PagedEviction: Structured Block-wise KV Cache Pruning for Efficient Large Language Model Inference
作者: Krishna Teja Chitty-Venkata, Jie Ye, Xian-He Sun, Anthony Kougkas, Murali Emani, Venkatram Vishwanath, Bogdan Nicolae
分类: cs.LG
发布日期: 2025-09-04
备注: Preprint
💡 一句话要点
PagedEviction:用于高效大语言模型推理的结构化块级KV缓存剪枝
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 KV缓存 内存管理 PagedAttention 推理优化 长文本处理 块级剪枝
📋 核心要点
- 现有LLM推理中,KV缓存随序列长度增加迅速成为内存瓶颈,限制了长文本处理能力。
- PagedEviction提出一种细粒度、结构化的KV缓存剪枝策略,优化vLLM的PagedAttention。
- 实验表明,PagedEviction在长文本任务中,相比基线方法,提升了内存利用率并提高了准确性。
📝 摘要(中文)
KV缓存通过存储先前处理的token的注意力状态,显著提高了大语言模型(LLM)推理的效率,从而能够更快地生成后续token。然而,随着序列长度的增加,KV缓存迅速成为主要的内存瓶颈。为了解决这个问题,我们提出了PagedEviction,一种新颖的细粒度、结构化的KV缓存剪枝策略,它增强了vLLM的PagedAttention的内存效率。与依赖于基于注意力的token重要性或跨不同vLLM页面驱逐token的现有方法不同,PagedEviction引入了一种专为分页内存布局量身定制的高效块级驱逐算法。我们的方法与PagedAttention无缝集成,无需对其CUDA注意力内核进行任何修改。我们在LongBench基准测试套件上评估了Llama-3.1-8B-Instruct、Llama-3.2-1B-Instruct和Llama-3.2-3B-Instruct模型上的PagedEviction,证明了在长上下文任务中,与基线相比,提高了内存使用率并具有更好的准确性。
🔬 方法详解
问题定义:大语言模型推理过程中,KV缓存会随着序列长度的增加而迅速占用大量内存,成为性能瓶颈。现有的KV缓存管理方法,例如基于注意力权重的token重要性评估或跨页面的token驱逐,存在效率不高或与现有PagedAttention架构不兼容的问题。
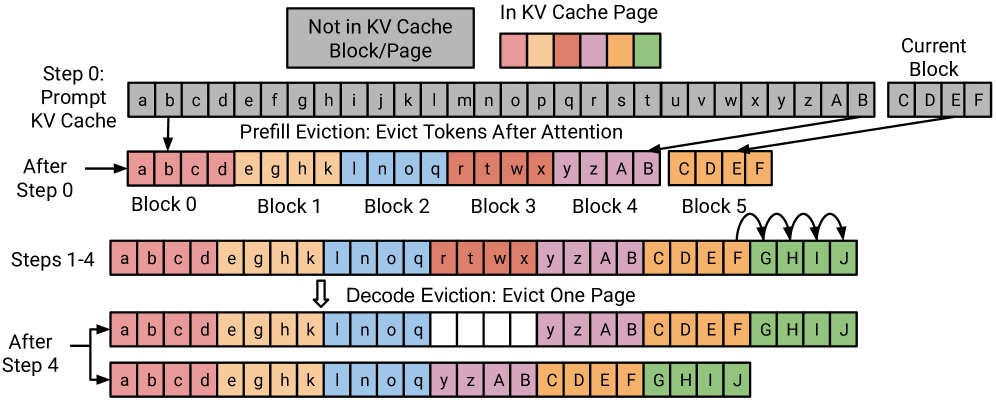
核心思路:PagedEviction的核心思路是利用PagedAttention的分页内存布局,设计一种高效的块级驱逐算法。通过在页面内部进行细粒度的块级剪枝,可以在不修改底层CUDA内核的情况下,更有效地管理KV缓存,从而提高内存利用率和推理效率。
技术框架:PagedEviction与vLLM的PagedAttention框架无缝集成。它主要包含一个块级驱逐算法,该算法根据预定义的策略(例如,最少使用原则)选择要驱逐的块。该算法在页面内部操作,避免了跨页面的数据移动,从而提高了效率。整个流程包括:接收新的token请求,检查KV缓存容量,如果容量不足,则执行块级驱逐,然后将新的token添加到KV缓存中。
关键创新:PagedEviction的关键创新在于其细粒度的块级驱逐策略,以及与PagedAttention的无缝集成。与传统的token级驱逐相比,块级驱逐可以减少元数据管理开销。与跨页面驱逐相比,页面内部的块级驱逐避免了数据移动,从而提高了效率。此外,PagedEviction不需要修改PagedAttention的CUDA内核,降低了集成难度。
