CALR: Corrective Adaptive Low-Rank Decomposition for Efficient Large Language Model Layer Compression
作者: Muchammad Daniyal Kautsar, Afra Majida Hariono, Widyawan, Syukron Abu Ishaq Alfarozi, Kuntpong Woraratpanya
分类: cs.LG, cs.AI
发布日期: 2025-08-21 (更新: 2025-08-26)
备注: Submitted to IEEE Transactions on Artificial Intelligence. This is the preprint version, not peer-reviewed. The final version may differ after peer review. (11 pages, 3 figures)
💡 一句话要点
CALR:一种用于高效大语言模型层压缩的校正自适应低秩分解方法
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型压缩 低秩分解 奇异值分解 模型优化 知识蒸馏
📋 核心要点
- 现有大语言模型压缩方法,如基于SVD的低秩分解,虽然能减少参数,但忽略了压缩过程中的功能信息损失,导致模型性能显著下降。
- CALR方法通过引入一个可学习的低秩校正模块,显式地学习并补偿SVD压缩带来的功能残差误差,从而更好地保留模型性能。
- 实验结果表明,CALR在多种模型上实现了显著的参数压缩,同时保持了较高的模型性能,优于其他先进的压缩方法。
📝 摘要(中文)
大型语言模型(LLMs)由于其庞大的规模和计算需求,带来了显著的部署挑战。模型压缩技术对于使这些模型在资源受限的环境中实际应用至关重要。一种重要的压缩策略是通过奇异值分解(SVD)进行低秩分解,通过近似权重矩阵来减少模型参数。然而,标准SVD侧重于最小化矩阵重构误差,通常导致模型功能性能的显著损失。这种性能下降的发生是因为现有方法没有充分校正压缩过程中损失的功能信息。为了解决这个差距,我们引入了校正自适应低秩分解(CALR),这是一种双组件压缩方法。CALR将SVD压缩层的主路径与一个并行的、可学习的、低秩的校正模块相结合,该模块经过显式训练以恢复功能残差误差。我们在SmolLM2-135M、Qwen3-0.6B和Llama-3.2-1B上的实验评估表明,CALR可以将参数数量减少26.93%到51.77%,同时保留原始模型59.45%到90.42%的性能,始终优于LaCo、ShortGPT和LoSparse。CALR的成功表明,将功能信息损失视为可学习的信号是一种非常有效的压缩范式。这种方法能够创建更小、更高效的LLM,从而提高它们在实际应用中的可访问性和实际部署。
🔬 方法详解
问题定义:现有基于SVD的低秩分解方法在压缩大语言模型时,主要关注矩阵重构误差的最小化,而忽略了压缩过程中损失的功能信息。这导致压缩后的模型在下游任务上的性能显著下降,无法有效平衡模型大小和性能。
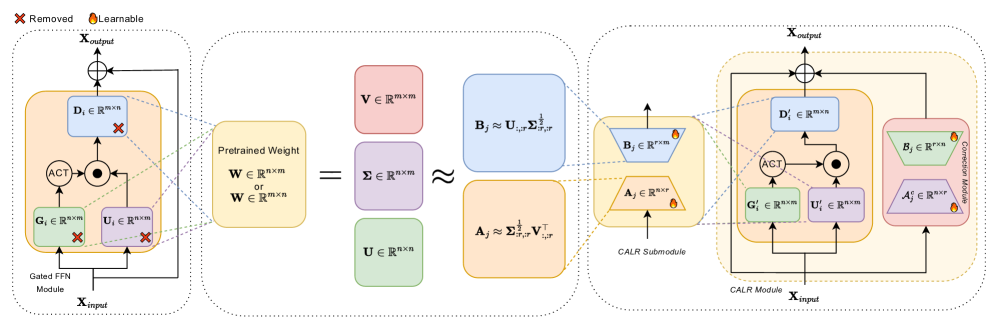
核心思路:CALR的核心思路是将压缩过程中的功能信息损失视为一个可学习的信号。通过引入一个并行的、可学习的低秩校正模块,显式地学习并补偿SVD压缩带来的功能残差误差。这样可以在减少模型参数的同时,更好地保留原始模型的功能性能。
技术框架:CALR包含两个主要组成部分:一个通过SVD压缩的主路径和一个并行的、可学习的低秩校正模块。首先,使用SVD对原始模型中的权重矩阵进行低秩分解,得到压缩后的主路径。然后,将主路径的输出与校正模块的输出相加,得到最终的输出。校正模块通过训练来学习补偿SVD压缩带来的功能损失。
关键创新:CALR的关键创新在于将功能信息损失视为可学习的信号,并设计了一个专门的校正模块来学习和补偿这种损失。与传统的低秩分解方法不同,CALR不仅关注矩阵重构误差,更关注模型的功能性能。
关键设计:校正模块采用低秩结构,以减少额外的参数引入。损失函数的设计目标是最小化压缩后模型的输出与原始模型输出之间的差异,从而使校正模块能够有效地学习功能残差。具体来说,可以使用L2损失或余弦相似度损失来衡量输出之间的差异。校正模块的秩的大小是一个重要的超参数,需要根据具体的模型和任务进行调整。
🖼️ 关键图片


📊 实验亮点
CALR在SmolLM2-135M、Qwen3-0.6B和Llama-3.2-1B等模型上进行了评估,结果表明,CALR可以将参数数量减少26.93%到51.77%,同时保留原始模型59.45%到90.42%的性能。CALR始终优于LaCo、ShortGPT和LoSparse等基线方法,证明了其在模型压缩方面的有效性。
🎯 应用场景
CALR方法可以应用于各种需要部署在资源受限环境中的大型语言模型,例如移动设备、嵌入式系统和边缘计算设备。通过减少模型大小和计算需求,CALR可以使这些模型在这些平台上更高效地运行,从而实现更广泛的应用,例如本地化的自然语言处理、智能助手和实时翻译。
📄 摘要(原文)
Large Language Models (LLMs) present significant deployment challenges due to their immense size and computational requirements. Model compression techniques are essential for making these models practical for resource-constrained environments. A prominent compression strategy is low-rank factorization via Singular Value Decomposition (SVD) to reduce model parameters by approximating weight matrices. However, standard SVD focuses on minimizing matrix reconstruction error, often leading to a substantial loss of the model's functional performance. This performance degradation occurs because existing methods do not adequately correct for the functional information lost during compression. To address this gap, we introduce Corrective Adaptive Low-Rank Decomposition (CALR), a two-component compression approach. CALR combines a primary path of SVD-compressed layers with a parallel, learnable, low-rank corrective module that is explicitly trained to recover the functional residual error. Our experimental evaluation on SmolLM2-135M, Qwen3-0.6B, and Llama-3.2-1B, demonstrates that CALR can reduce parameter counts by 26.93% to 51.77% while retaining 59.45% to 90.42% of the original model's performance, consistently outperforming LaCo, ShortGPT, and LoSparse. CALR's success shows that treating functional information loss as a learnable signal is a highly effective compression paradigm. This approach enables the creation of significantly smaller, more efficient LLMs, advancing their accessibility and practical deployment in real-world applications.