A Service-Oriented Adaptive Hierarchical Incentive Mechanism for Federated Learning
作者: Jiaxing Cao, Yuzhou Gao, Jiwei Huang
分类: cs.LG, cs.GT, eess.SY
发布日期: 2025-09-03
备注: Accepted at CollaborateCom 2025
💡 一句话要点
提出面向服务的自适应分层激励机制,解决联邦学习中数据匮乏问题。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 联邦学习 激励机制 Stackelberg博弈 多智能体强化学习 深度强化学习
📋 核心要点
- 联邦学习面临数据匮乏的挑战,影响模型训练效果,需要激励机制吸引更多数据贡献者。
- 论文提出一种自适应分层激励机制,通过Stackelberg博弈和多智能体强化学习优化各方效用。
- 实验验证了该机制的有效性,能够稳定参与者策略并提升整体联邦学习系统的性能。
📝 摘要(中文)
本文针对联邦学习(FL)中训练数据不足的问题,提出了一种面向服务的自适应激励机制,旨在最大化任务发布者(TP)、本地模型所有者(LMO)和数据收集者(workers)的效用。具体而言,论文在LMO和TP之间建立了一个Stackelberg博弈模型,TP作为领导者,LMO作为跟随者,并推导出解析纳什均衡解以最大化他们的效用。LMO和workers之间的交互被建模为一个多智能体马尔可夫决策过程(MAMDP),并通过深度强化学习(DRL)确定最优策略。此外,设计了一种自适应搜索最优策略算法(ASOSA)来稳定每个参与者的策略并解决耦合问题。大量的数值实验验证了所提出方法的有效性。
🔬 方法详解
问题定义:联邦学习中,任务发布者(TP)需要训练模型,但本地模型所有者(LMO)的数据可能不足,导致模型性能受限。因此,需要招募workers来收集数据。现有激励机制可能无法有效平衡TP、LMO和workers的利益,导致数据贡献不足或资源浪费。
核心思路:论文的核心思路是从服务导向的角度出发,设计一种自适应的分层激励机制。通过博弈论和强化学习,分别优化TP与LMO之间以及LMO与workers之间的交互,从而最大化所有参与者的效用。这种分层结构能够更精细地控制激励策略,提高资源利用率。