关键设计:PagedEviction的关键设计包括块大小的选择和驱逐策略的制定。块大小需要根据硬件特性和模型大小进行调整,以达到最佳的内存利用率和性能。驱逐策略可以采用多种方法,例如最少使用(LRU)、最近最少使用(LFU)等。论文中可能还涉及一些参数用于控制驱逐的频率和数量,以平衡内存利用率和推理准确性。
🖼️ 关键图片

📊 实验亮点
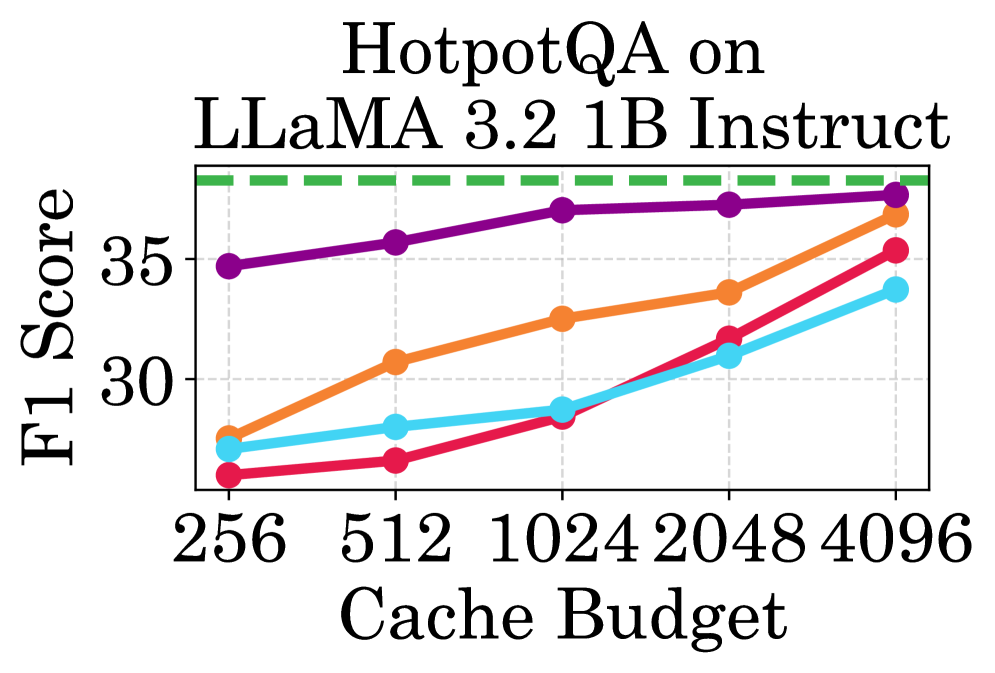
实验结果表明,PagedEviction在Llama-3系列模型(包括Llama-3.1-8B-Instruct、Llama-3.2-1B-Instruct和Llama-3.2-3B-Instruct)上,使用LongBench基准测试套件进行了评估,与现有基线方法相比,PagedEviction在长文本任务中实现了更高的内存利用率和更好的准确性。具体的性能提升数据(例如,内存占用减少百分比、准确率提升百分比)需要在论文中查找。
🎯 应用场景
PagedEviction技术可广泛应用于需要处理长文本的大语言模型推理场景,例如长篇文档摘要、代码生成、对话系统等。通过提高内存利用率,该技术可以支持更大规模的模型和更长的上下文长度,从而提升LLM在复杂任务中的性能。此外,该技术还可以降低部署成本,使得在资源受限的设备上运行大型语言模型成为可能。
📄 摘要(原文)
KV caching significantly improves the efficiency of Large Language Model (LLM) inference by storing attention states from previously processed tokens, enabling faster generation of subsequent tokens. However, as sequence length increases, the KV cache quickly becomes a major memory bottleneck. To address this, we propose PagedEviction, a novel fine-grained, structured KV cache pruning strategy that enhances the memory efficiency of vLLM's PagedAttention. Unlike existing approaches that rely on attention-based token importance or evict tokens across different vLLM pages, PagedEviction introduces an efficient block-wise eviction algorithm tailored for paged memory layouts. Our method integrates seamlessly with PagedAttention without requiring any modifications to its CUDA attention kernels. We evaluate PagedEviction across Llama-3.1-8B-Instruct, Llama-3.2-1B-Instruct, and Llama-3.2-3B-Instruct models on the LongBench benchmark suite, demonstrating improved memory usage with better accuracy than baselines on long context tasks.