SHLIME: Foiling adversarial attacks fooling SHAP and LIME
作者: Sam Chauhan, Estelle Duguet, Karthik Ramakrishnan, Hugh Van Deventer, Jack Kruger, Ranjan Subbaraman
分类: cs.LG, cs.CR
发布日期: 2025-08-14
备注: 7 pages, 7 figures
💡 一句话要点
SHLIME:通过对抗攻击揭示并防御针对SHAP和LIME的欺骗行为
🎯 匹配领域: 支柱一:机器人控制 (Robot Control)
关键词: 可解释性 对抗攻击 LIME SHAP 模型偏差 鲁棒性 集成学习
📋 核心要点
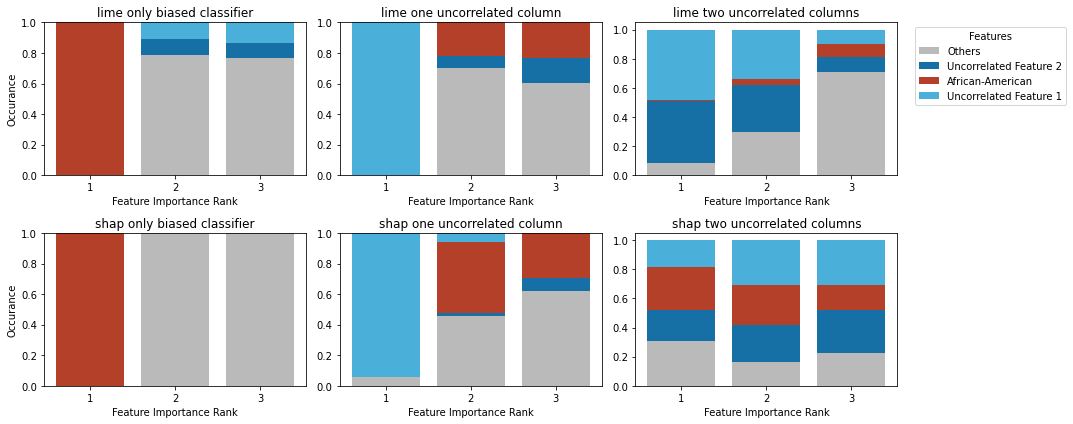
- LIME和SHAP等解释方法易受对抗攻击,可能掩盖模型中的有害偏见,影响模型公平性和可靠性。
- 论文提出一个模块化的测试框架,用于系统评估增强和集成解释方法在不同模型上的鲁棒性,抵抗偏差隐藏。
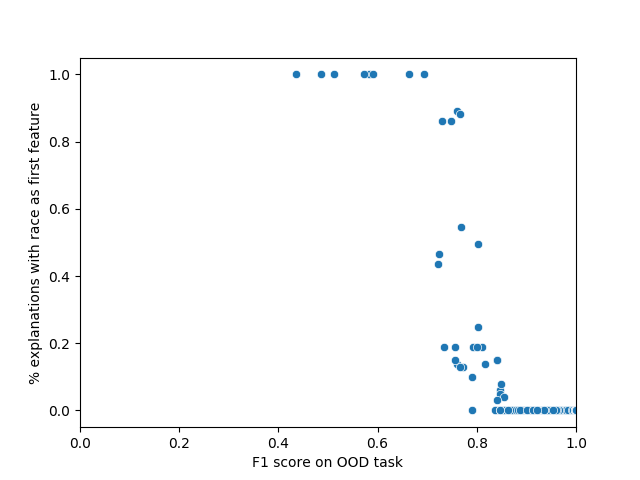
- 实验结果表明,特定的LIME/SHAP集成配置能显著提高偏差检测能力,增强高风险机器学习系统的透明度。
📝 摘要(中文)
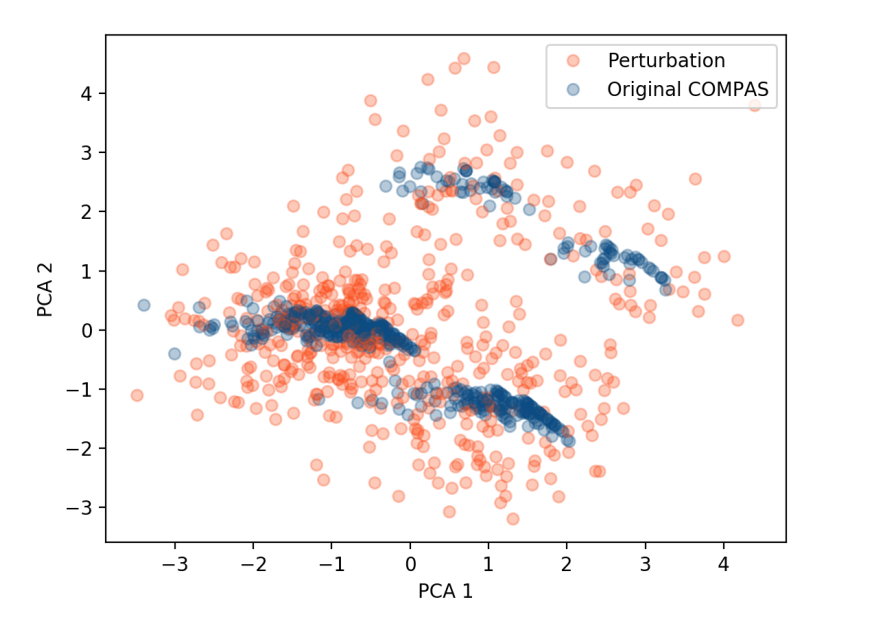
事后解释方法,如LIME和SHAP,为黑盒分类器提供可解释的洞察力,并越来越多地用于评估模型偏差和泛化能力。然而,这些方法容易受到对抗性操纵,可能隐藏有害的偏差。在Slack等人(2020)工作的基础上,我们研究了LIME和SHAP对有偏模型的敏感性,并评估了提高鲁棒性的策略。我们首先复制了原始的COMPAS实验,以验证先前的发现并建立基线。然后,我们引入了一个模块化测试框架,能够系统地评估增强和集成解释方法在不同性能的分类器上的表现。使用这个框架,我们评估了多种LIME/SHAP集成配置在分布外模型上的表现,并将它们抵抗偏差隐藏的能力与原始方法进行了比较。我们的结果确定了能够显著改善偏差检测的配置,突出了它们在提高高风险机器学习系统部署透明度方面的潜力。
🔬 方法详解
问题定义:LIME和SHAP等事后可解释性方法被广泛用于理解黑盒模型,但它们容易受到对抗攻击的操纵,攻击者可以通过精心设计的输入来改变解释结果,从而隐藏模型中存在的偏差。现有的防御方法往往缺乏系统性的评估和比较,难以确定最佳的防御策略。
核心思路:论文的核心思路是构建一个模块化的测试框架,该框架能够系统地评估各种增强和集成的LIME/SHAP方法在抵抗偏差隐藏方面的能力。通过在不同性能的分类器和分布外数据上进行测试,可以识别出更鲁棒的解释方法。
技术框架:该框架包含以下主要模块:1) 数据集和模型:使用包含偏差的数据集(如COMPAS)训练不同性能的分类器。2) 对抗攻击:实施对抗攻击,旨在操纵LIME和SHAP的解释结果,使其无法检测到模型中的偏差。3) 解释方法:评估原始的LIME和SHAP方法,以及各种增强和集成的版本。4) 评估指标:使用指标来衡量解释方法检测偏差的能力,以及抵抗对抗攻击的鲁棒性。
关键创新:论文的关键创新在于提出了一个模块化的测试框架,能够系统地评估和比较不同的LIME/SHAP防御策略。该框架允许研究人员灵活地组合不同的组件(如数据集、模型、攻击方法和解释方法),从而全面地了解各种防御策略的优缺点。
