Towards Mitigating Excessive Forgetting in LLM Unlearning via Entanglement-Guidance with Proxy Constraint
作者: Zhihao Liu, Jian Lou, Yuke Hu, Xiaochen Li, Yitian Chen, Tailun Chen, Zhizhen Qin, Kui Ren, Zhan Qin
分类: cs.LG, cs.AI
发布日期: 2025-08-28 (更新: 2026-01-12)
💡 一句话要点
提出EGUP框架,通过纠缠引导和代理约束缓解LLM非学习中的过度遗忘问题
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 机器学习非学习 过度遗忘 纠缠引导 代理约束 隐私保护 数据删除
📋 核心要点
- 现有LLM非学习方法缺乏有效机制来控制遗忘边界,导致过度遗忘,损害模型效用和鲁棒性。
- EGUP框架利用样本间和样本内纠缠,自适应调整非学习强度,并引入代理约束来规范遗忘过程。
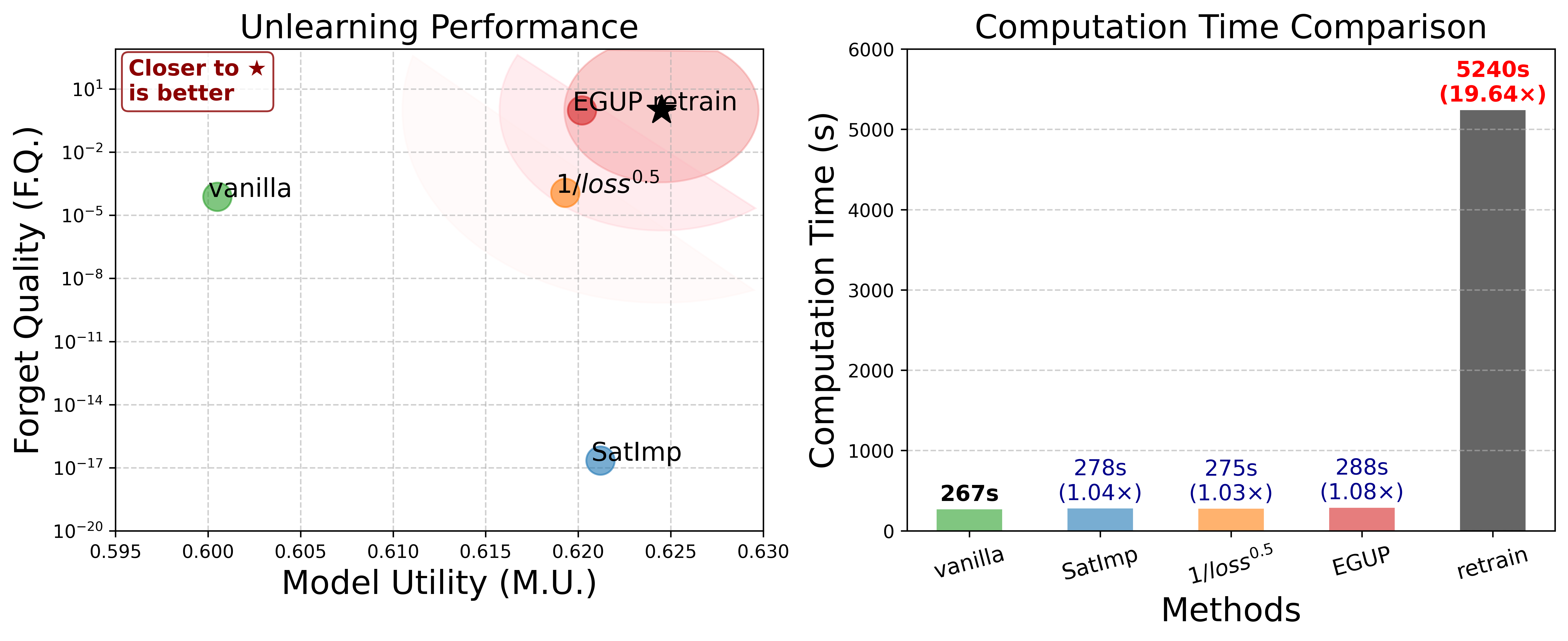
- 实验表明,EGUP在TOFU和MUSE基准上显著提升了非学习-效用权衡,性能接近重新训练模型。
📝 摘要(中文)
大型语言模型(LLMs)在海量数据集上训练,这些数据集可能包含隐私或受版权保护的内容。由于日益增长的隐私和所有权问题,数据所有者可能会要求从训练好的模型中删除他们的数据。机器学习非学习提供了一种实用的解决方案,通过消除特定数据的影响而无需完全重新训练。然而,由于缺乏规范遗忘边界的原则性机制,大多数现有方法仍然存在过度非学习的问题,导致不必要的效用降低以及更高的隐私和鲁棒性风险。在这项工作中,我们提出EGUP(Entanglement-Guided Unlearning with Proxy Constraint),这是一个新颖的框架,它利用纠缠和代理约束来指导非学习过程,同时减轻过度非学习。在每次迭代中,EGUP采用样本间纠缠来自适应地重新加权非学习强度,将更大的非学习努力分配给在语义上更接近保留知识的遗忘样本。在迭代过程中,EGUP利用样本内纠缠来跟踪每个遗忘样本的表示变化,并动态调整其非学习努力。此外,我们结合了一个代理约束,该约束近似于非学习后模型的预期输出,形成一个参考边界,以柔性地规范非学习过程。EGUP与现有的基于梯度的目标兼容,并作为一种即插即用的增强。我们在TOFU和MUSE基准上评估EGUP,证明了在多个LLM中非学习-效用权衡方面的一致改进。此外,EGUP实现了接近重新训练模型的性能,同时保持了可扩展性和鲁棒性。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLMs)非学习过程中出现的过度遗忘问题。现有方法在删除特定数据的影响时,往往会过度影响模型的其他能力,导致模型效用下降,并可能引入新的隐私和鲁棒性风险。现有方法缺乏一种精细的机制来控制遗忘的范围和程度,容易造成不必要的损害。
