Rethinking Transformer Connectivity: TLinFormer, A Path to Exact, Full Context-Aware Linear Attention
作者: Zhongpan Tang
分类: cs.LG
发布日期: 2025-08-28
💡 一句话要点
TLinFormer:一种精确且具备完整上下文感知能力的线性注意力机制,解决Transformer长序列瓶颈。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 线性注意力 Transformer 长序列建模 高效计算 上下文感知
📋 核心要点
- Transformer自注意力机制在处理长序列时面临计算复杂度瓶颈,限制了其应用。
- TLinFormer通过重新配置神经元连接模式,实现了线性复杂度的精确注意力计算,并保持完整上下文感知。
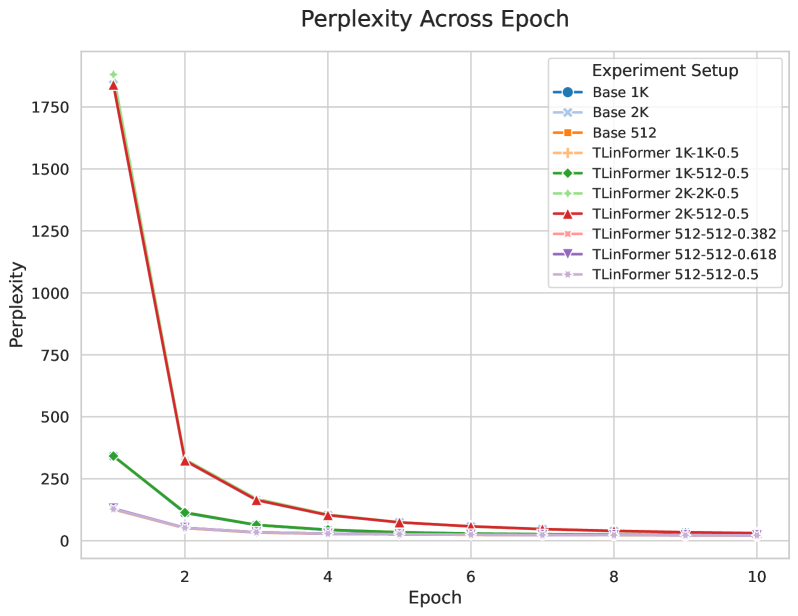
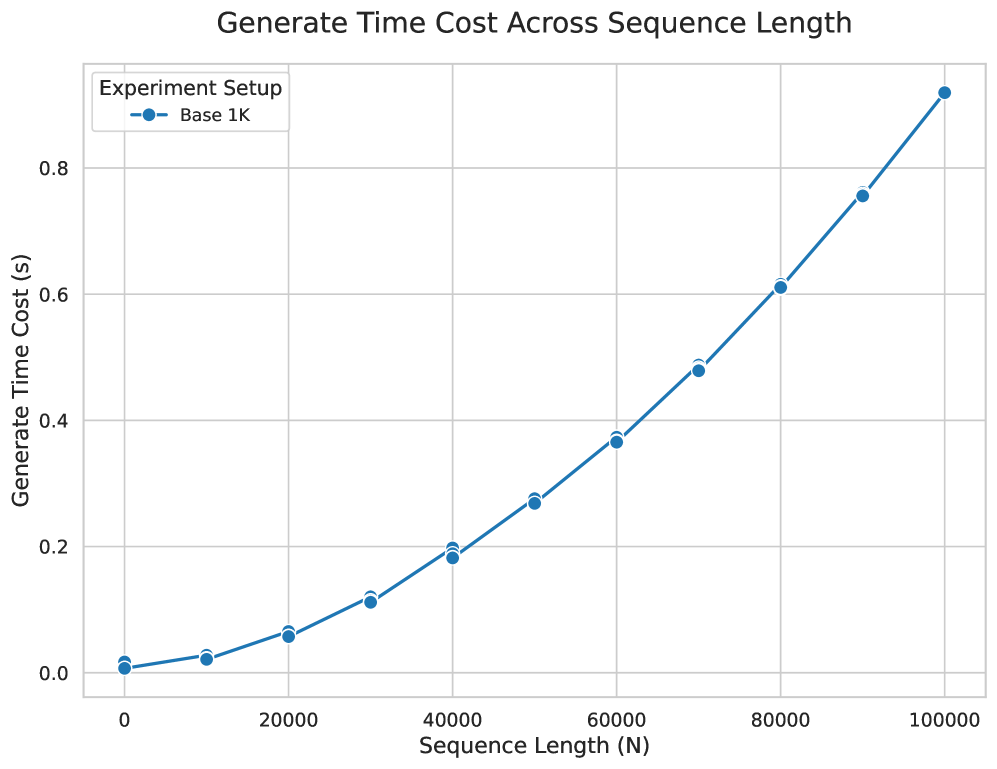
- 实验表明,TLinFormer在长序列推理任务中,显著提升了推理速度、KV缓存效率和内存占用。
📝 摘要(中文)
Transformer架构已成为现代人工智能的基石,但其核心的自注意力机制存在复杂度瓶颈,计算复杂度随序列长度呈二次方增长,严重限制了其在长序列任务中的应用。为了解决这一挑战,现有的线性注意力方法通常依赖于与数据无关的核近似或限制性的上下文选择,从而牺牲模型性能。本文回归连接主义的第一性原理,从信息流的拓扑结构出发,提出了一种新的线性注意力架构——TLinFormer。通过重新配置神经元连接模式,TLinFormer实现了严格的线性复杂度,同时计算精确的注意力分数,并确保信息流保持对完整历史上下文的感知。这种设计旨在弥合现有高效注意力方法和标准注意力之间的性能差距。通过一系列实验,我们系统地评估了TLinFormer在长序列推理任务中相对于标准Transformer基线的性能。结果表明,TLinFormer在推理延迟、KV缓存效率、内存占用和整体加速等关键指标上表现出压倒性的优势。
🔬 方法详解
问题定义:Transformer的自注意力机制在处理长序列时,计算复杂度为O(N^2),其中N是序列长度。这导致了在长序列任务中,计算资源消耗巨大,推理速度慢,成为一个显著的瓶颈。现有线性注意力方法试图降低复杂度,但通常以牺牲模型性能为代价,例如通过核近似或限制上下文选择,导致信息损失。
