Inference-Time Alignment Control for Diffusion Models with Reinforcement Learning Guidance
作者: Luozhijie Jin, Zijie Qiu, Jie Liu, Zijie Diao, Lifeng Qiao, Ning Ding, Alex Lamb, Xipeng Qiu
分类: cs.LG, cs.AI
发布日期: 2025-08-28
🔗 代码/项目: GITHUB
💡 一句话要点
提出RLG:一种基于强化学习引导的扩散模型推理时对齐控制方法
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱四:生成式动作 (Generative Motion) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 扩散模型 强化学习 推理时控制 对齐 生成模型
📋 核心要点
- 现有扩散模型的强化学习微调方法在对齐下游目标时存在局限性,无法灵活控制对齐强度。
- 论文提出强化学习引导(RLG),通过几何平均结合基础模型和RL微调模型的输出,实现推理时的对齐控制。
- 实验表明,RLG在多种任务中提升了RL微调模型的性能,并支持插值和外推,提供灵活的对齐控制。
📝 摘要(中文)
基于去噪的生成模型,特别是扩散模型和流匹配算法,已经取得了显著的成功。然而,使其输出分布与复杂的下游目标(如人类偏好、组合准确性或数据可压缩性)对齐仍然具有挑战性。受大型语言模型中基于人类反馈的强化学习(RLHF)的启发,强化学习(RL)微调方法已被应用于这些生成框架,但当前的RL方法对于扩散模型来说并非最优,并且在微调后对对齐强度提供有限的控制灵活性。本文通过随机微分方程和隐式奖励条件反射的视角重新解释了扩散模型的RL微调。我们引入了强化学习引导(RLG),这是一种推理时方法,通过几何平均结合基础模型和RL微调模型的输出来调整无分类器引导(CFG)。我们的理论分析表明,RLG的引导尺度在数学上等同于调整标准RL目标中的KL正则化系数,从而无需进一步训练即可动态控制对齐-质量的权衡。大量的实验表明,RLG在各种架构、RL算法和下游任务(包括人类偏好、组合控制、可压缩性和文本渲染)中,始终提高了RL微调模型的性能。此外,RLG支持插值和外推,从而在控制生成对齐方面提供了前所未有的灵活性。我们的方法为在推理时增强和控制扩散模型对齐提供了一种实用且理论上合理的解决方案。
🔬 方法详解
问题定义:论文旨在解决扩散模型在与复杂下游目标(如人类偏好、组合准确性、数据压缩等)对齐时面临的挑战。现有基于强化学习的微调方法存在两个主要痛点:一是针对扩散模型的优化效果不佳;二是微调后难以灵活控制对齐的强度,缺乏推理时的调整能力。
核心思路:论文的核心思路是将RL微调过程重新解释为随机微分方程和隐式奖励条件反射,从而将推理时的引导尺度与RL目标中的KL正则化系数联系起来。通过调整引导尺度,可以在推理时动态控制对齐质量的权衡,而无需重新训练模型。这种方法借鉴了无分类器引导(CFG)的思想,但通过几何平均的方式结合了基础模型和RL微调模型的输出,从而实现了更精细的控制。
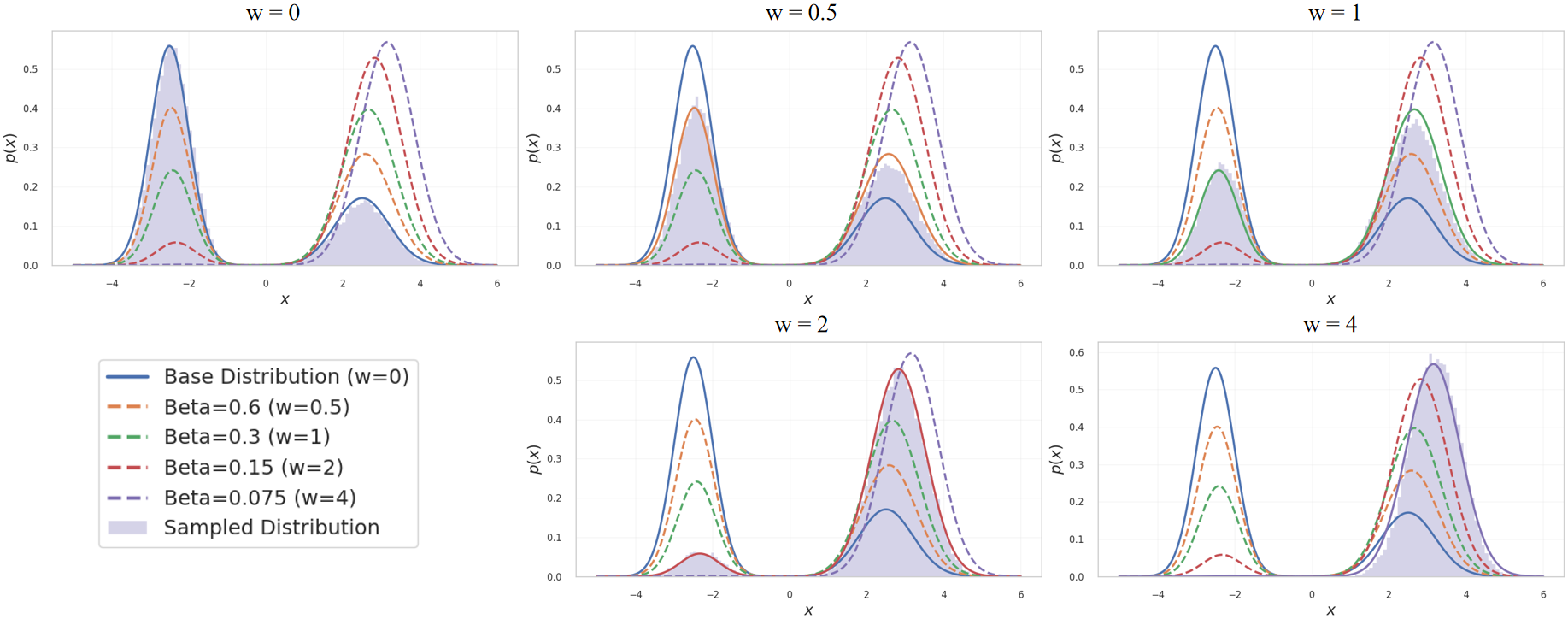
技术框架:RLG方法的核心在于推理阶段。首先,使用一个预训练的扩散模型和一个经过RL微调的扩散模型。在推理时,RLG通过以下步骤生成样本:1) 使用基础模型生成一个样本;2) 使用RL微调模型生成另一个样本;3) 通过几何平均的方式将两个样本结合起来,得到最终的生成结果。几何平均的权重由一个引导尺度参数控制,该参数决定了RL微调模型对最终结果的影响程度。
关键创新:RLG的关键创新在于将推理时的引导尺度与RL目标中的KL正则化系数建立了数学上的等价关系。这意味着可以通过调整引导尺度来控制模型在对齐下游目标和保持生成质量之间的平衡。此外,RLG支持插值和外推,允许在训练时未见过的引导尺度下进行推理,从而提供了前所未有的灵活性。
关键设计:RLG的关键设计在于使用几何平均来结合基础模型和RL微调模型的输出。几何平均的公式为:x_guided = x_base^(1-scale) * x_rl^scale,其中x_base是基础模型的输出,x_rl是RL微调模型的输出,scale是引导尺度。引导尺度是一个关键参数,需要根据具体的下游任务进行调整。论文还探讨了如何选择合适的RL算法和奖励函数,以获得更好的微调效果。
🖼️ 关键图片


📊 实验亮点
实验结果表明,RLG在多个任务上显著提升了RL微调模型的性能。例如,在人类偏好对齐任务中,RLG能够生成更符合人类偏好的图像;在组合控制任务中,RLG能够生成更准确地反映组合关系的图像;在数据压缩任务中,RLG能够生成更易于压缩的图像。此外,RLG还支持插值和外推,允许在训练时未见过的引导尺度下进行推理,从而提供了更大的灵活性。