技术框架:整体框架包含三个主要角色:TP、LMO和workers。TP首先发布任务并设定初始奖励。LMO作为中间层,一方面向TP竞标任务,另一方面招募workers收集数据。workers根据LMO提供的奖励决定是否参与数据收集。TP和LMO之间的交互通过Stackelberg博弈建模,LMO和workers之间的交互通过多智能体马尔可夫决策过程(MAMDP)建模。
关键创新:论文的关键创新在于将Stackelberg博弈和多智能体强化学习相结合,构建了一个分层的激励机制。Stackelberg博弈用于优化TP和LMO之间的奖励分配,而MAMDP用于优化LMO和workers之间的激励策略。此外,论文还提出了自适应搜索最优策略算法(ASOSA),用于稳定参与者的策略并解决耦合问题。
关键设计:在Stackelberg博弈中,TP的目标是最大化自身效用,LMO的目标是最大化自身利润。通过求解纳什均衡,可以得到最优的奖励分配方案。在MAMDP中,每个worker都是一个智能体,其目标是最大化自身收益。使用深度强化学习(DRL)算法,例如Q-learning或Actor-Critic方法,可以学习到最优的策略。ASOSA算法通过迭代更新参与者的策略,最终达到一个稳定的状态。
🖼️ 关键图片

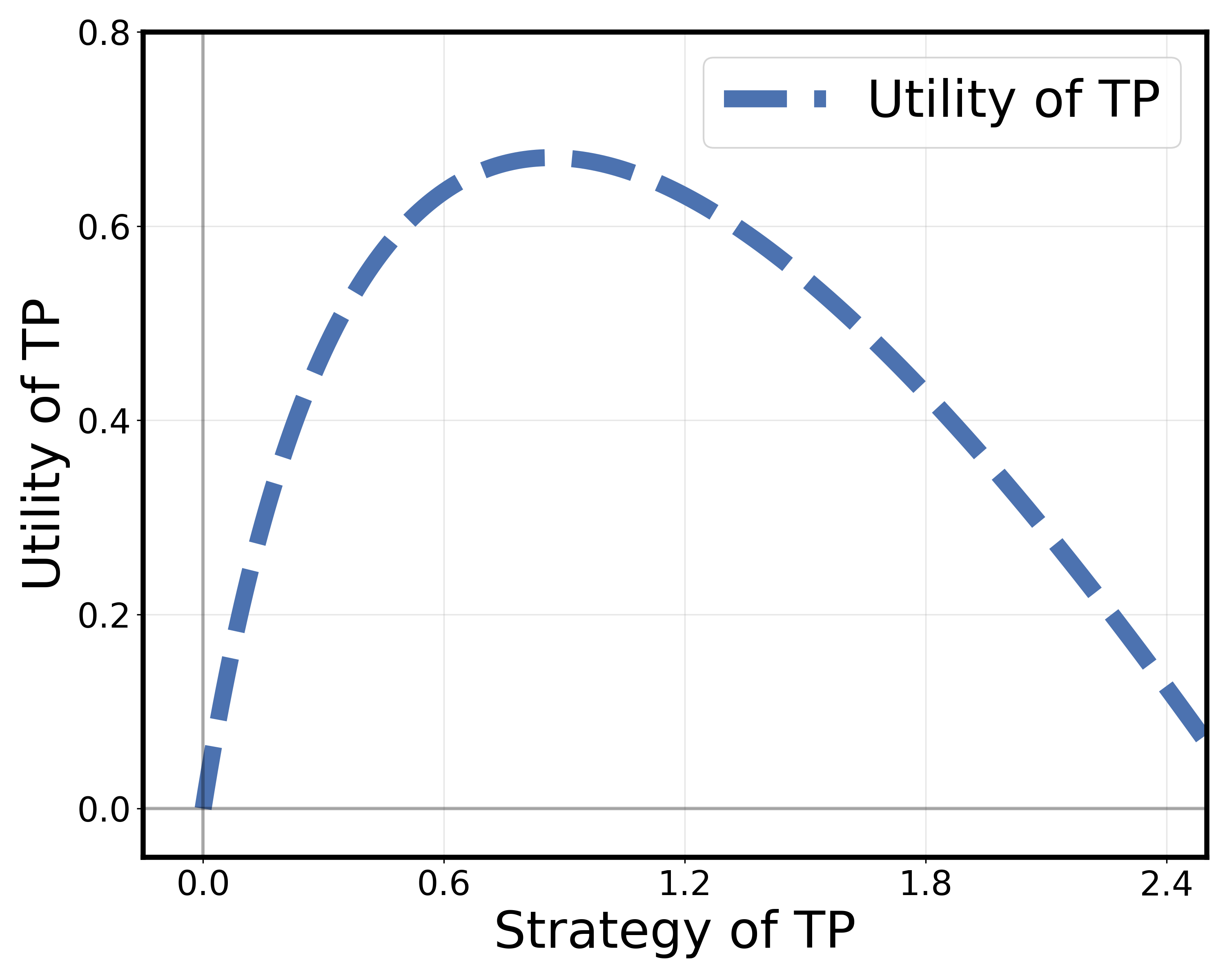
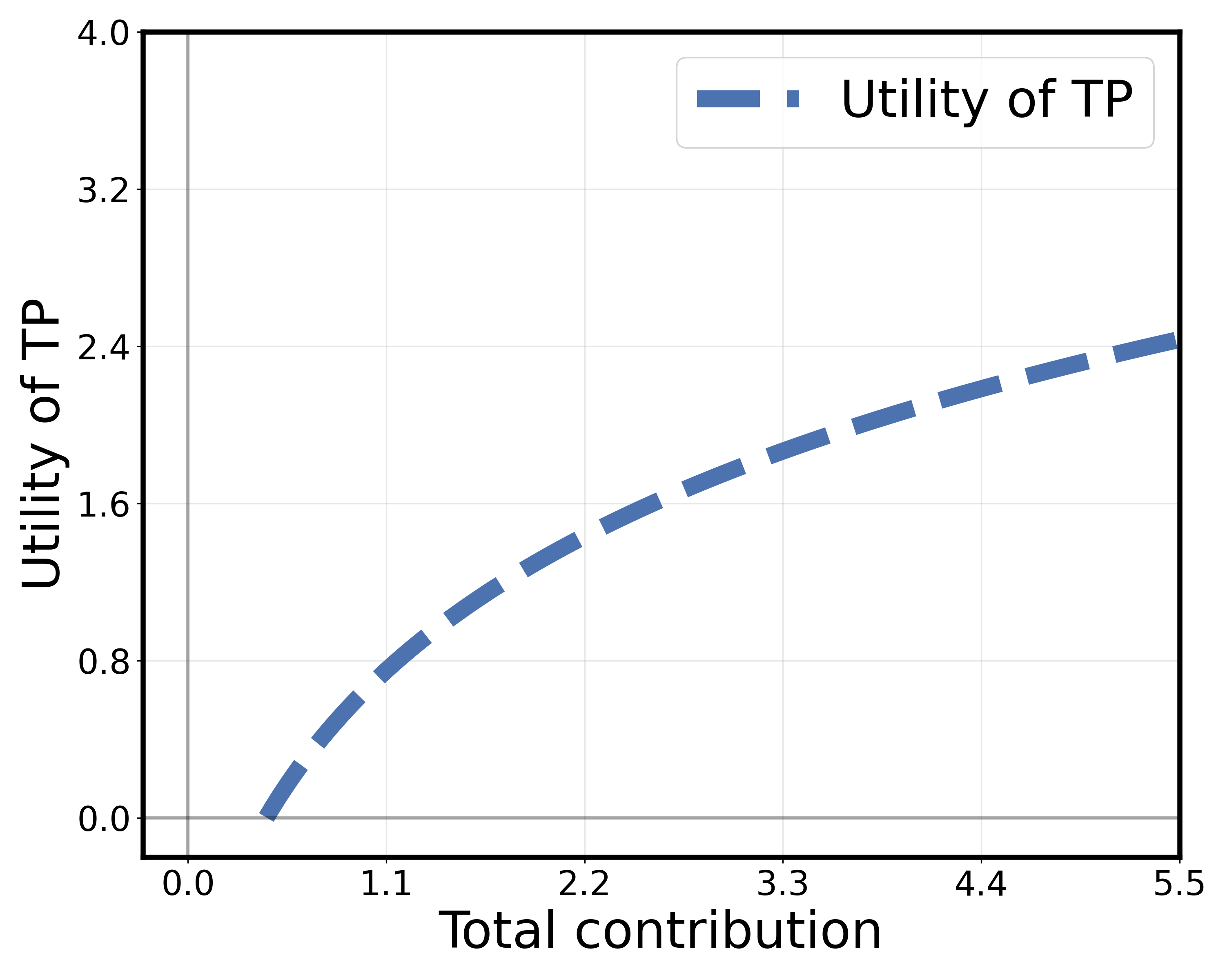
📊 实验亮点
实验结果表明,所提出的自适应分层激励机制能够有效提高TP、LMO和workers的效用。与传统的激励机制相比,该方法能够显著提高数据收集量,并降低模型训练成本。具体性能提升数据未知,需要在论文中查找。
🎯 应用场景
该研究成果可应用于各种联邦学习场景,例如医疗健康、金融风控、智能交通等。通过有效的激励机制,可以吸引更多的数据贡献者参与联邦学习,从而提高模型的准确性和泛化能力,并促进数据共享和隐私保护。
📄 摘要(原文)
Recently, federated learning (FL) has emerged as a novel framework for distributed model training. In FL, the task publisher (TP) releases tasks, and local model owners (LMOs) use their local data to train models. Sometimes, FL suffers from the lack of training data, and thus workers are recruited for gathering data. To this end, this paper proposes an adaptive incentive mechanism from a service-oriented perspective, with the objective of maximizing the utilities of TP, LMOs and workers. Specifically, a Stackelberg game is theoretically established between the LMOs and TP, positioning TP as the leader and the LMOs as followers. An analytical Nash equilibrium solution is derived to maximize their utilities. The interaction between LMOs and workers is formulated by a multi-agent Markov decision process (MAMDP), with the optimal strategy identified via deep reinforcement learning (DRL). Additionally, an Adaptively Searching the Optimal Strategy Algorithm (ASOSA) is designed to stabilize the strategies of each participant and solve the coupling problems. Extensive numerical experiments are conducted to validate the efficacy of the proposed method.