Reliable Unlearning Harmful Information in LLMs with Metamorphosis Representation Projection
作者: Chengcan Wu, Zeming Wei, Huanran Chen, Yinpeng Dong, Meng Sun
分类: cs.LG, cs.AI
发布日期: 2025-08-21
备注: 10 pages, 9 figures, Under review as a full paper at AAAI 2026. A preliminary version is under review at the NeurIPS 2025 Workshop on Reliable ML from Unreliable Data
🔗 代码/项目: GITHUB
💡 一句话要点
提出基于变质表示投影的LLM不可逆卸载方法,提升安全性和防御重学习攻击能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 机器卸载 不可逆投影 模型安全性 重学习攻击
📋 核心要点
- 现有LLM卸载方法仅通过参数训练抑制有害数据激活,无法彻底消除模型内部的信息痕迹,导致卸载效果不佳且易受重学习攻击。
- 论文提出变质表示投影(MRP)方法,利用不可逆投影特性,在网络层隐藏状态空间中进行投影变换,彻底消除有害信息。
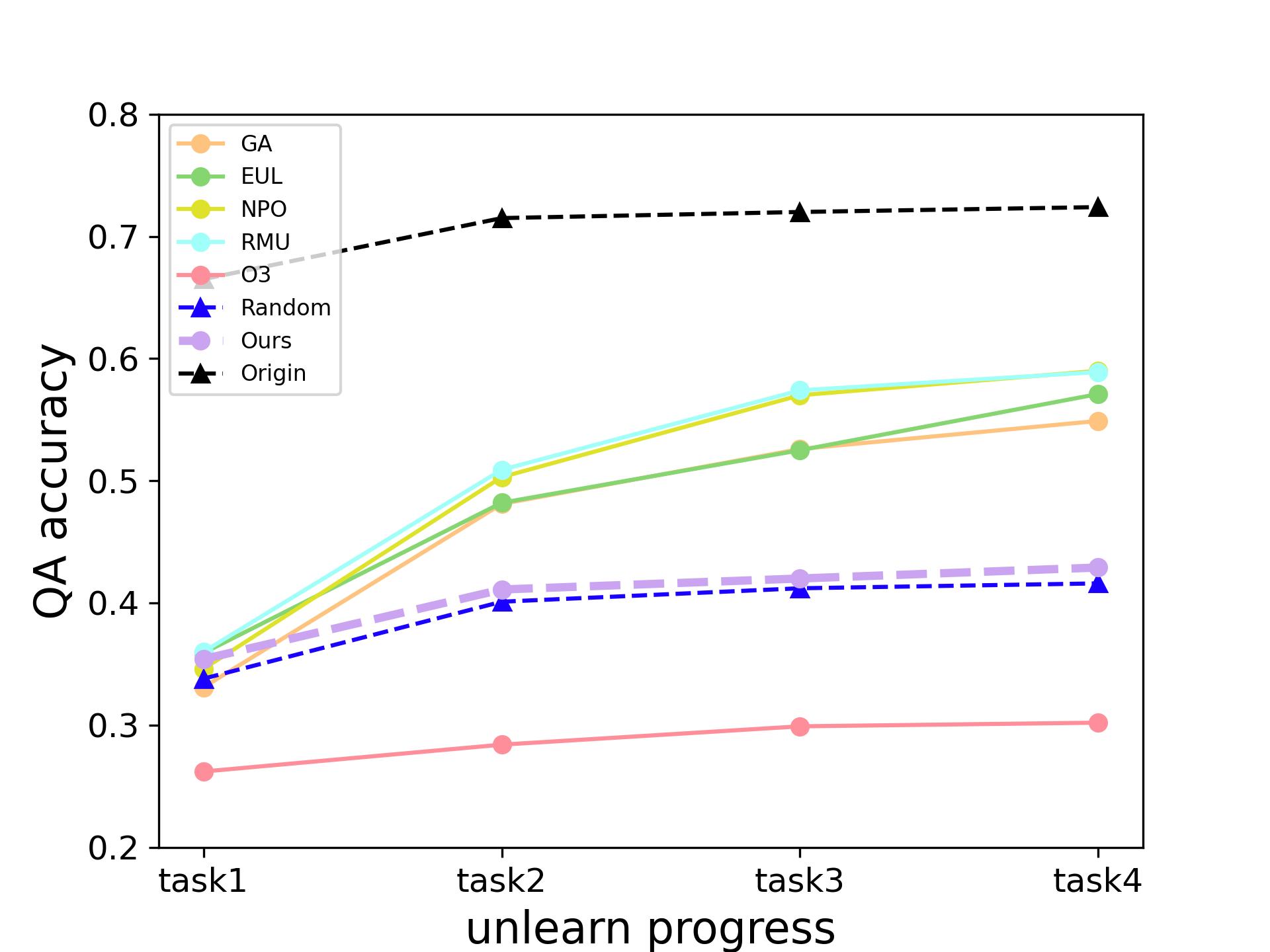
- 实验结果表明,MRP方法能够有效进行连续卸载,成功防御重学习攻击,并在卸载有效性和自然性能保持方面达到SOTA。
📝 摘要(中文)
大型语言模型(LLMs)在各个领域和任务中表现出令人印象深刻的性能,但其安全性问题日益严重。由于模型可能在内部存储不安全知识,机器卸载已成为确保模型安全性的代表性范例。现有方法采用各种训练技术,如梯度上升和负偏好优化,试图消除不良数据对目标模型的影响。然而,这些方法仅仅通过参数训练来抑制不良数据的激活,而没有完全消除其在模型中的信息痕迹。这种根本性限制使得难以实现有效的连续卸载,并使这些方法容易受到重学习攻击。为了克服这些挑战,我们提出了一种变质表示投影(MRP)方法,该方法率先将不可逆投影特性应用于机器卸载。通过在特定网络层的隐藏状态空间中实现投影变换,我们的方法有效地消除了有害信息,同时保留了有用的知识。实验结果表明,我们的方法能够实现有效的连续卸载,并成功防御重学习攻击,在卸载有效性方面实现了最先进的性能,同时保持了自然性能。我们的代码可在https://github.com/ChengcanWu/MRP中找到。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLMs)中存在的有害信息卸载问题。现有方法,如梯度上升和负偏好优化,主要通过调整模型参数来抑制有害信息的影响,但无法彻底消除这些信息在模型内部的痕迹。这导致卸载效果不佳,并且模型容易受到重学习攻击,即在卸载后,模型又重新学习到被卸载的有害信息。