关键设计:论文的关键设计包括:1) 模块化的框架结构,方便添加新的数据集、模型、攻击方法和解释方法。2) 使用多种评估指标,全面衡量解释方法的性能。3) 评估了多种LIME/SHAP集成配置,探索了不同的集成策略对鲁棒性的影响。4) 在分布外数据上进行测试,评估了解释方法在实际应用中的泛化能力。
🖼️ 关键图片
📊 实验亮点
实验结果表明,特定的LIME/SHAP集成配置能够显著提高偏差检测能力,即使在对抗攻击下也能有效揭示模型中的偏差。通过模块化测试框架,论文系统地比较了不同解释方法的鲁棒性,为选择合适的解释方法提供了指导。具体性能数据和提升幅度在论文正文中。
🎯 应用场景
该研究成果可应用于高风险机器学习系统的透明度提升,例如在信用评分、医疗诊断和刑事司法等领域。通过使用更鲁棒的解释方法,可以更好地理解模型的决策过程,发现并纠正潜在的偏差,从而提高模型的公平性和可靠性,避免歧视性结果。
📄 摘要(原文)
Post hoc explanation methods, such as LIME and SHAP, provide interpretable insights into black-box classifiers and are increasingly used to assess model biases and generalizability. However, these methods are vulnerable to adversarial manipulation, potentially concealing harmful biases. Building on the work of Slack et al. (2020), we investigate the susceptibility of LIME and SHAP to biased models and evaluate strategies for improving robustness. We first replicate the original COMPAS experiment to validate prior findings and establish a baseline. We then introduce a modular testing framework enabling systematic evaluation of augmented and ensemble explanation approaches across classifiers of varying performance. Using this framework, we assess multiple LIME/SHAP ensemble configurations on out-of-distribution models, comparing their resistance to bias concealment against the original methods. Our results identify configurations that substantially improve bias detection, highlighting their potential for enhancing transparency in the deployment of high-stakes machine learning systems.