Adaptive LLM Routing under Budget Constraints
作者: Pranoy Panda, Raghav Magazine, Chaitanya Devaguptapu, Sho Takemori, Vishal Sharma
分类: cs.LG
发布日期: 2025-08-28 (更新: 2025-09-09)
备注: Accepted at EMNLP 2025 (findings)
💡 一句话要点
提出PILOT:预算约束下基于偏好先验的自适应LLM路由方法
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: LLM路由 上下文Bandit 自适应学习 在线学习 预算约束 共享嵌入空间 资源优化
📋 核心要点
- 现有LLM路由方法依赖于监督学习,需要完备的查询-LLM配对知识,这在实际应用中难以满足,且无法适应不断变化的用户查询。
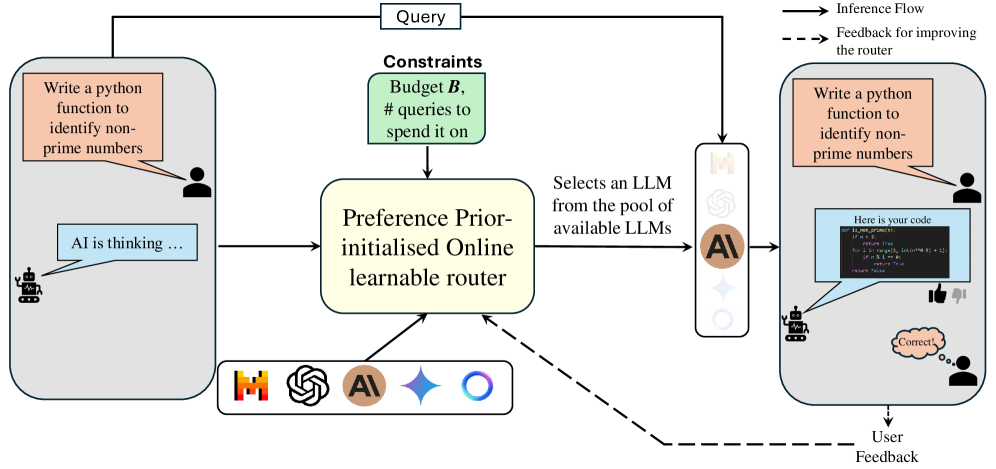
- 论文提出将LLM路由视为上下文bandit问题,利用bandit反馈进行自适应决策,避免对所有LLM进行穷举推理,提高效率。
- 通过构建共享嵌入空间对齐查询和LLM,并结合在线成本策略,实现了在用户预算约束下的资源高效LLM路由。
📝 摘要(中文)
大型语言模型(LLMs)彻底改变了自然语言处理领域,但它们各异的能力和成本给实际应用带来了挑战。LLM路由通过为每个查询/任务动态选择最合适的LLM来解决这个问题。以往的方法将其视为一个监督学习问题,假设完全了解最优的查询-LLM配对。然而,现实场景缺乏这种全面的映射,并且面临不断变化的用户查询。因此,我们提出将LLM路由作为一个上下文bandit问题来研究,从而能够使用bandit反馈进行自适应决策,而无需对所有查询的所有LLM进行详尽的推理(与监督路由相反)。为了解决这个问题,我们为查询和LLM开发了一个共享嵌入空间,其中查询和LLM嵌入对齐以反映它们的亲和力。这个空间最初是从离线人类偏好数据中学习的,并通过在线bandit反馈进行细化。我们通过Preference-prior Informed Linucb fOr adaptive rouTing (PILOT) 来实例化这个想法,PILOT是LinUCB的一个新的扩展。为了处理用户对模型路由的不同预算,我们引入了一个在线成本策略,将其建模为一个多选择背包问题,确保资源高效的路由。
🔬 方法详解
问题定义:论文旨在解决在实际应用中,由于缺乏完备的查询-LLM配对知识以及用户查询的不断变化,导致现有LLM路由方法无法有效选择最优LLM的问题。现有方法通常采用监督学习,需要预先知道所有查询与LLM之间的最佳匹配,这在动态和复杂的环境中是不现实的。此外,用户通常有预算限制,需要在成本和性能之间进行权衡。
核心思路:论文的核心思路是将LLM路由问题建模为上下文bandit问题,利用在线学习的方式,通过bandit反馈不断优化路由策略。通过构建查询和LLM的共享嵌入空间,可以衡量查询和LLM之间的相关性,从而选择最合适的LLM。同时,引入在线成本策略,根据用户预算动态调整路由决策,实现资源高效的LLM选择。
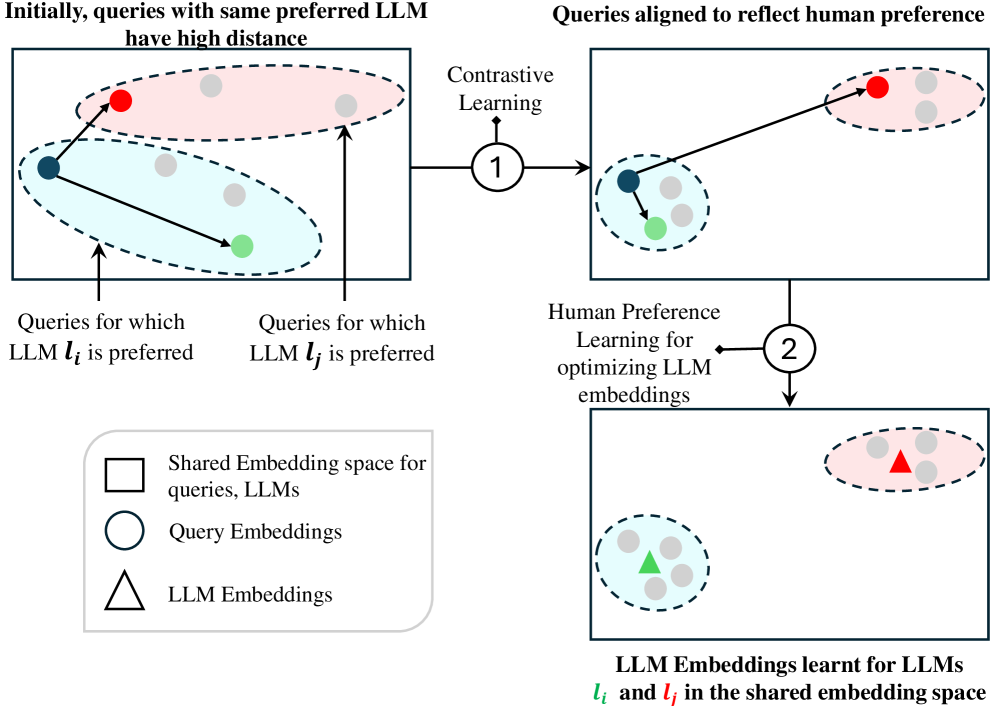
技术框架:整体框架包含离线学习和在线学习两个阶段。离线阶段,利用人类偏好数据学习查询和LLM的共享嵌入空间。在线阶段,利用PILOT算法(Preference-prior Informed LinUCB)进行自适应路由,并根据bandit反馈更新嵌入空间。同时,使用多选择背包问题建模在线成本策略,根据用户预算选择合适的LLM。
关键创新:论文的关键创新在于将LLM路由问题建模为上下文bandit问题,并提出了PILOT算法。与传统的监督学习方法相比,PILOT算法能够利用bandit反馈进行自适应学习,无需预先知道所有查询与LLM之间的最佳匹配。此外,论文还提出了在线成本策略,能够根据用户预算动态调整路由决策,实现资源高效的LLM选择。
