Towards High Data Efficiency in Reinforcement Learning with Verifiable Reward
作者: Xinyu Tang, Zhenduo Zhang, Yurou Liu, Wayne Xin Zhao, Zujie Wen, Zhiqiang Zhang, Jun Zhou
分类: cs.LG, cs.CL
发布日期: 2025-09-01
💡 一句话要点
DEPO:面向可验证奖励强化学习的高数据效率策略优化
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 强化学习 数据效率 可验证奖励 策略优化 数据选择
📋 核心要点
- 现有基于可验证奖励强化学习的推理模型训练成本高昂,数据效率低,需要大量rollout计算和数据集。
- DEPO通过优化离线和在线数据选择策略,选择高质量和高探索性的样本,减少计算量并提升数据利用率。
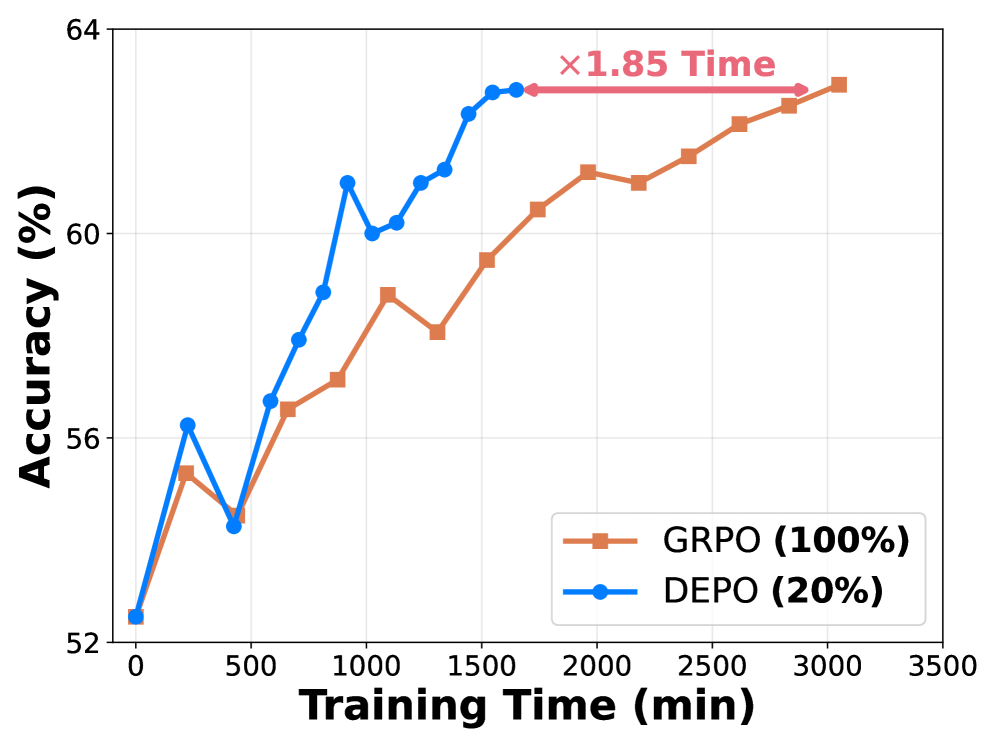
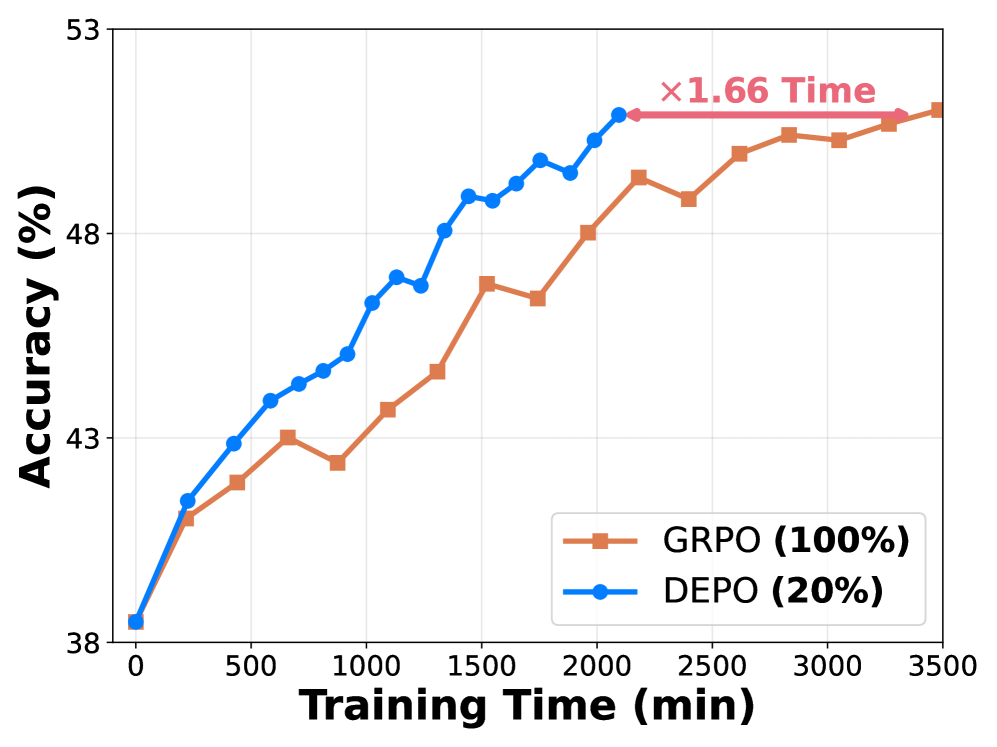
- 实验表明,DEPO在多个推理基准上优于现有方法,仅用20%数据即可达到甚至超越全量数据训练的效果。
📝 摘要(中文)
大型推理模型利用可验证奖励强化学习(RLVR)来提升推理能力。然而,扩展这些方法通常需要大量的rollout计算和大型数据集,导致高训练成本和低数据效率。为了解决这个问题,我们提出了DEPO,一种数据高效的策略优化流程,它结合了离线和在线数据选择的优化策略。在离线阶段,我们基于多样性、影响力和适当的难度来管理高质量的训练样本子集。在在线RLVR训练期间,我们引入了一个样本级别的可探索性指标,以动态过滤具有低探索潜力的样本,从而显著降低rollout计算成本。此外,我们结合了一个针对未充分探索样本的回放机制,以确保充分的训练,从而提高模型的最终收敛性能。在五个推理基准上的实验表明,DEPO在离线和在线数据选择场景中始终优于现有方法。值得注意的是,仅使用20%的训练数据,与在完整数据集上训练的GRPO相比,我们的方法在AIME24上实现了1.85倍的加速,在AIME25上实现了1.66倍的加速。
🔬 方法详解
问题定义:现有基于可验证奖励的强化学习方法在训练大型推理模型时,面临数据效率低下的问题。具体来说,为了获得可靠的奖励信号,需要进行大量的rollout计算,这导致训练成本非常高昂,尤其是在复杂推理任务中。此外,大量的数据并不一定都对模型训练有益,冗余或低质量的数据反而会降低模型的训练效率和泛化能力。
