A Unified Multi-Agent Framework for Universal Multimodal Understanding and Generation
作者: Jiulin Li, Ping Huang, Yexin Li, Shuo Chen, Juewen Hu, Ye Tian
分类: cs.LG, cs.AI, cs.MA
发布日期: 2025-08-14
备注: 8 pages, 5 figures
💡 一句话要点
提出MAGUS,一个统一的多智能体框架,用于通用多模态理解与生成。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态理解 多模态生成 多智能体系统 语言模型 扩散模型 跨模态学习 增长感知搜索
📋 核心要点
- 现有方法在多模态理解和生成任务中,缺乏灵活性和可扩展性,难以有效整合LLM的推理能力和扩散模型的高保真生成能力。
- MAGUS框架通过解耦认知和审议阶段,利用多智能体协作和增长感知搜索机制,实现了统一的多模态理解和生成。
- 实验结果表明,MAGUS在多个基准测试中超越了现有方法,并在MME基准测试中超过了GPT-4o,展示了其优越的性能。
📝 摘要(中文)
现实世界的多模态应用通常需要任意模态间的转换能力,包括文本、图像、音频和视频的理解与生成。然而,如何整合自回归语言模型(LLM)的推理能力和扩散模型的高保真生成能力仍然是一个挑战。现有方法依赖于僵化的流程或紧耦合的架构,限制了灵活性和可扩展性。我们提出了MAGUS(多智能体引导的统一多模态系统),一个模块化框架,通过两个解耦的阶段:认知和审议,统一了多模态理解和生成。MAGUS实现了共享文本工作空间内的符号多智能体协作。在认知阶段,三个角色条件化的多模态LLM智能体——感知者、规划者和反思者——进行协作对话,以执行结构化的理解和规划。审议阶段引入了一种增长感知搜索机制,该机制以相互增强的方式协调基于LLM的推理和基于扩散的生成。MAGUS支持即插即用的可扩展性、可扩展的任意模态转换和语义对齐——所有这些都无需联合训练。在包括图像、视频和音频生成以及跨模态指令跟随在内的多个基准测试中进行的实验表明,MAGUS优于强大的基线和最先进的系统。值得注意的是,在MME基准测试中,MAGUS超越了强大的闭源模型GPT-4o。
