Communication Efficient LLM Pre-training with SparseLoCo
作者: Amir Sarfi, Benjamin Thérien, Joel Lidin, Eugene Belilovsky
分类: cs.LG
发布日期: 2025-08-21 (更新: 2025-11-05)
备注: 20 pages, 14 tables, 2 figures
💡 一句话要点
SparseLoCo:一种通信高效的LLM预训练方法,实现极高稀疏度并超越DiLoCo
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 通信高效训练 LLM预训练 稀疏化 量化 误差反馈 分布式训练 Top-k稀疏
📋 核心要点
- 现有分布式训练方法在带宽受限环境下训练LLM时,虽降低了通信频率,但仍需传输完整梯度,造成通信瓶颈,且性能略低于AdamW DDP基线。
- SparseLoCo通过误差反馈、Top-k稀疏化和2-bit量化,在极低稀疏度下实现高效通信,并观察到稀疏聚合能提升模型性能。
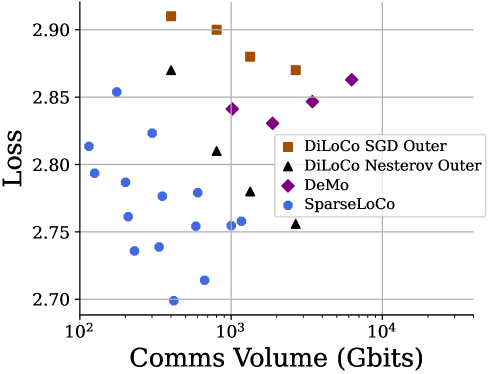
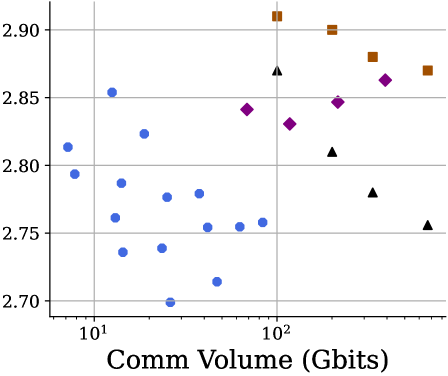
- 实验证明,在通信受限的LLM训练中,SparseLoCo在性能和通信成本上均优于现有方法,包括超越全精度DiLoCo。
📝 摘要(中文)
本文提出SparseLoCo,一种通信高效的LLM训练算法,它有效利用了带有Top-k稀疏化和2-bit量化的误差反馈,实现了低至1-3%的极高稀疏度,同时性能优于全精度DiLoCo。核心观察是,外部动量可以通过误差反馈累加器结合激进的稀疏性进行局部近似,并且稀疏聚合实际上可以提高模型性能。在各种通信受限的LLM训练环境中,经验证表明SparseLoCo在性能和通信成本方面都提供了显著的优势。
🔬 方法详解
问题定义:在分布式环境下预训练大型语言模型(LLM)时,通信带宽成为瓶颈。即使采用降低通信频率的方法,仍然需要传输完整的梯度信息,这在跨数据中心或互联网等带宽受限的场景下效率低下。此外,现有方法在降低通信量的同时,可能会牺牲模型性能。
核心思路:SparseLoCo的核心思路是利用梯度的稀疏性,只传输梯度中最重要的部分(Top-k),并结合误差反馈机制来补偿稀疏化带来的信息损失。同时,通过低比特量化进一步压缩通信量。论文还观察到,适当的稀疏聚合实际上可以提高模型性能。
技术框架:SparseLoCo算法主要包含以下几个阶段:1) 本地梯度计算:每个worker节点独立计算本地梯度。2) 稀疏化和量化:每个worker节点对本地梯度进行Top-k稀疏化和2-bit量化。3) 梯度聚合:worker节点将稀疏化和量化后的梯度发送到中心节点进行聚合。4) 误差反馈:中心节点维护一个误差累加器,用于补偿稀疏化带来的信息损失。5) 模型更新:中心节点使用聚合后的梯度更新模型,并将更新后的模型参数发送回worker节点。
关键创新:SparseLoCo的关键创新在于将Top-k稀疏化、低比特量化和误差反馈机制有效地结合起来,实现了极高的稀疏度(1-3%),同时保持甚至提高了模型性能。此外,论文还提出了稀疏聚合可以提高模型性能的观察,这与传统的认知有所不同。
关键设计:SparseLoCo的关键设计包括:1) Top-k稀疏化的比例k的选择,需要在通信效率和模型性能之间进行权衡。2) 2-bit量化的具体实现方式,例如使用随机量化或均匀量化。3) 误差反馈累加器的更新策略,例如使用动量或Adam等优化器。4) 稀疏聚合的具体实现方式,例如使用加权平均或中值聚合。
🖼️ 关键图片

📊 实验亮点
SparseLoCo在通信受限的LLM训练环境中表现出色,实现了1-3%的极高稀疏度,显著降低了通信成本。更重要的是,SparseLoCo在性能上超越了全精度DiLoCo,证明了稀疏聚合的有效性。这些实验结果表明SparseLoCo是一种极具潜力的通信高效LLM训练方法。
🎯 应用场景
SparseLoCo适用于各种通信受限的LLM预训练场景,例如跨数据中心、互联网以及边缘设备上的分布式训练。该方法可以显著降低通信成本,提高训练效率,并支持更大规模的模型训练。此外,该方法还可以应用于其他需要通信高效的分布式机器学习任务。
📄 摘要(原文)
Communication-efficient distributed training algorithms have received considerable interest recently due to their benefits for training Large Language Models (LLMs) in bandwidth-constrained settings, such as across datacenters and over the internet. Despite reducing communication frequency, these methods still typically require communicating a full copy of the model's gradients-resulting in a communication bottleneck even for cross-datacenter links. Furthermore, they can slightly degrade performance compared to a naive AdamW DDP baseline. While quantization is often applied to reduce the pseudo-gradient's size, in the context of LLM pre-training, existing approaches have been unable to additionally leverage sparsification and have obtained limited quantization. In this work, we introduce SparseLoCo, a communication-efficient training algorithm for LLMs that effectively leverages error feedback with Top-k sparsification and 2-bit quantization to reach extreme sparsity as low as 1-3% while outperforming full-precision DiLoCo. Our key observations are that outer momentum can be locally approximated by an error feedback accumulator combined with aggressive sparsity, and that sparse aggregation can actually improve model performance. We empirically demonstrate in a range of communication-constrained LLM training settings that SparseLoCo provides significant benefits in both performance and communication cost.