核心思路:论文的核心思路是通过引入纠缠引导和代理约束来更精确地控制非学习过程。纠缠引导利用样本之间的语义关系和样本自身的表示变化来动态调整非学习的强度,避免对与遗忘数据无关的知识造成影响。代理约束则通过模拟非学习后的模型输出,为非学习过程提供一个参考边界,防止过度遗忘。
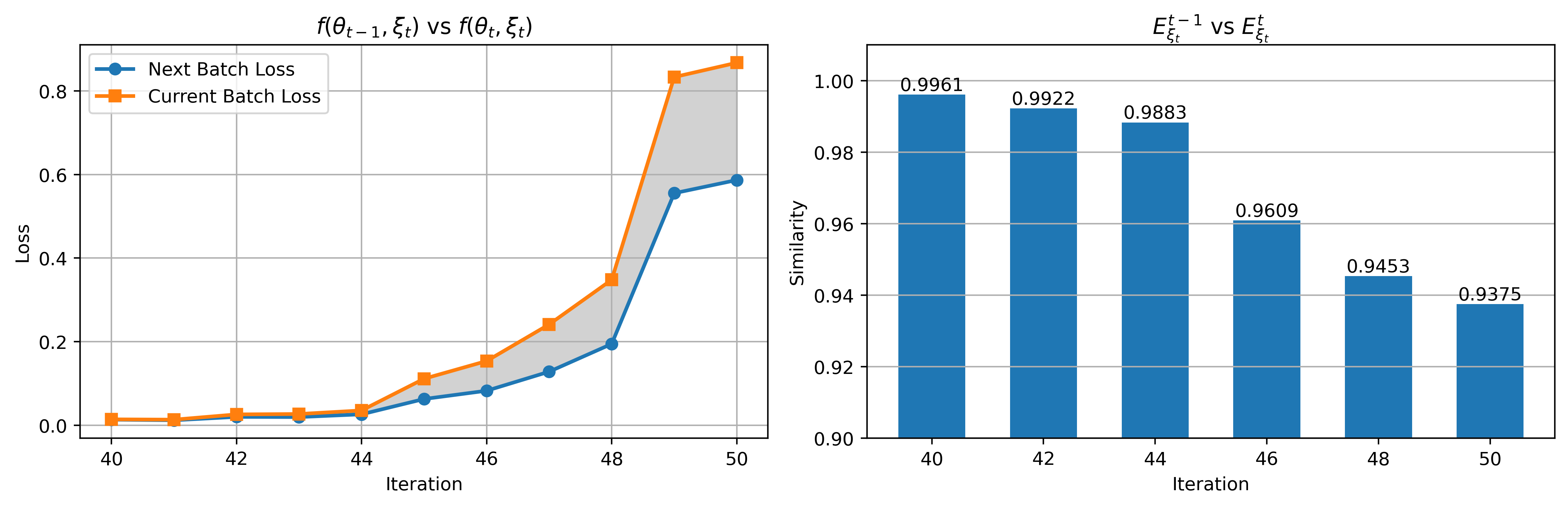
技术框架:EGUP框架主要包含以下几个关键模块:1) 样本间纠缠模块:计算遗忘样本与保留知识之间的语义相似度,并根据相似度调整非学习强度。2) 样本内纠缠模块:跟踪每个遗忘样本在非学习过程中的表示变化,动态调整其非学习努力。3) 代理约束模块:通过一个代理模型来近似非学习后的模型输出,形成一个参考边界。整体流程是,在每次迭代中,首先利用纠缠模块调整非学习强度,然后根据调整后的强度进行非学习,最后利用代理约束来规范非学习过程。
关键创新:EGUP的关键创新在于其纠缠引导和代理约束机制。纠缠引导能够自适应地调整非学习强度,避免对无关知识造成影响,而代理约束则为非学习过程提供了一个参考边界,防止过度遗忘。与现有方法相比,EGUP能够更精确地控制非学习过程,从而在非学习-效用权衡方面取得更好的效果。
关键设计:在样本间纠缠模块中,可以使用余弦相似度等方法来计算样本之间的语义相似度。在样本内纠缠模块中,可以跟踪样本表示的L2范数变化。代理约束可以通过训练一个小型模型来近似非学习后的模型输出。损失函数可以结合基于梯度的非学习目标、纠缠引导项和代理约束项。具体的参数设置需要根据具体的LLM和数据集进行调整。
🖼️ 关键图片

📊 实验亮点
EGUP在TOFU和MUSE基准测试中表现出色,在多个LLM上实现了非学习-效用权衡的一致改进。实验结果表明,EGUP能够显著降低非学习对模型效用的影响,并使模型性能接近重新训练的模型。具体的数据提升幅度取决于具体的LLM和数据集,但总体趋势是EGUP能够有效缓解过度遗忘问题。
🎯 应用场景
该研究成果可应用于各种需要数据删除的场景,例如保护用户隐私、遵守法律法规、移除版权内容等。通过更精确地控制非学习过程,可以减少对模型效用的损害,提高模型的鲁棒性,并降低隐私泄露的风险。该技术在金融、医疗、法律等敏感数据处理领域具有重要的应用价值。
📄 摘要(原文)
Large language models (LLMs) are trained on massive datasets that may include private or copyrighted content. Due to growing privacy and ownership concerns, data owners may request the removal of their data from trained models. Machine unlearning provides a practical solution by removing the influence of specific data without full retraining. However, most existing methods still suffer from over-unlearning due to the lack of a principled mechanism to regulate the forgetting boundary, leading to unnecessary utility degradation and heightened privacy and robustness risks. In this work, we propose EGUP (Entanglement-Guided Unlearning with Proxy Constraint), a novel framework that leverages entanglement and proxy constraint to guide the unlearning process while mitigating over-unlearning. Within each iteration, EGUP employs inter-sample entanglement to adaptively reweight the unlearning strength, assigning greater unlearning efforts to forget samples that are semantically closer to retained knowledge. Across iterations, EGUP leverages intra-sample entanglement to track the representation shift of each forget sample and dynamically adjust its unlearning effort. In addition, we incorporate a proxy constraint that approximates the model's expected outputs after unlearning, forming a reference boundary that softly regularizes the unlearning process. EGUP is compatible with existing gradient-based objectives and serves as a plug-and-play enhancement. We evaluate EGUP on the TOFU and MUSE benchmarks, demonstrating consistent improvements in the unlearning-utility trade-off across multiple LLMs. Moreover, EGUP achieves performance close to the retrained model while remaining scalable and robust.