🔬 方法详解
问题定义:论文旨在解决多模态领域中,任意模态之间相互转换和理解的难题。现有方法通常采用pipeline或者紧耦合的架构,导致灵活性差,难以扩展到更多模态,并且难以有效结合LLM的推理能力和扩散模型的高保真生成能力。
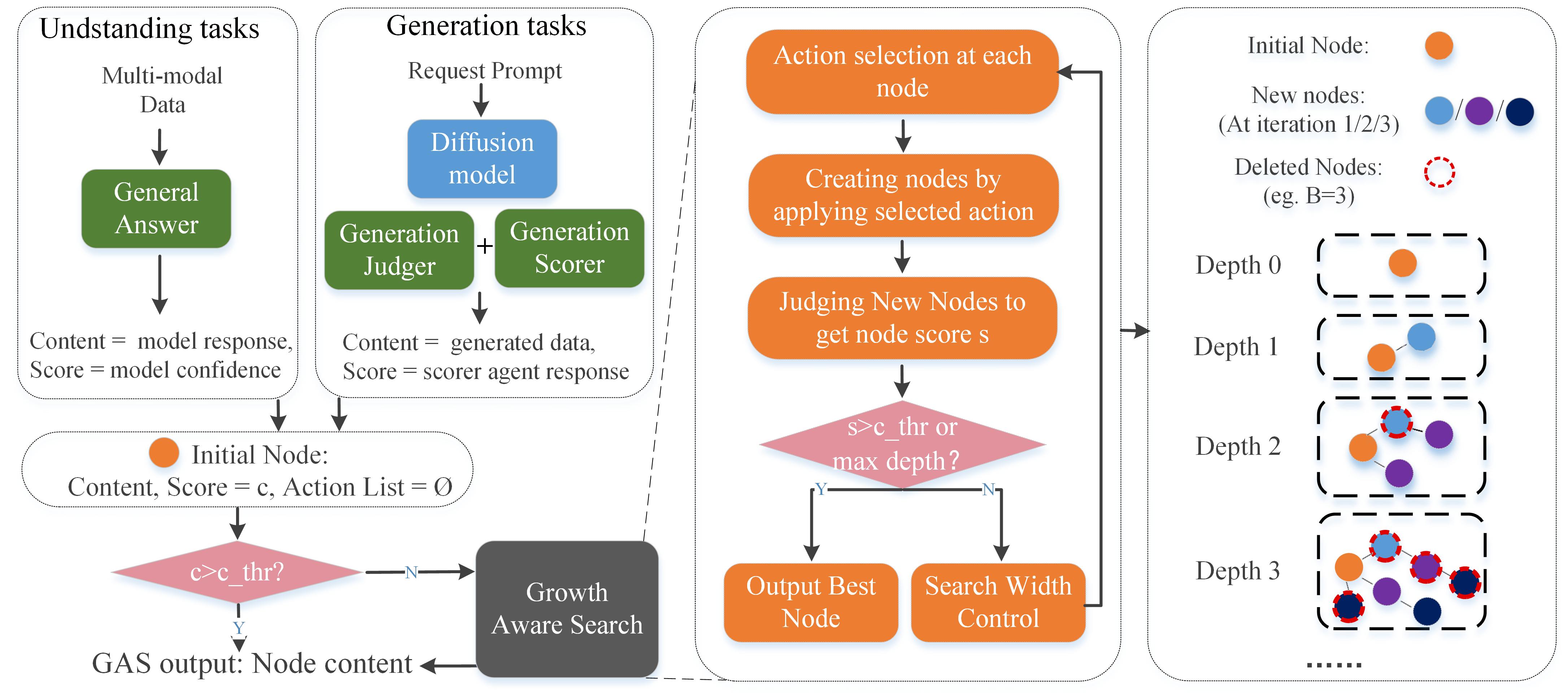
核心思路:论文的核心思路是将多模态任务分解为两个解耦的阶段:认知和审议。认知阶段利用多智能体协作进行结构化理解和规划,审议阶段则通过增长感知搜索机制协调LLM推理和扩散模型生成,从而实现灵活且可扩展的多模态理解和生成。这种解耦的设计允许各个模块独立发展,提高了系统的整体性能。
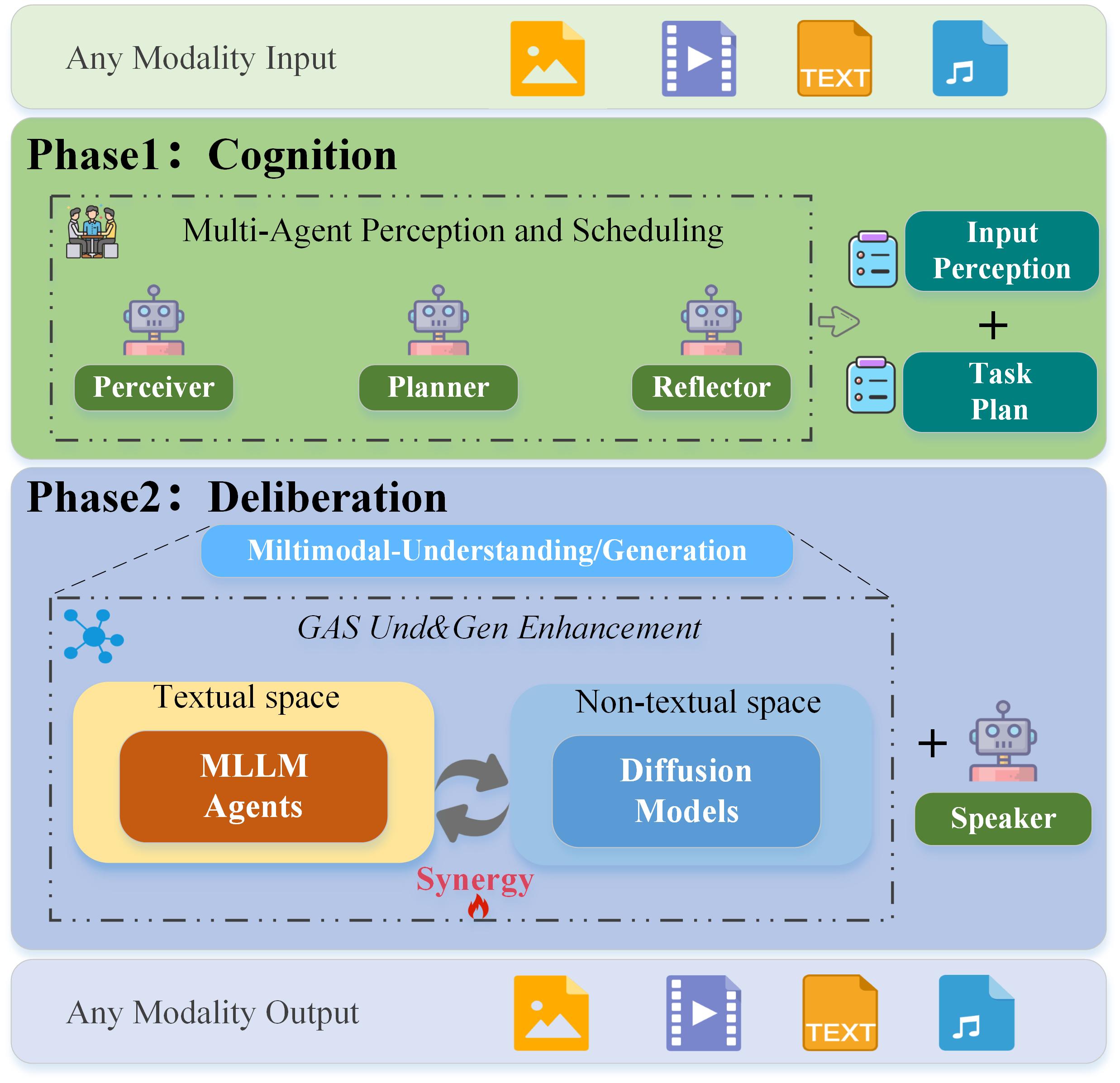
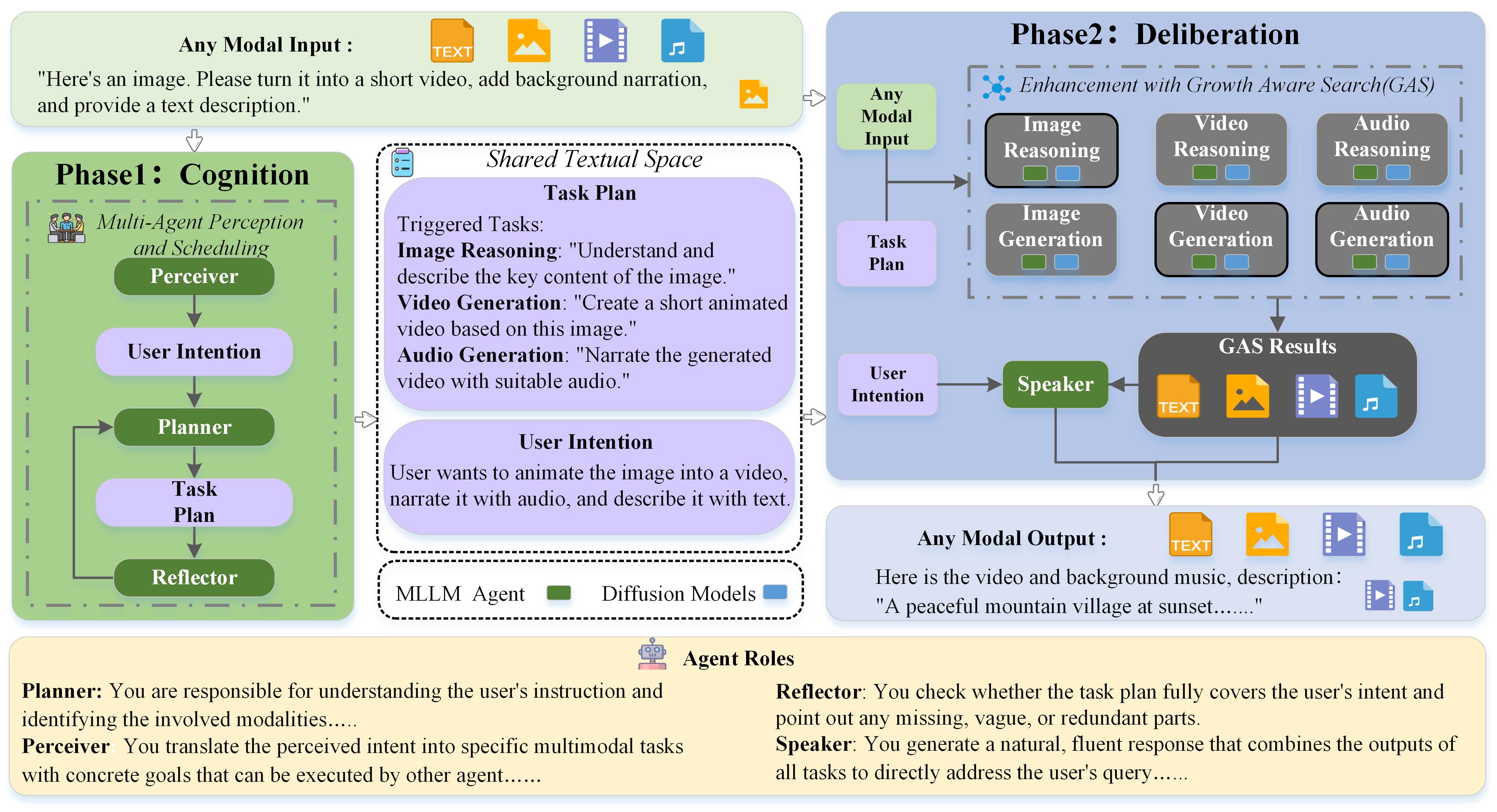
技术框架:MAGUS框架包含两个主要阶段:认知阶段和审议阶段。认知阶段由三个角色条件化的多模态LLM智能体组成:感知者(Perceiver)、规划者(Planner)和反思者(Reflector)。这些智能体通过共享的文本工作空间进行协作对话,完成对输入模态的理解和任务规划。审议阶段则引入增长感知搜索机制,该机制协调LLM的推理能力和扩散模型的生成能力,以迭代的方式优化生成结果。
关键创新:MAGUS的关键创新在于其模块化的多智能体架构和增长感知搜索机制。多智能体架构实现了任务的分解和协作,提高了系统的灵活性和可扩展性。增长感知搜索机制则通过LLM推理和扩散模型生成的相互增强,提高了生成结果的质量。与现有方法相比,MAGUS无需联合训练,支持即插即用的可扩展性,并能实现更好的语义对齐。
关键设计:认知阶段的三个智能体分别负责不同的任务:感知者负责提取输入模态的特征,规划者负责制定任务执行计划,反思者负责评估和改进计划。增长感知搜索机制通过迭代的方式,利用LLM生成候选结果,并使用扩散模型对候选结果进行优化。具体的参数设置、损失函数和网络结构等技术细节在论文中未详细描述,属于未知信息。
