VendiRL: A Framework for Self-Supervised Reinforcement Learning of Diversely Diverse Skills
作者: Erik M. Lintunen
分类: cs.LG, cs.AI, cs.RO
发布日期: 2025-09-03 (更新: 2025-10-12)
备注: 17 pages including appendices, full paper at the Scaling Environments for Agents workshop at NeurIPS 2025
💡 一句话要点
VendiRL:用于自监督强化学习多样化技能的框架
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 自监督强化学习 技能多样性 Vendi Score 强化学习 机器人 技能预训练 多样性度量
📋 核心要点
- 现有自监督强化学习方法在高维特征空间中难以有效搜索有意义的技能,导致可扩展性问题。
- VendiRL框架利用Vendi Score度量样本多样性,允许用户自定义和评估技能的多样性形式。
- 该框架通过不同的相似性函数,激发不同的技能多样性形式,支持在交互环境中进行技能预训练。
📝 摘要(中文)
在自监督强化学习(RL)中,一个关键挑战是学习一套多样化的技能,为智能体应对未知的未来任务做好准备。尽管取得了显著进展,但可扩展性和评估仍然是普遍存在的问题。在可扩展性方面,对有意义技能的搜索可能会被高维特征空间所掩盖,其中相关特征可能因下游任务领域而异。在评估技能多样性方面,对“多样性”的定义通常需要对技能多样性的具体概念做出硬性承诺,这可能会导致对技能多样性理解的不一致,使得不同方法的结果难以比较,并留下许多形式的多样性未被探索。为了解决这些问题,我们采用了一种样本多样性的度量方法,该方法将生态学的思想转化为机器学习——Vendi Score——允许用户指定和评估任何所需形式的多样性。我们展示了该指标如何促进技能评估,并介绍了VendiRL,这是一个用于学习多样化技能的统一框架。给定不同的相似性函数,VendiRL激发了不同的多样性形式,这可以支持在新的、丰富的交互环境中进行技能多样性预训练,在这些环境中,优化各种形式的多样性可能是可取的。
🔬 方法详解
问题定义:现有的自监督强化学习方法在学习多样化技能时面临两个主要问题:一是可扩展性问题,即在高维特征空间中难以找到有意义的技能;二是技能多样性的评估问题,即缺乏统一的、灵活的评估标准,导致不同方法的结果难以比较,并且可能忽略某些形式的多样性。现有方法通常需要预先定义技能多样性的具体概念,限制了其适用性。
核心思路:VendiRL的核心思路是利用Vendi Score来度量和优化技能的多样性。Vendi Score是一种从生态学借鉴而来的样本多样性度量方法,它允许用户根据不同的相似性函数来定义和评估多样性。通过最大化Vendi Score,VendiRL可以学习到更具多样性的技能集合,从而提高智能体在未知环境中的适应能力。
