RL's Razor: Why Online Reinforcement Learning Forgets Less
作者: Idan Shenfeld, Jyothish Pari, Pulkit Agrawal
分类: cs.LG
发布日期: 2025-09-04
💡 一句话要点
揭示RL微调优于SFT的原因:在线强化学习具备更少的遗忘性
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 强化学习 微调 灾难性遗忘 知识保留 KL散度
📋 核心要点
- 现有微调方法(如SFT)在适应新任务时,容易过度拟合导致灾难性遗忘,丢失原有能力。
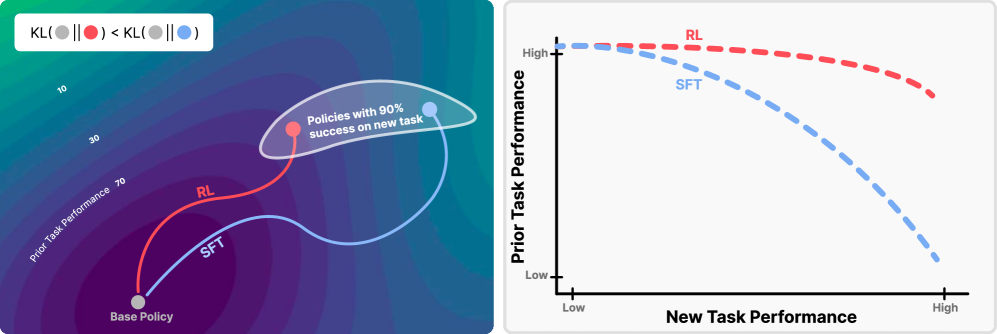
- 论文提出“RL的剃刀”原则,即在线RL倾向于选择与原始模型KL散度最小的策略,从而减少遗忘。
- 实验表明,RL微调在保持原有知识方面优于SFT,并通过理论分析验证了这一现象。
📝 摘要(中文)
本研究对比了使用强化学习(RL)和监督微调(SFT)对模型进行微调的结果,发现尽管两者在新任务上的表现相似,但RL在保留先验知识和能力方面明显更胜一筹。研究表明,遗忘程度取决于分布偏移,具体表现为在新任务上评估的微调策略与基础策略之间的KL散度。分析揭示,在线RL隐式地偏向于KL散度最小的解,而SFT可能收敛到与基础模型相距甚远的分布。通过大型语言模型和机器人基础模型的实验验证了这些发现,并提供了理论依据来解释为什么在线RL更新会导致更小的KL变化。我们将此原则称为“RL的剃刀”:在所有解决新任务的方法中,RL偏好于KL散度上最接近原始模型的方法。
🔬 方法详解
问题定义:论文旨在解决模型在微调过程中出现的灾难性遗忘问题。现有监督微调(SFT)方法虽然能使模型快速适应新任务,但往往会过度拟合新数据,导致模型忘记之前学习到的知识和能力。这种遗忘现象限制了模型在实际应用中的泛化能力和持续学习能力。
核心思路:论文的核心思路是,在线强化学习(RL)在微调过程中,由于其固有的探索机制和奖励机制,能够隐式地约束微调后的策略与原始策略之间的分布差异。具体来说,RL的目标是最大化累积奖励,这促使RL算法在探索新策略的同时,尽量保持与原始策略的相似性,从而减少遗忘。
技术框架:论文的技术框架主要包括以下几个部分:1) 使用RL或SFT对预训练模型进行微调;2) 在新任务上评估微调后模型的性能;3) 测量微调后策略与原始策略之间的KL散度,作为遗忘程度的指标;4) 通过实验和理论分析,验证RL微调在减少遗忘方面的优势。
关键创新:论文最重要的技术创新点在于提出了“RL的剃刀”原则,即在线RL倾向于选择与原始模型KL散度最小的策略。这一原则揭示了RL在微调过程中减少遗忘的内在机制,为设计更有效的微调算法提供了理论指导。与SFT相比,RL通过在线探索和奖励机制,避免了过度拟合新数据,从而更好地保留了原始模型的知识和能力。
关键设计:论文的关键设计包括:1) 使用KL散度作为衡量遗忘程度的指标;2) 设计合适的奖励函数,鼓励模型在新任务上取得良好表现的同时,保持与原始策略的相似性;3) 选择合适的RL算法(如PPO),进行在线策略优化;4) 在大型语言模型和机器人基础模型上进行实验,验证理论分析的有效性。
🖼️ 关键图片

📊 实验亮点
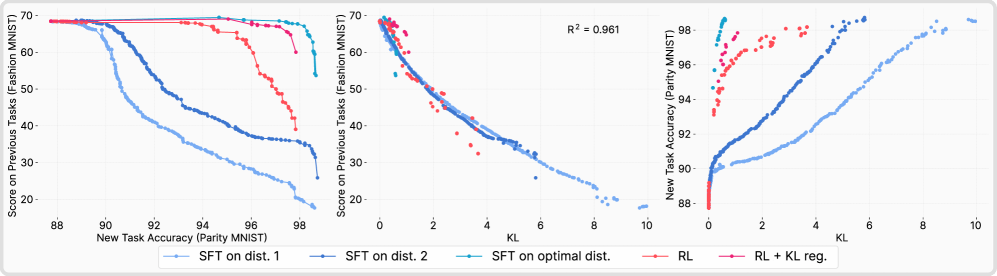
实验结果表明,在大型语言模型和机器人基础模型上,使用RL进行微调的模型在保留原有知识方面明显优于使用SFT进行微调的模型。具体来说,RL微调后的模型在原始任务上的性能下降更小,同时在新任务上的性能与SFT微调后的模型相当。这验证了“RL的剃刀”原则的有效性。
🎯 应用场景
该研究成果可应用于各种需要持续学习和知识迁移的场景,例如:机器人控制、自然语言处理、对话系统等。通过使用RL进行微调,可以使模型在适应新任务的同时,更好地保留原有知识和能力,从而提高模型的泛化能力和鲁棒性。这对于开发能够适应复杂多变环境的智能系统具有重要意义。
📄 摘要(原文)
Comparison of fine-tuning models with reinforcement learning (RL) and supervised fine-tuning (SFT) reveals that, despite similar performance at a new task, RL preserves prior knowledge and capabilities significantly better. We find that the degree of forgetting is determined by the distributional shift, measured as the KL-divergence between the fine-tuned and base policy evaluated on the new task. Our analysis reveals that on-policy RL is implicitly biased towards KL-minimal solutions among the many that solve the new task, whereas SFT can converge to distributions arbitrarily far from the base model. We validate these findings through experiments with large language models and robotic foundation models and further provide theoretical justification for why on-policy RL updates lead to a smaller KL change. We term this principle $\textit{RL's Razor}$: among all ways to solve a new task, RL prefers those closest in KL to the original model.