🖼️ 关键图片
📊 实验亮点
MAGUS在多个基准测试中取得了显著的性能提升,包括图像、视频和音频生成,以及跨模态指令跟随任务。尤其值得注意的是,在MME基准测试中,MAGUS超越了强大的闭源模型GPT-4o,证明了其在多模态理解和生成方面的卓越能力。具体的性能数据和提升幅度在论文中进行了详细的展示。
🎯 应用场景
MAGUS框架具有广泛的应用前景,可应用于跨模态内容生成、智能助手、多模态对话系统、以及各种需要多模态理解和生成的实际场景。例如,可以根据用户提供的图像和文本描述生成相应的视频或音频,或者根据用户的语音指令完成复杂的跨模态任务。该研究的成果有助于推动多模态人工智能技术的发展,并为未来的智能应用提供更强大的支持。
📄 摘要(原文)
Real-world multimodal applications often require any-to-any capabilities, enabling both understanding and generation across modalities including text, image, audio, and video. However, integrating the strengths of autoregressive language models (LLMs) for reasoning and diffusion models for high-fidelity generation remains challenging. Existing approaches rely on rigid pipelines or tightly coupled architectures, limiting flexibility and scalability. We propose MAGUS (Multi-Agent Guided Unified Multimodal System), a modular framework that unifies multimodal understanding and generation via two decoupled phases: Cognition and Deliberation. MAGUS enables symbolic multi-agent collaboration within a shared textual workspace. In the Cognition phase, three role-conditioned multimodal LLM agents - Perceiver, Planner, and Reflector - engage in collaborative dialogue to perform structured understanding and planning. The Deliberation phase incorporates a Growth-Aware Search mechanism that orchestrates LLM-based reasoning and diffusion-based generation in a mutually reinforcing manner. MAGUS supports plug-and-play extensibility, scalable any-to-any modality conversion, and semantic alignment - all without the need for joint training. Experiments across multiple benchmarks, including image, video, and audio generation, as well as cross-modal instruction following, demonstrate that MAGUS outperforms strong baselines and state-of-the-art systems. Notably, on the MME benchmark, MAGUS surpasses the powerful closed-source model GPT-4o.