Learning ECG Representations via Poly-Window Contrastive Learning
作者: Yi Yuan, Joseph Van Duyn, Runze Yan, Zhuoyi Huang, Sulaiman Vesal, Sergey Plis, Xiao Hu, Gloria Hyunjung Kwak, Ran Xiao, Alex Fedorov
分类: cs.LG, eess.SP
发布日期: 2025-08-21
备注: This work has been accepted for publication in IEEE-EMBS International Conference on Biomedical and Health Informatics 2025. The final published version will be available via IEEE Xplore
💡 一句话要点
提出基于多窗口对比学习的ECG表征方法,提升心电信号分析效率与性能。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 心电图分析 对比学习 自监督学习 时间序列分析 表征学习
📋 核心要点
- 现有ECG分析的深度学习模型受限于标注数据不足,且未能充分利用ECG信号的时序结构信息。
- 提出多窗口对比学习框架,通过提取多个时间窗口构建正样本对,学习时间不变且生理意义的特征。
- 实验结果表明,该方法在多标签分类任务中性能优于传统方法,并显著减少了预训练所需的时间。
📝 摘要(中文)
心电图(ECG)分析是心血管疾病诊断的基础,但深度学习模型的性能常受限于标注数据的匮乏。自监督对比学习已成为从无标签信号中学习鲁棒ECG表征的有效方法。然而,现有方法大多只生成成对增强视图,未能充分利用ECG记录丰富的时序结构。本文提出了一种多窗口对比学习框架,从每个ECG实例中提取多个时间窗口来构建正样本对,并通过统计量最大化它们的一致性。受慢特征分析原则的启发,该方法显式地鼓励模型学习在时间上不变且生理上有意义的特征。在PTB-XL数据集上的实验验证表明,多窗口对比学习在多标签超类分类中始终优于传统的双视图方法,实现了更高的AUROC(0.891 vs. 0.888)和F1分数(0.680 vs. 0.679),同时预训练epoch减少了四倍(32 vs. 128),总预训练时间减少了14.8%。
🔬 方法详解
问题定义:现有基于对比学习的ECG表征方法通常只使用成对增强视图,忽略了ECG信号丰富的时序结构,导致学习到的表征可能不够鲁棒,泛化能力受限。此外,训练所需的计算资源和时间成本也较高。
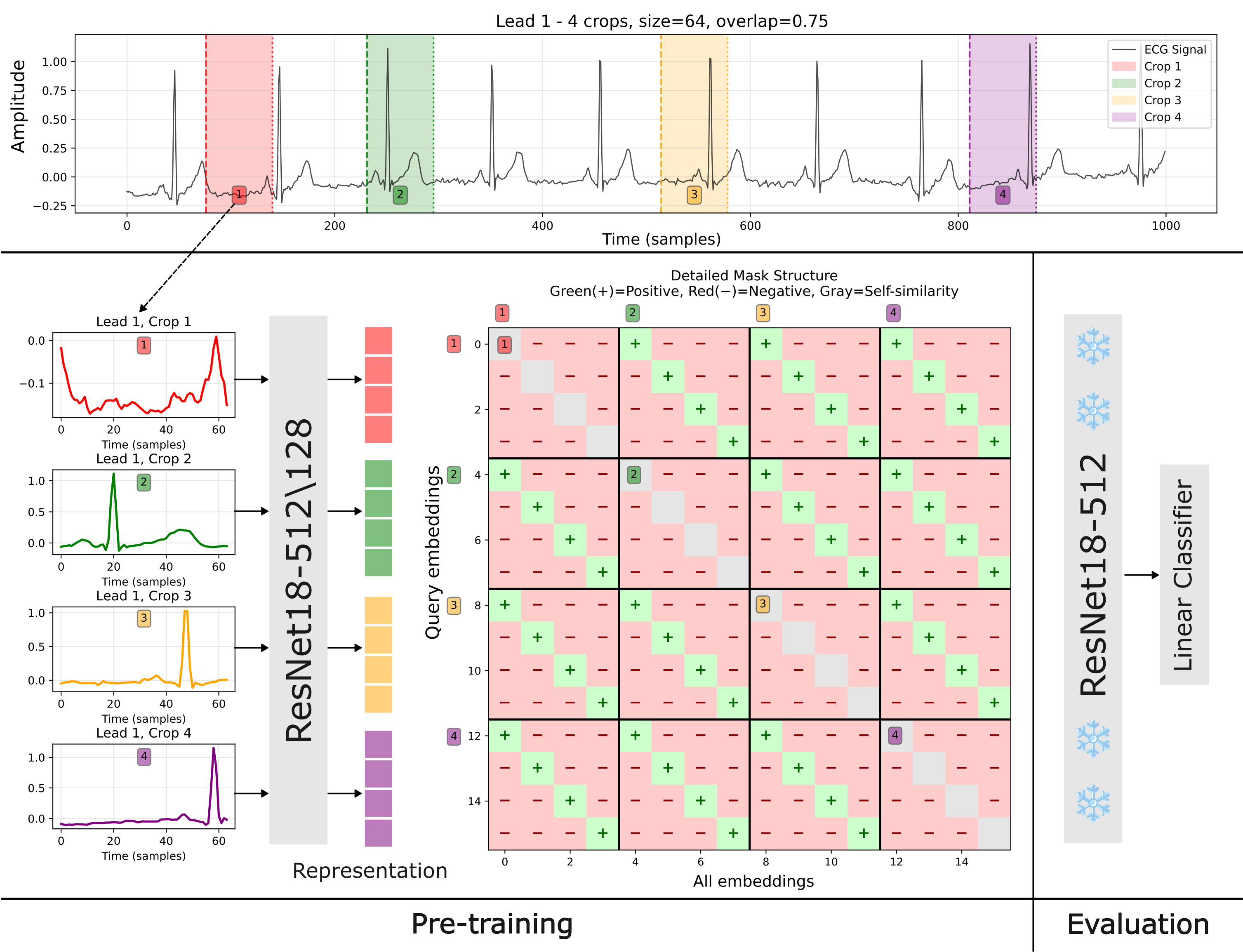
核心思路:核心思想是利用ECG信号的时序冗余性,通过从同一ECG实例中提取多个时间窗口,并将这些窗口视为正样本对,鼓励模型学习在不同时间窗口中保持一致的特征表示。这种方法借鉴了慢特征分析的思想,旨在提取时间上相对稳定的、具有生理意义的特征。
技术框架:该方法包含以下主要步骤:1) 数据预处理:对原始ECG信号进行必要的清洗和标准化。2) 多窗口提取:从每个ECG实例中随机或按照一定策略提取多个时间窗口。3) 特征编码:使用编码器(例如卷积神经网络)将每个时间窗口映射到低维特征向量。4) 对比学习:构建对比学习损失函数,鼓励来自同一ECG实例的不同时间窗口的特征向量尽可能相似,而与来自其他ECG实例的特征向量尽可能不同。5) 模型训练:通过优化对比学习损失函数,训练编码器,使其能够提取具有时间不变性的ECG表征。
关键创新:关键创新在于提出了多窗口对比学习的框架,将ECG信号的时序结构纳入考虑,从而能够学习到更鲁棒、更具生理意义的特征表示。与传统的双视图对比学习方法相比,该方法能够更有效地利用数据中的信息,提高模型的性能和泛化能力。
关键设计:在多窗口提取方面,可以采用随机采样或滑动窗口等策略。对比学习损失函数可以选择InfoNCE loss或其他常用的对比学习损失。编码器的网络结构可以根据具体任务进行选择,例如可以使用ResNet、Transformer等。此外,还可以引入一些正则化技术,例如权重衰减、dropout等,以防止过拟合。
🖼️ 关键图片


📊 实验亮点
在PTB-XL数据集上的实验结果表明,多窗口对比学习方法在多标签超类分类任务中取得了显著的性能提升,AUROC从0.888提升到0.891,F1分数从0.679提升到0.680。更重要的是,该方法在预训练epoch减少四倍的情况下,总预训练时间减少了14.8%。
🎯 应用场景
