REFN: A Reinforcement-Learning-From-Network Framework against 1-day/n-day Exploitations
作者: Tianlong Yu, Lihong Liu, Ziyi Zhou, Fudu Xing, Kailong Wang, Yang Yang
分类: cs.LG, cs.AI
发布日期: 2025-08-14
💡 一句话要点
提出REFN框架,利用强化学习训练LLM自主生成网络过滤器,防御1-day/n-day漏洞攻击。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 强化学习 大型语言模型 网络安全 漏洞防御 1-day漏洞 n-day漏洞 网络过滤器 知识蒸馏
📋 核心要点
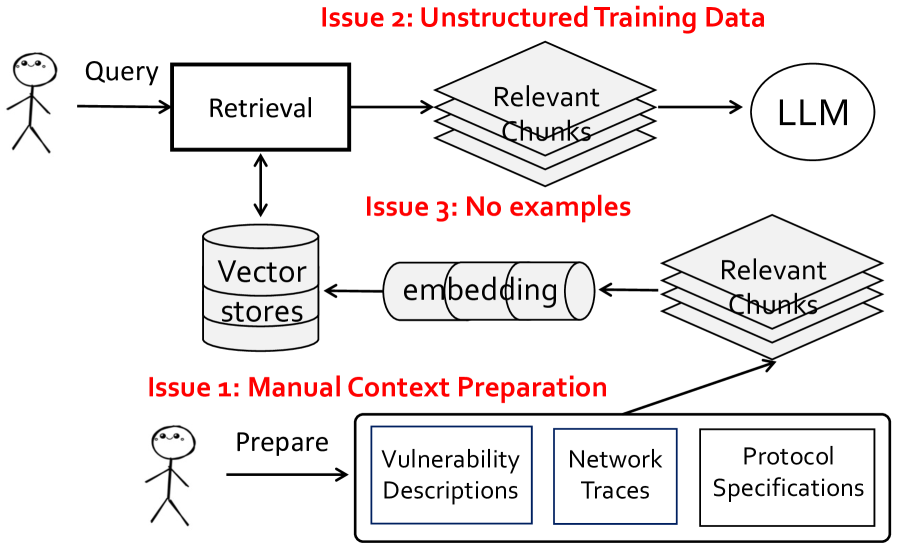
- 现有防御1-day/n-day漏洞的方法,如打补丁和网络过滤,存在可扩展性差、兼容性问题和部署易出错等问题。
- REFN框架利用强化学习训练LLM,使其能够自主生成网络过滤器,从而防御1-day/n-day漏洞攻击。
- 实验结果表明,REFN在准确性、效率和可扩展性方面均优于现有方法,平均补丁修复时间仅为3.65小时。
📝 摘要(中文)
本文提出REFN(Reinforcement Learning From Network)框架,旨在解决大规模部署和延迟补丁(平均补丁修复时间超过60天)导致的网络设备面临的1-day/n-day漏洞利用威胁。现有防御方法(如基于主机的补丁和基于网络的过滤)因可扩展性有限、兼容性问题(特别是嵌入式或遗留系统)以及易出错的部署过程(手动补丁验证)而不足。REFN通过训练大型语言模型(LLM)自主生成网络过滤器来防止此类攻击,通过在线网络奖励驱动强化学习(RL)而非传统的人工反馈(RLHF)来确保可扩展性,通过在边缘安全网关(Amazon Eero)上统一部署来保证兼容性,并通过使用真实网络流量进行在线验证来提供鲁棒性。REFN解决了训练LLM进行漏洞预防的三个核心挑战:1) 通过基于Agentic RAG的知识蒸馏扩展LLM有限的漏洞修复专业知识;2) 通过RL From VNF Pipeline弥合LLM语言到网络的差距,将语言上下文(漏洞描述)转换为网络执行;3) 通过在线Agentic验证来惩罚错误输出,从而解决LLM的幻觉和不确定性。在22个1-day/n-day漏洞家族的评估中,REFN展示了有效性(比替代方案高21.1%的准确率)、效率(平均补丁修复时间为3.65小时)和可扩展性(轻松扩展到10K台设备)。
🔬 方法详解
问题定义:论文旨在解决1-day/n-day漏洞利用对网络设备造成的严重威胁。现有防御方法,如主机补丁和网络过滤,在可扩展性、兼容性和部署方面存在局限性。手动补丁验证过程容易出错,且平均补丁修复时间过长,导致设备在漏洞暴露期间极易受到攻击。
核心思路:论文的核心思路是利用大型语言模型(LLM)的强大能力,通过强化学习(RL)训练LLM自主生成网络过滤器,从而快速有效地防御1-day/n-day漏洞利用。这种方法避免了传统防御方法的局限性,并能更快速地响应新出现的威胁。
技术框架:REFN框架包含以下主要模块:1) Agentic RAG based Knowledge Distillation:扩展LLM的漏洞修复知识;2) RL From VNF Pipeline:将LLM的语言上下文(漏洞描述)转换为网络执行;3) Online Agentic Validation:在线验证LLM生成的过滤器,并惩罚错误输出。整个流程通过强化学习进行驱动,利用在线网络奖励来优化LLM的性能。
关键创新:REFN的关键创新在于利用强化学习从网络环境中学习,而非依赖传统的人工反馈。这种方法能够更有效地训练LLM,使其能够自主生成网络过滤器,并快速适应新的威胁。此外,REFN还解决了LLM在漏洞预防方面的三个核心挑战:知识不足、语言到网络的差距以及幻觉和不确定性。
关键设计:REFN使用Agentic RAG进行知识蒸馏,提升LLM的漏洞修复能力。RL From VNF Pipeline将漏洞描述转化为具体的网络策略,例如防火墙规则。在线Agentic验证模块通过真实网络流量评估过滤器的有效性,并使用强化学习算法调整LLM的策略。具体的参数设置、损失函数和网络结构等细节在论文中进行了详细描述(未知)。
🖼️ 关键图片


📊 实验亮点
REFN在22个1-day/n-day漏洞家族的评估中表现出色,准确率比现有替代方案高21.1%,平均补丁修复时间仅为3.65小时,并且可以轻松扩展到10K台设备。这些结果表明,REFN在有效性、效率和可扩展性方面均优于现有方法,具有很强的实际应用价值。