技术框架:VendiRL框架主要包含以下几个模块:1) 技能生成器:负责生成不同的技能;2) 相似性函数:定义技能之间的相似度,不同的相似性函数对应不同的多样性形式;3) Vendi Score计算器:根据相似性函数计算技能集合的Vendi Score;4) 策略优化器:利用Vendi Score作为奖励信号,优化技能生成器的策略,使其能够生成更具多样性的技能。整个流程是一个循环迭代的过程,通过不断优化策略,最终学习到一组多样化的技能。
关键创新:VendiRL的关键创新在于引入了Vendi Score作为技能多样性的度量标准。与现有方法相比,Vendi Score具有以下优势:1) 灵活性:用户可以根据不同的任务需求,自定义相似性函数,从而定义不同的多样性形式;2) 可解释性:Vendi Score提供了一种量化技能多样性的方法,使得技能评估更加客观和可比较;3) 可扩展性:Vendi Score可以应用于高维特征空间,从而解决现有方法的可扩展性问题。
关键设计:VendiRL的关键设计包括:1) 相似性函数的选择:不同的相似性函数会导致不同的多样性形式,例如,可以使用状态相似性、动作相似性或目标相似性等;2) Vendi Score的计算方法:Vendi Score的计算涉及到样本之间的距离计算和概率估计,需要选择合适的算法来提高计算效率;3) 策略优化器的选择:可以使用各种强化学习算法来优化技能生成器的策略,例如,可以使用PPO、SAC等算法。
🖼️ 关键图片
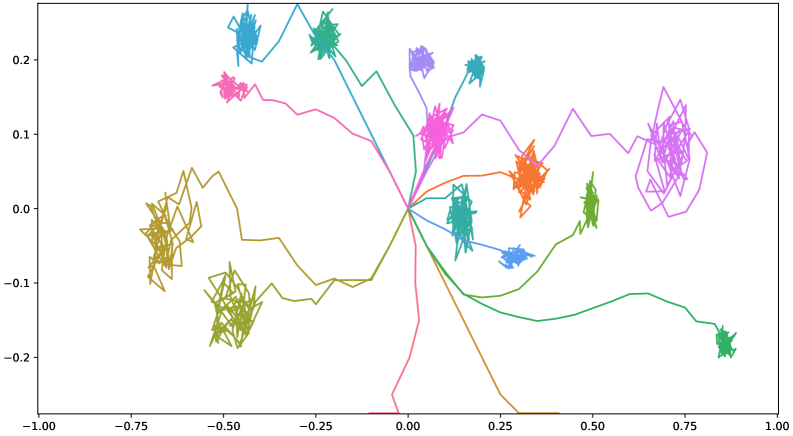
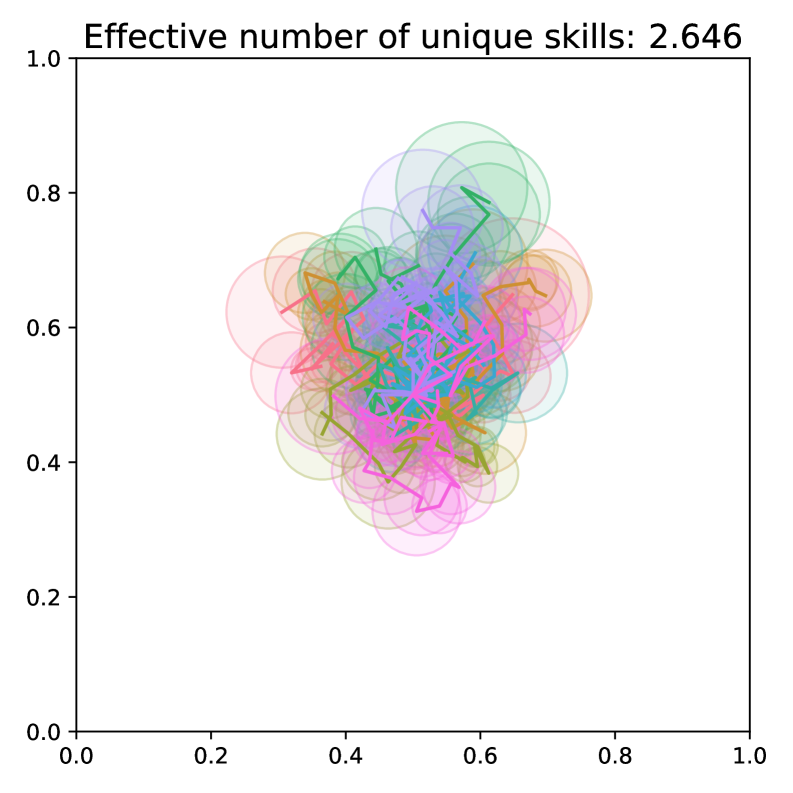
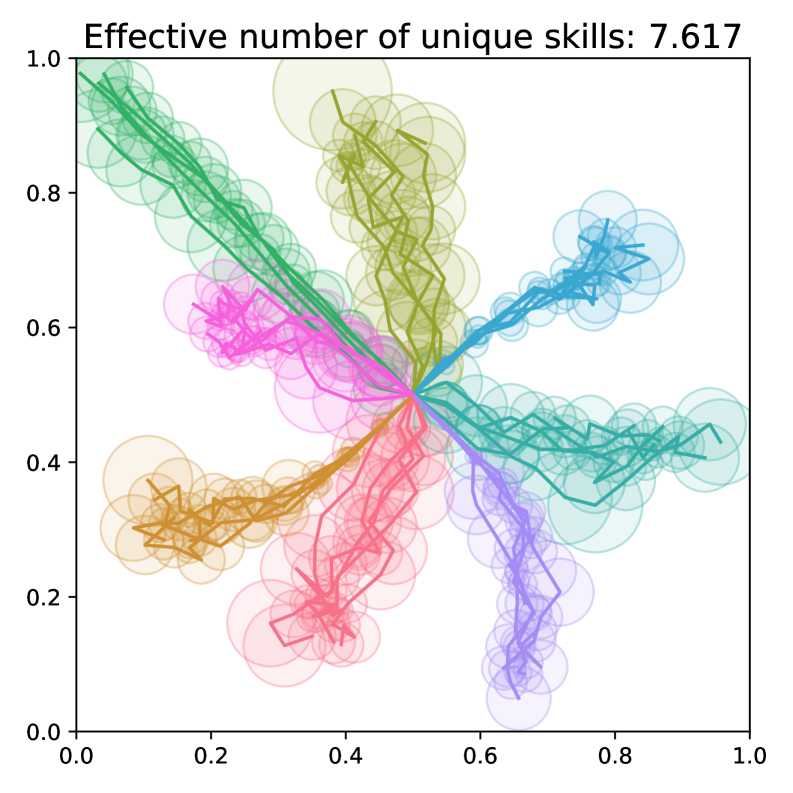
📊 实验亮点
论文提出了VendiRL框架,并使用Vendi Score作为技能多样性的度量标准。实验结果表明,VendiRL能够学习到比现有方法更具多样性的技能集合。通过在不同的环境中进行测试,验证了VendiRL的有效性和泛化能力。具体的性能数据和对比基线在论文中有详细描述,展示了VendiRL在技能多样性学习方面的显著提升。
🎯 应用场景
VendiRL框架可应用于各种需要智能体具备多样化技能的领域,例如机器人导航、游戏AI、自动驾驶等。通过预训练一组多样化的技能,智能体可以更快地适应新的环境和任务,提高其泛化能力和鲁棒性。该研究对于推动自监督强化学习的发展具有重要意义,并为解决实际问题提供了新的思路。
📄 摘要(原文)
In self-supervised reinforcement learning (RL), one of the key challenges is learning a diverse set of skills to prepare agents for unknown future tasks. Despite impressive advances, scalability and evaluation remain prevalent issues. Regarding scalability, the search for meaningful skills can be obscured by high-dimensional feature spaces, where relevant features may vary across downstream task domains. For evaluating skill diversity, defining what constitutes "diversity" typically requires a hard commitment to a specific notion of what it means for skills to be diverse, potentially leading to inconsistencies in how skill diversity is understood, making results across different approaches hard to compare, and leaving many forms of diversity unexplored. To address these issues, we adopt a measure of sample diversity that translates ideas from ecology to machine learning -- the Vendi Score -- allowing the user to specify and evaluate any desired form of diversity. We demonstrate how this metric facilitates skill evaluation and introduce VendiRL, a unified framework for learning diversely diverse sets of skills. Given distinct similarity functions, VendiRL motivates distinct forms of diversity, which could support skill-diversity pretraining in new and richly interactive environments where optimising for various forms of diversity may be desirable.