该研究成果可应用于心血管疾病的自动诊断、风险预测和患者监护。通过学习更鲁棒的ECG表征,可以提高诊断的准确性和效率,减少对人工标注数据的依赖。此外,该方法还可以推广到其他生物医学时间序列数据的分析,例如脑电图(EEG)和肌电图(EMG)。
📄 摘要(原文)
Electrocardiogram (ECG) analysis is foundational for cardiovascular disease diagnosis, yet the performance of deep learning models is often constrained by limited access to annotated data. Self-supervised contrastive learning has emerged as a powerful approach for learning robust ECG representations from unlabeled signals. However, most existing methods generate only pairwise augmented views and fail to leverage the rich temporal structure of ECG recordings. In this work, we present a poly-window contrastive learning framework. We extract multiple temporal windows from each ECG instance to construct positive pairs and maximize their agreement via statistics. Inspired by the principle of slow feature analysis, our approach explicitly encourages the model to learn temporally invariant and physiologically meaningful features that persist across time. We validate our approach through extensive experiments and ablation studies on the PTB-XL dataset. Our results demonstrate that poly-window contrastive learning consistently outperforms conventional two-view methods in multi-label superclass classification, achieving higher AUROC (0.891 vs. 0.888) and F1 scores (0.680 vs. 0.679) while requiring up to four times fewer pre-training epochs (32 vs. 128) and 14.8% in total wall clock pre-training time reduction. Despite processing multiple windows per sample, we achieve a significant reduction in the number of training epochs and total computation time, making our method practical for training foundational models. Through extensive ablations, we identify optimal design choices and demonstrate robustness across various hyperparameters. These findings establish poly-window contrastive learning as a highly efficient and scalable paradigm for automated ECG analysis and provide a promising general framework for self-supervised representation learning in biomedical time-series data.