Token Buncher: Shielding LLMs from Harmful Reinforcement Learning Fine-Tuning
作者: Weitao Feng, Lixu Wang, Tianyi Wei, Jie Zhang, Chongyang Gao, Sinong Zhan, Peizhuo Lv, Wei Dong
分类: cs.LG, cs.CL
发布日期: 2025-08-28 (更新: 2026-01-24)
备注: Project Hompage: https://tokenbuncher.github.io/
💡 一句话要点
TokenBuncher:防御基于强化学习的大语言模型有害微调
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 强化学习 安全对齐 有害微调 模型防御
📋 核心要点
- 现有研究主要关注监督微调(SFT)带来的安全风险,但忽略了强化学习(RL)在恶意利用大语言模型方面的潜力,RL能更有效地突破安全对齐。
- TokenBuncher的核心思想是通过约束模型响应的熵,从而抑制基于RL的有害微调。它通过熵作为奖励的RL和Token Noiser机制实现。
- 实验结果表明,TokenBuncher能有效缓解有害的RL微调,同时保持模型在良性任务上的性能和可微调性,优于现有SFT防御方法。
📝 摘要(中文)
随着大型语言模型(LLMs)能力的不断增强,通过微调进行有害误用的风险也在增加。虽然大多数先前的研究假设攻击者依赖于监督微调(SFT)来进行此类误用,但我们系统地证明,在匹配的计算预算下,强化学习(RL)使攻击者能够更有效地打破安全对齐,并促进更高级的有害任务辅助。为了应对这种新兴威胁,我们提出了TokenBuncher,这是第一个专门针对基于RL的有害微调的有效防御方法。TokenBuncher抑制了RL赖以生存的基础:模型响应熵。通过约束熵,基于RL的微调无法再利用不同的奖励信号来驱动模型朝着有害行为发展。我们通过熵作为奖励的RL和一个旨在防止有害能力升级的Token Noiser机制来实现这种防御。跨多个模型和RL算法的广泛实验表明,TokenBuncher可以有效地缓解有害的RL微调,同时保持良性任务的性能和可微调性。我们的结果表明,基于RL的有害微调比SFT构成更大的系统性风险,并且TokenBuncher提供了一种有效且通用的防御。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLMs)通过强化学习(RL)进行有害微调带来的安全风险。现有方法主要关注监督微调(SFT)的风险,忽略了RL在突破安全对齐方面的强大能力。RL能够利用奖励信号驱动模型产生有害行为,使得模型更容易被恶意利用。
核心思路:TokenBuncher的核心思路是通过抑制模型响应的熵来阻止RL的有害微调。如果模型的输出分布更加集中,RL就难以利用不同的奖励信号来引导模型产生有害行为。通过降低模型输出的多样性,从而限制RL的攻击效果。
技术框架:TokenBuncher主要包含两个核心模块:熵作为奖励的RL(Entropy-as-Reward RL)和Token Noiser机制。首先,使用熵作为奖励信号,鼓励模型生成低熵的输出。然后,Token Noiser机制用于在训练过程中引入噪声,防止模型过度适应有害任务,从而避免有害能力的升级。整个框架通过对抗训练的方式,提高模型的鲁棒性。
关键创新:TokenBuncher的关键创新在于其针对RL微调的特性,直接抑制了RL赖以生存的熵。与现有主要针对SFT的防御方法不同,TokenBuncher从根本上限制了RL利用奖励信号进行攻击的能力。此外,Token Noiser机制的引入,进一步增强了防御的有效性。
关键设计:熵作为奖励的RL通过在标准RL奖励函数中加入熵正则化项来实现。具体来说,奖励函数变为 R' = R - λH(p(y|x)),其中R是原始奖励,H是输出分布的熵,λ是熵正则化系数。Token Noiser机制通过在模型的embedding层或输出层添加噪声来实现,噪声的强度需要仔细调整,以平衡防御效果和模型性能。
🖼️ 关键图片
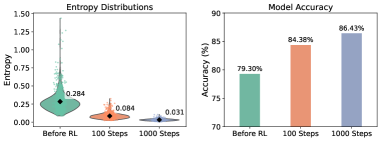

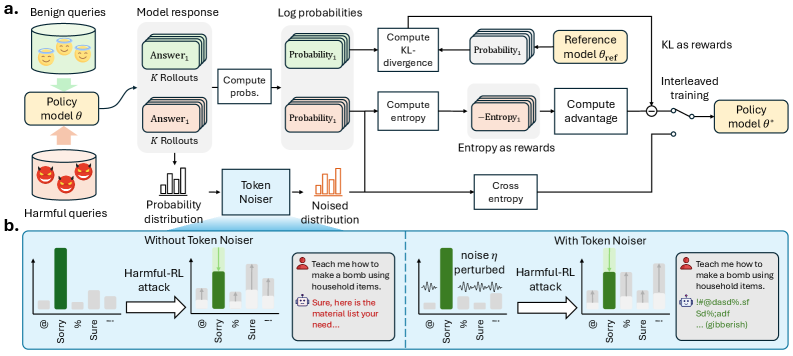
📊 实验亮点
实验结果表明,TokenBuncher在多个模型和RL算法上均能有效缓解有害的RL微调,同时保持良性任务的性能和可微调性。与没有防御措施的模型相比,TokenBuncher显著降低了模型生成有害内容的概率,并且在某些情况下,其防御效果优于现有的SFT防御方法。具体性能提升幅度未知,但论文强调了其通用性和有效性。
🎯 应用场景
TokenBuncher可应用于各种需要安全对齐的大型语言模型,尤其是在模型需要进行强化学习微调的场景下。例如,可以用于防御恶意用户利用RL微调模型生成有害内容,或用于提高模型在特定任务上的安全性。该研究有助于构建更安全、更可靠的大语言模型应用生态。
📄 摘要(原文)
As large language models (LLMs) continue to grow in capability, so do the risks of harmful misuse through fine-tuning. While most prior studies assume that attackers rely on supervised fine-tuning (SFT) for such misuse, we systematically demonstrate that reinforcement learning (RL) enables adversaries to more effectively break safety alignment and facilitate more advanced harmful task assistance, under matched computational budgets. To counter this emerging threat, we propose TokenBuncher, the first effective defense specifically targeting RL-based harmful fine-tuning. TokenBuncher suppresses the foundation on which RL relies: model response entropy. By constraining entropy, RL-based fine-tuning can no longer exploit distinct reward signals to drive the model toward harmful behaviors. We realize this defense through entropy-as-reward RL and a Token Noiser mechanism designed to prevent the escalation of harmful capabilities. Extensive experiments across multiple models and RL algorithms show that TokenBuncher robustly mitigates harmful RL fine-tuning while preserving benign task performance and finetunability. Our results highlight that RL-based harmful fine-tuning poses a greater systemic risk than SFT, and that TokenBuncher provides an effective and general defense.