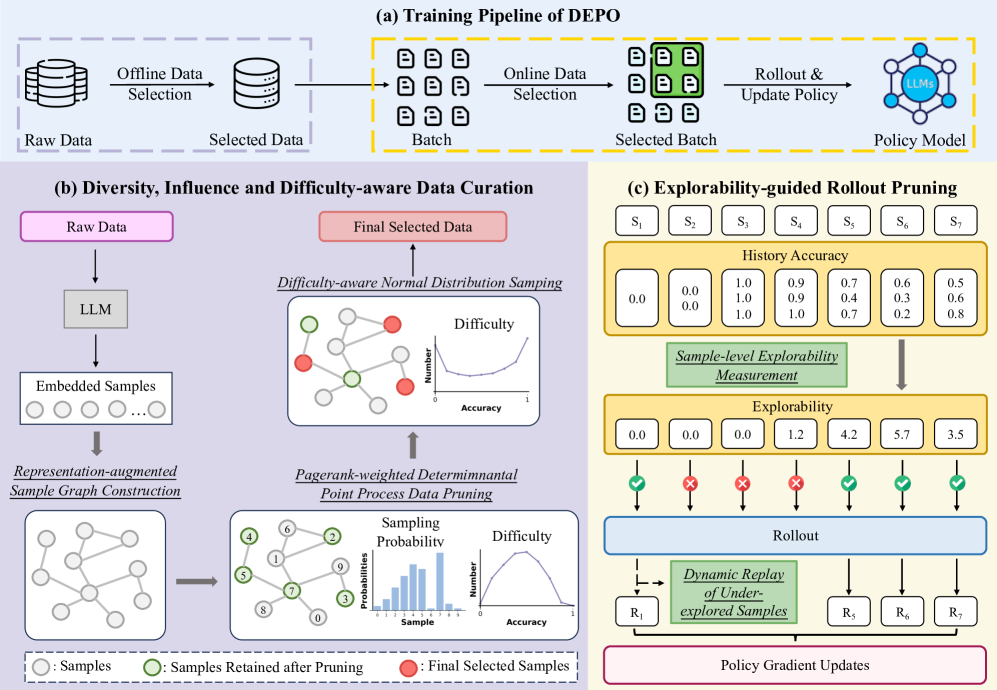
核心思路:DEPO的核心思路是通过智能的数据选择策略,在离线和在线两个阶段都只选择对模型训练最有价值的数据。离线阶段,预先筛选出高质量的训练样本;在线阶段,动态过滤掉探索潜力低的样本,并对未充分探索的样本进行回放,从而在保证模型性能的同时,显著降低计算成本。
技术框架:DEPO包含离线数据选择和在线数据选择两个主要阶段。离线阶段,首先对原始数据集进行分析,然后根据多样性、影响力和难度三个指标选择一个高质量的子集。在线阶段,在强化学习训练过程中,引入一个样本级别的可探索性指标来评估每个样本的价值,并动态过滤掉低价值的样本。同时,采用回放机制,对那些探索不足的样本进行重复利用,以保证模型的充分训练。
关键创新:DEPO的关键创新在于其综合考虑了离线数据选择和在线数据选择,并设计了相应的优化策略。离线数据选择策略能够预先筛选出高质量的训练样本,减少了后续训练的负担。在线数据选择策略能够动态地调整训练数据的分布,从而更加高效地利用计算资源。样本级别的可探索性指标和回放机制进一步提升了模型的训练效率和最终性能。
关键设计:离线数据选择中,多样性通过计算样本之间的距离来衡量,影响力通过评估样本对模型参数的影响来衡量,难度则根据模型在样本上的表现来评估。在线数据选择中,可探索性指标基于样本的奖励和访问频率来计算。回放机制则采用优先经验回放的思想,优先回放那些探索不足的样本。
🖼️ 关键图片
📊 实验亮点
实验结果表明,DEPO在五个推理基准上都取得了显著的性能提升。特别是在AIME24和AIME25数据集上,仅使用20%的训练数据,DEPO就分别实现了1.85倍和1.66倍的加速,同时性能优于使用完整数据集训练的GRPO。这充分证明了DEPO在数据效率方面的优势。
🎯 应用场景
DEPO方法可以应用于各种需要高数据效率的强化学习场景,尤其是在计算资源有限或数据获取成本较高的领域,例如机器人控制、自动驾驶、游戏AI和自然语言处理等。通过减少训练所需的数据量和计算资源,DEPO可以加速模型的开发和部署,并降低成本。此外,DEPO还可以帮助模型更好地泛化到新的环境和任务中。
📄 摘要(原文)
Recent advances in large reasoning models have leveraged reinforcement learning with verifiable rewards (RLVR) to improve reasoning capabilities. However, scaling these methods typically requires extensive rollout computation and large datasets, leading to high training costs and low data efficiency. To mitigate this issue, we propose DEPO, a Data-Efficient Policy Optimization pipeline that combines optimized strategies for both offline and online data selection. In the offline phase, we curate a high-quality subset of training samples based on diversity, influence, and appropriate difficulty. During online RLVR training, we introduce a sample-level explorability metric to dynamically filter samples with low exploration potential, thereby reducing substantial rollout computational costs. Furthermore, we incorporate a replay mechanism for under-explored samples to ensure adequate training, which enhances the model's final convergence performance. Experiments across five reasoning benchmarks show that DEPO consistently outperforms existing methods in both offline and online data selection scenarios. Notably, using only 20% of the training data, our approach achieves a 1.85 times speed-up on AIME24 and a 1.66 times speed-up on AIME25 compared to GRPO trained on the full dataset.