关键设计:PILOT算法是LinUCB的扩展,利用人类偏好数据作为先验知识,指导嵌入空间的学习。在线成本策略采用多选择背包问题建模,目标是在预算约束下最大化奖励。具体而言,LinUCB算法使用置信上限来估计每个LLM的奖励,并选择置信上限最高的LLM。嵌入空间通过对比学习进行训练,目标是使相似的查询和LLM在嵌入空间中距离更近。
🖼️ 关键图片
📊 实验亮点
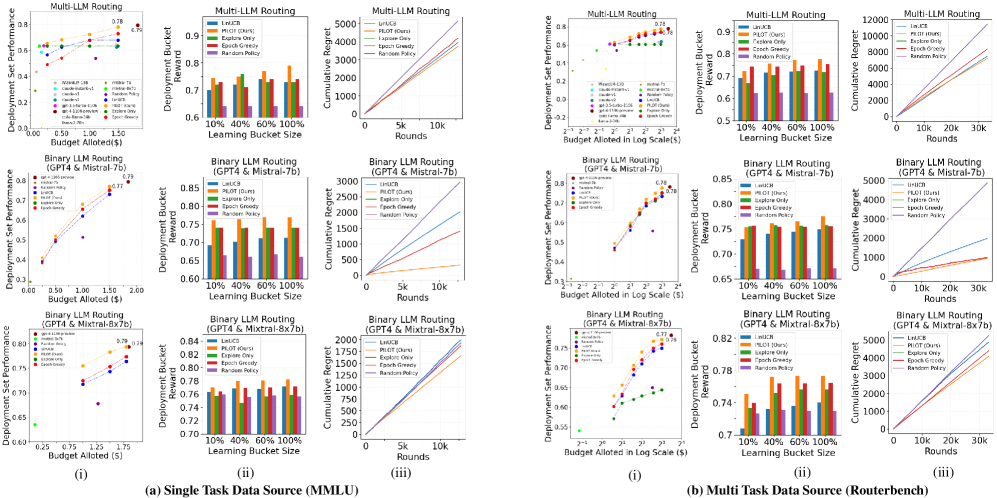
论文提出了PILOT算法,并在多个数据集上进行了实验验证。实验结果表明,PILOT算法在自适应路由和预算控制方面优于现有的基线方法。具体而言,PILOT算法在保证性能的同时,能够显著降低LLM的使用成本,并更好地满足用户的预算约束。具体提升幅度未知,需要在论文中查找。
🎯 应用场景
该研究成果可应用于各种需要动态选择LLM的场景,例如智能客服、内容生成、机器翻译等。通过自适应路由和预算控制,可以提高LLM的使用效率,降低成本,并提升用户体验。未来可以进一步探索如何将该方法应用于更复杂的任务和场景,例如多模态LLM路由。
📄 摘要(原文)
Large Language Models (LLMs) have revolutionized natural language processing, but their varying capabilities and costs pose challenges in practical applications. LLM routing addresses this by dynamically selecting the most suitable LLM for each query/task. Previous approaches treat this as a supervised learning problem, assuming complete knowledge of optimal query-LLM pairings. However, real-world scenarios lack such comprehensive mappings and face evolving user queries. We thus propose to study LLM routing as a contextual bandit problem, enabling adaptive decision-making using bandit feedback without requiring exhaustive inference across all LLMs for all queries (in contrast to supervised routing). To address this problem, we develop a shared embedding space for queries and LLMs, where query and LLM embeddings are aligned to reflect their affinity. This space is initially learned from offline human preference data and refined through online bandit feedback. We instantiate this idea through Preference-prior Informed Linucb fOr adaptive rouTing (PILOT), a novel extension of LinUCB. To handle diverse user budgets for model routing, we introduce an online cost policy modeled as a multi-choice knapsack problem, ensuring resource-efficient routing.