🎯 应用场景
该研究成果可广泛应用于各种需要对扩散模型输出进行精细控制的场景,例如:根据人类偏好生成图像、提高生成图像的组合准确性、优化生成图像的数据压缩率、以及改善文本渲染效果。该方法具有很高的实际价值,可以提升生成模型的可用性和用户体验,并为未来的生成模型研究提供新的思路。
📄 摘要(原文)
Denoising-based generative models, particularly diffusion and flow matching algorithms, have achieved remarkable success. However, aligning their output distributions with complex downstream objectives, such as human preferences, compositional accuracy, or data compressibility, remains challenging. While reinforcement learning (RL) fine-tuning methods, inspired by advances in RL from human feedback (RLHF) for large language models, have been adapted to these generative frameworks, current RL approaches are suboptimal for diffusion models and offer limited flexibility in controlling alignment strength after fine-tuning. In this work, we reinterpret RL fine-tuning for diffusion models through the lens of stochastic differential equations and implicit reward conditioning. We introduce Reinforcement Learning Guidance (RLG), an inference-time method that adapts Classifier-Free Guidance (CFG) by combining the outputs of the base and RL fine-tuned models via a geometric average. Our theoretical analysis shows that RLG's guidance scale is mathematically equivalent to adjusting the KL-regularization coefficient in standard RL objectives, enabling dynamic control over the alignment-quality trade-off without further training. Extensive experiments demonstrate that RLG consistently improves the performance of RL fine-tuned models across various architectures, RL algorithms, and downstream tasks, including human preferences, compositional control, compressibility, and text rendering. Furthermore, RLG supports both interpolation and extrapolation, thereby offering unprecedented flexibility in controlling generative alignment. Our approach provides a practical and theoretically sound solution for enhancing and controlling diffusion model alignment at inference. The source code for RLG is publicly available at the Github: https://github.com/jinluo12345/Reinforcement-learning-guidance.