitly aims to reconstruct the original input within a reduced hidden space. In the linear case, we instantiate IPA with algorithms approximating top principal components, enabling efficient projector pretraining with negligible inference overhead. Across language and vision benchmarks, IPA consistently improves over LoRA and DoRA, achieving on average 1.5 points higher accuracy on commonsense reasoning and 2.3 points on VTAB-1k, while matching full LoRA performance with roughly half the trainable parameters when the projection is frozen. Code available at https://github.com/valeoai/peft-ipa .