🎯 应用场景
REFN框架可应用于各种网络安全场景,例如企业网络安全、物联网设备安全和云安全。它可以帮助企业和个人快速有效地防御1-day/n-day漏洞攻击,降低安全风险,并提高网络安全防护能力。该研究为利用LLM和强化学习进行自动化网络安全防御开辟了新的方向。
📄 摘要(原文)
The exploitation of 1 day or n day vulnerabilities poses severe threats to networked devices due to massive deployment scales and delayed patching (average Mean Time To Patch exceeds 60 days). Existing defenses, including host based patching and network based filtering, are inadequate due to limited scalability across diverse devices, compatibility issues especially with embedded or legacy systems, and error prone deployment process (manual patch validation). To address these issues, we introduce REFN (Reinforcement Learning From Network), a novel framework that trains Large Language Models (LLMs) to autonomously generate network filters to prevent 1 day or n day exploitations. REFN ensures scalability by uniquely employs Reinforcement Learning (RL) driven by online network rewards instead of traditional Human Feedback (RLHF). REFN guarantees compatibility via unified deployment on edge security gateways (Amazon Eero). REFN provides robustness via online validation using real network traffic. Crucially, REFN addresses three core challenges in training LLMs for exploit prevention: 1) expanding current LLMs limited vulnerability fixing expertise via Agentic RAG based Knowledge Distillation, 2) bridging current LLMs language to network gaps through an RL From VNF Pipeline that translates language context (vulnerability description) into network enforcement, 3) addressing the LLM hallucination and non determinism via the Online Agentic Validation that penalizes erroneous outputs. Evaluated across 22 families of 1 day or n day exploits, REFN demonstrates effectiveness (21.1 percent higher accuracy than alternatives), efficiency (Mean Time To Patch of 3.65 hours) and scalability (easily scale to 10K devices). REFN serves as an initial step toward training LLMs to rapidly prevent massive scale 1 day or n day exploitations.