Retro-Expert: Collaborative Reasoning for Interpretable Retrosynthesis
作者: Xinyi Li, Sai Wang, Yutian Lin, Yu Wu, Yi Yang
分类: cs.LG, cs.AI
发布日期: 2025-08-14 (更新: 2025-12-05)
💡 一句话要点
提出Retro-Expert,通过协同推理实现可解释的逆合成预测
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 逆合成预测 可解释性 大型语言模型 强化学习 协同推理 化学合成 专家系统
📋 核心要点
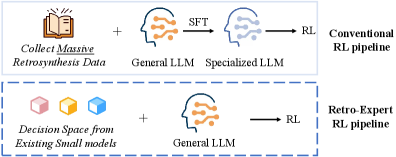
- 现有逆合成模型依赖静态模式匹配,缺乏有效逻辑决策能力,导致决策过程不透明。
- Retro-Expert结合大型语言模型和专业模型的优势,通过协同推理实现可解释的逆合成预测。
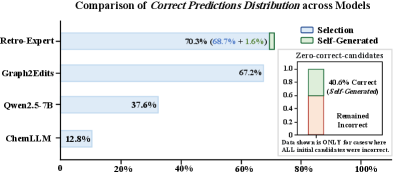
- 实验结果表明,Retro-Expert在性能上超越现有模型,并提供专家级别的可解释性。
📝 摘要(中文)
逆合成预测旨在根据给定的产物分子推断反应物分子,是化学合成中的一项基本任务。然而,现有模型依赖于静态的模式匹配范式,限制了其进行有效逻辑决策的能力,导致黑盒决策。为此,我们提出了Retro-Expert,一个可解释的逆合成框架,通过强化学习结合大型语言模型和专业模型的互补推理优势,进行协同推理。它通过三个组成部分输出基于化学逻辑的自然语言解释:(1)专业模型分析产物以构建高质量的化学决策空间;(2)LLM驱动的关键推理生成预测和相应的可解释推理路径;(3)强化学习优化可解释的决策策略。实验表明,Retro-Expert不仅在不同指标上超越了基于LLM和专业模型的方法,而且提供了与专家对齐的解释,弥合了AI预测和可操作的化学见解之间的差距。
🔬 方法详解
问题定义:逆合成预测旨在根据给定的目标产物,预测合适的反应物。现有方法,特别是基于静态模式匹配的方法,缺乏足够的逻辑推理能力,难以处理复杂的化学反应,并且决策过程如同黑盒,缺乏可解释性,阻碍了化学家对AI预测结果的信任和应用。
核心思路:Retro-Expert的核心思路是结合专业模型和大型语言模型的优势,通过协同推理来提升逆合成预测的准确性和可解释性。专业模型负责构建高质量的化学决策空间,而大型语言模型负责进行逻辑推理和生成自然语言解释。通过强化学习,优化模型的决策策略,使其更符合化学专家的思维模式。
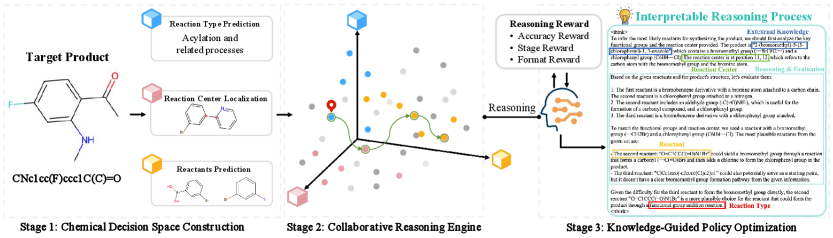
技术框架:Retro-Expert包含三个主要组成部分:(1)专业模型:分析产物分子,识别潜在的反应位点和反应类型,构建化学决策空间。(2)LLM驱动的关键推理:利用大型语言模型,基于专业模型提供的决策空间,生成逆合成预测结果,并输出相应的自然语言解释,描述推理过程。(3)强化学习优化:使用强化学习算法,根据化学专家的反馈和奖励信号,优化模型的决策策略,提高预测的准确性和解释的合理性。
关键创新:Retro-Expert的关键创新在于其协同推理框架,它将专业模型的化学知识和大型语言模型的推理能力相结合,实现了可解释的逆合成预测。与现有方法相比,Retro-Expert不仅提高了预测的准确性,还提供了专家级别的解释,增强了AI预测结果的可信度。
关键设计:在专业模型方面,采用了基于图神经网络的模型结构,用于分析分子结构和预测反应位点。在LLM驱动的关键推理方面,使用了预训练的语言模型,并针对逆合成任务进行了微调。在强化学习优化方面,设计了合适的奖励函数,鼓励模型生成准确且可解释的预测结果。具体的参数设置、损失函数和网络结构等细节在论文中有详细描述。
🖼️ 关键图片
📊 实验亮点
实验结果表明,Retro-Expert在逆合成预测任务上取得了显著的性能提升,超越了基于LLM和专业模型的方法。具体而言,在Top-1准确率、反应类型准确率等指标上均取得了领先水平,并且生成的解释与化学专家的思维模式更加一致。此外,消融实验验证了各个模块的有效性,证明了协同推理框架的优越性。
🎯 应用场景
Retro-Expert可应用于药物发现、材料科学等领域,加速新化合物的合成路线设计。通过提供可解释的逆合成预测,该研究有助于化学家理解AI的决策过程,提高对AI预测结果的信任度,并促进人机协作,从而提高化学合成的效率和成功率。未来,该研究可扩展到更复杂的化学反应和合成路线设计。
📄 摘要(原文)
Retrosynthesis prediction aims to infer the reactant molecule based on a given product molecule, which is a fundamental task in chemical synthesis. However, existing models rely on static pattern-matching paradigm, which limits their ability to perform effective logic decision-making, leading to black-box decision-making. Building on this, we propose Retro-Expert, an interpretable retrosynthesis framework that performs collaborative reasoning by combining the complementary reasoning strengths of Large Language Models and specialized models via reinforcement learning. It outputs natural language explanations grounded in chemical logic through three components: (1) specialized models analyze the product to construct high-quality chemical decision space, (2) LLM-driven critical reasoning to generate predictions and corresponding interpretable reasoning path, and (3) reinforcement learning optimizing interpretable decision policy. Experiments show that Retro-Expert not only surpasses both LLM-based and specialized models across different metrics but also provides expert-aligned explanations that bridge the gap between AI predictions and actionable chemical insights.