核心思路:TLinFormer的核心思路是重新设计Transformer中神经元的连接模式,使其能够在保持完整上下文感知的前提下,实现线性复杂度的注意力计算。通过改变信息流的拓扑结构,避免了传统自注意力机制中每个token都需要与其他所有token进行交互的模式。
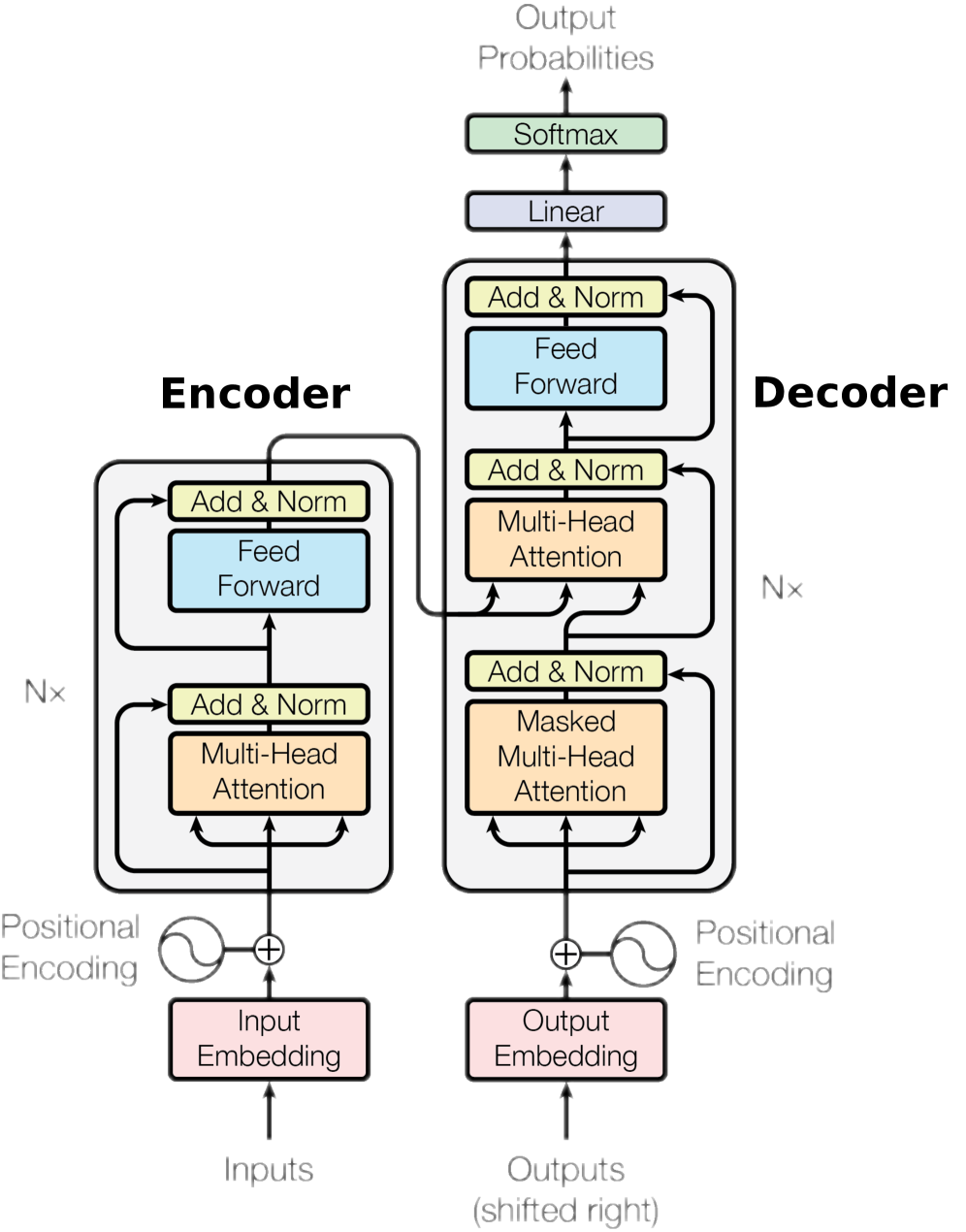
技术框架:TLinFormer沿用了Transformer的基本架构,包括多头注意力机制和前馈神经网络。主要的改变在于自注意力层的实现方式。TLinFormer通过特定的连接模式,将query、key和value的计算复杂度降低到线性级别。整体流程与标准Transformer类似,但内部的注意力计算方式不同。
关键创新:TLinFormer的关键创新在于其神经元连接模式的重新配置,实现了在计算精确注意力分数的同时,保证信息流对完整历史上下文的感知。与现有线性注意力方法不同,TLinFormer不依赖于任何近似或上下文限制,从而避免了信息损失。
关键设计:TLinFormer的具体连接模式细节未知,论文中可能涉及特定的矩阵分解或变换方法来实现线性复杂度。损失函数和训练方式与标准Transformer类似,但可能需要针对新的连接模式进行微调。具体的网络结构细节需要在论文中进一步查找。
🖼️ 关键图片
📊 实验亮点
论文实验结果表明,TLinFormer在长序列推理任务中,相较于标准Transformer基线,在推理延迟、KV缓存效率、内存占用和整体加速等方面表现出显著优势。具体的性能数据和提升幅度需要在论文中进一步查找,但整体趋势表明TLinFormer在效率方面具有明显优势。
🎯 应用场景
TLinFormer在长文本处理、语音识别、视频理解、基因组分析等需要处理长序列数据的领域具有广泛的应用前景。其高效的计算能力和较低的内存占用,使得在资源受限的设备上部署大型Transformer模型成为可能。未来,TLinFormer有望推动人工智能在更多领域的应用,并加速相关技术的发展。
📄 摘要(原文)
The Transformer architecture has become a cornerstone of modern artificial intelligence, but its core self-attention mechanism suffers from a complexity bottleneck that scales quadratically with sequence length, severely limiting its application in long-sequence tasks. To address this challenge, existing linear attention methods typically sacrifice model performance by relying on data-agnostic kernel approximations or restrictive context selection. This paper returns to the first principles of connectionism, starting from the topological structure of information flow, to introduce a novel linear attention architecture-\textbf{TLinFormer}. By reconfiguring neuron connection patterns, TLinFormer achieves strict linear complexity while computing exact attention scores and ensuring information flow remains aware of the full historical context. This design aims to bridge the performance gap prevalent between existing efficient attention methods and standard attention. Through a series of experiments, we systematically evaluate the performance of TLinFormer against a standard Transformer baseline on long-sequence inference tasks. The results demonstrate that TLinFormer exhibits overwhelming advantages in key metrics such as \textbf{inference latency}, \textbf{KV cache efficiency}, \textbf{memory footprint}, and \textbf{overall speedup}.