核心思路:论文的核心思路是利用不可逆的投影变换,将有害信息从模型的隐藏状态空间中彻底移除。通过在特定网络层的隐藏状态空间中进行投影,可以将有害信息投影到一个低维子空间,从而有效地消除其影响,同时保留对模型性能至关重要的有用信息。这种不可逆性使得模型难以重新学习到被卸载的信息。
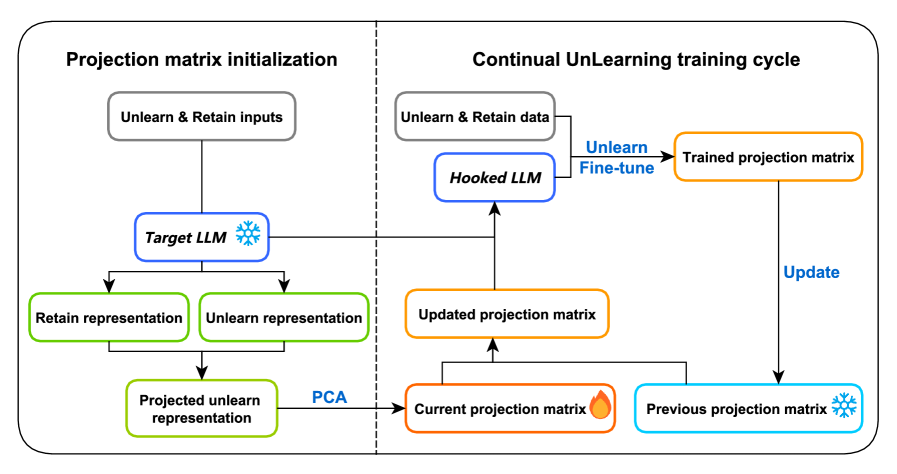
技术框架:MRP方法主要包含以下几个阶段:1) 选择需要进行卸载的网络层;2) 确定有害信息在隐藏状态空间中的表示;3) 设计并应用不可逆的投影变换,将有害信息投影到低维子空间;4) 对模型进行微调,以恢复因投影变换而可能损失的性能。整体流程是在不影响模型原有能力的前提下,尽可能地消除有害信息。
关键创新:该方法最重要的创新点在于将不可逆投影的概念引入到机器卸载领域。与传统的参数调整方法不同,MRP方法直接作用于模型的隐藏状态空间,通过投影变换彻底消除有害信息,而不是仅仅抑制其激活。这种方法从根本上解决了现有方法无法彻底卸载有害信息的问题,提高了卸载的有效性和安全性。
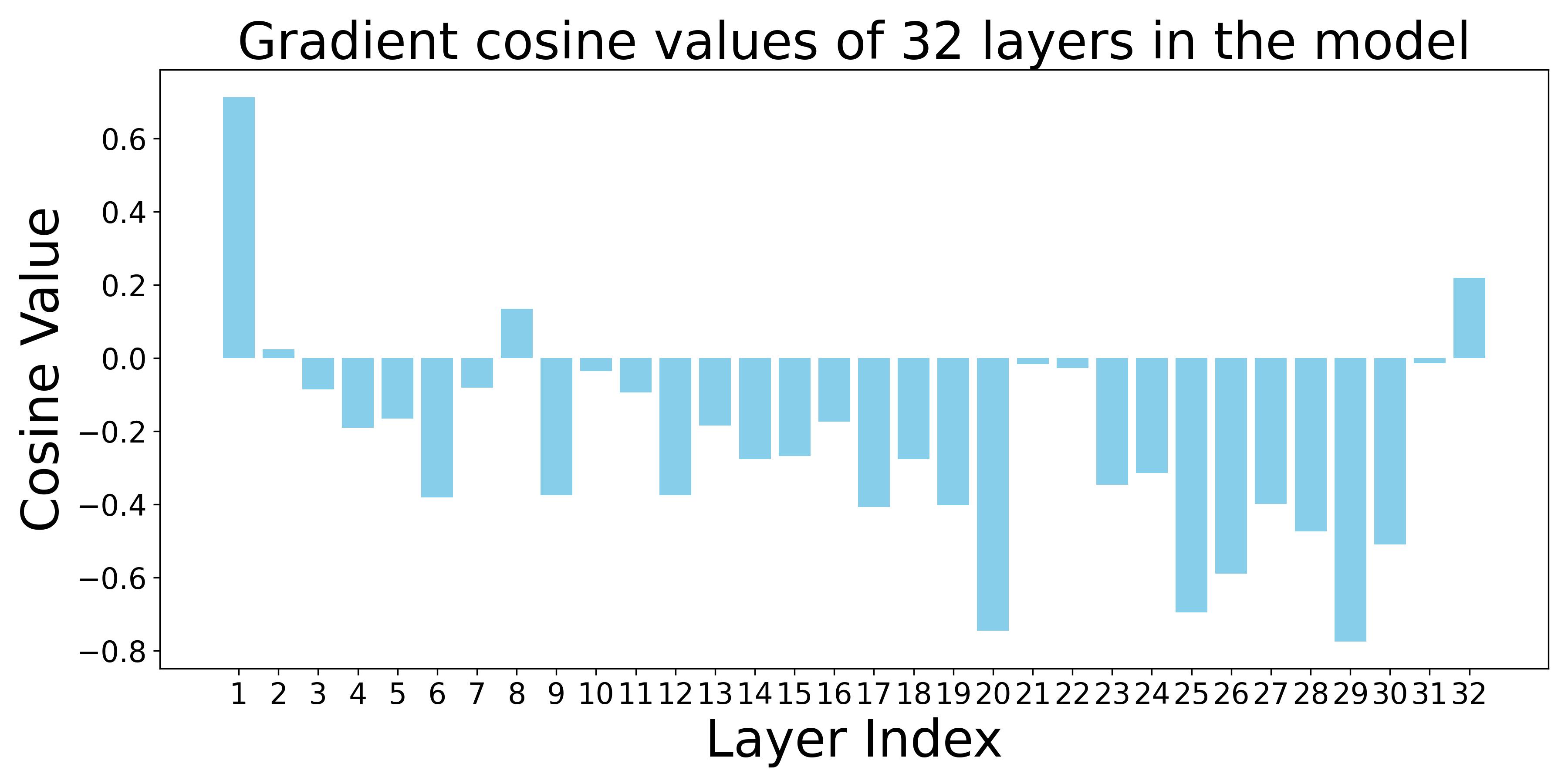
关键设计:关键设计包括:1) 选择合适的网络层进行投影,通常选择包含较多有害信息的层;2) 设计合适的投影矩阵,确保能够有效地消除有害信息,同时尽可能保留有用信息;3) 使用微调技术来恢复因投影变换而可能损失的性能。损失函数的设计需要平衡卸载效果和模型性能,例如可以使用对抗损失来进一步提高卸载的鲁棒性。
🖼️ 关键图片
📊 实验亮点
实验结果表明,MRP方法在卸载有害信息方面取得了显著的性能提升,能够有效防御重学习攻击。与现有方法相比,MRP方法在卸载有效性方面达到了SOTA,同时保持了良好的自然性能。具体而言,MRP方法在卸载有害信息的同时,对模型原有性能的影响较小,并且能够有效地防止模型重新学习到被卸载的信息。
🎯 应用场景
该研究成果可广泛应用于各种需要确保模型安全性的场景,例如:过滤LLM中的偏见、仇恨言论和不当内容;保护用户隐私,防止模型泄露敏感信息;提高LLM在安全敏感领域的应用可靠性,如金融、医疗等。此外,该方法还可以用于防御针对LLM的对抗性攻击,提高模型的鲁棒性。
📄 摘要(原文)
While Large Language Models (LLMs) have demonstrated impressive performance in various domains and tasks, concerns about their safety are becoming increasingly severe. In particular, since models may store unsafe knowledge internally, machine unlearning has emerged as a representative paradigm to ensure model safety. Existing approaches employ various training techniques, such as gradient ascent and negative preference optimization, in attempts to eliminate the influence of undesired data on target models. However, these methods merely suppress the activation of undesired data through parametric training without completely eradicating its informational traces within the model. This fundamental limitation makes it difficult to achieve effective continuous unlearning, rendering these methods vulnerable to relearning attacks. To overcome these challenges, we propose a Metamorphosis Representation Projection (MRP) approach that pioneers the application of irreversible projection properties to machine unlearning. By implementing projective transformations in the hidden state space of specific network layers, our method effectively eliminates harmful information while preserving useful knowledge. Experimental results demonstrate that our approach enables effective continuous unlearning and successfully defends against relearning attacks, achieving state-of-the-art performance in unlearning effectiveness while preserving natural performance. Our code is available in https://github.com/ChengcanWu/MRP.