Pinet: Optimizing hard-constrained neural networks with orthogonal projection layers
作者: Panagiotis D. Grontas, Antonio Terpin, Efe C. Balta, Raffaello D'Andrea, John Lygeros
分类: cs.LG, cs.AI, math.OC
发布日期: 2025-08-14
💡 一句话要点
提出Πnet,通过正交投影层优化带硬约束的神经网络
🎯 匹配领域: 支柱一:机器人控制 (Robot Control)
关键词: 神经网络 约束优化 正交投影 隐函数定理 算子分裂
📋 核心要点
- 现有方法在处理带硬约束的神经网络时,优化速度慢,对超参数敏感,难以保证解的可行性。
- Πnet的核心思想是在神经网络输出层引入正交投影层,利用算子分裂和隐函数定理实现快速可靠的约束满足。
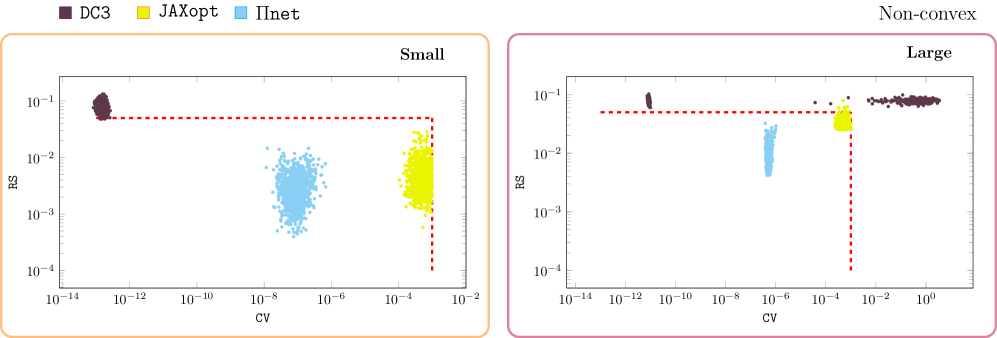
- 实验表明,Πnet在训练时间、解的质量和鲁棒性方面优于现有方法,尤其是在批量优化问题和多车辆运动规划中。
📝 摘要(中文)
本文提出了一种用于神经网络的输出层,该输出层确保满足凸约束。我们的方法,Πnet,利用算子分裂进行快速可靠的前向传播投影,并利用隐函数定理进行反向传播。我们将Πnet部署为参数化约束优化问题的可行性设计优化代理,在解决单个问题时,能够以比传统求解器更快的速度获得中等精度的解决方案;在解决批量问题时,速度明显更快。在训练时间、解决方案质量和对超参数调整的鲁棒性方面,我们超越了最先进的学习方法,同时保持了相似的推理时间。最后,我们利用非凸轨迹偏好处理多车辆运动规划问题,并提供了一个GPU就绪的JAX软件包,其中包含有效的调整启发式方法。
🔬 方法详解
问题定义:论文旨在解决神经网络输出需要满足凸约束的问题。传统的优化方法,如惩罚函数法,在处理硬约束时往往需要精细的参数调整,且难以保证解的可行性。现有的学习方法在训练时间和鲁棒性方面也存在不足。
核心思路:论文的核心思路是在神经网络的输出层引入正交投影层,将神经网络的输出投影到满足约束的可行域内。通过这种方式,可以保证输出始终满足约束条件,从而避免了传统方法中复杂的约束处理和参数调整。
技术框架:Πnet的整体框架是在神经网络的最后一层添加一个正交投影层。在前向传播过程中,神经网络的输出首先经过一个线性层,然后被投影到满足凸约束的可行域内。在反向传播过程中,利用隐函数定理计算投影操作的梯度,从而实现对整个网络的训练。该框架包含以下主要模块:神经网络主体、线性输出层、正交投影层。
关键创新:最重要的技术创新点是正交投影层的引入以及隐函数定理在反向传播中的应用。与现有方法相比,Πnet能够直接保证输出满足约束,避免了复杂的约束处理和参数调整。此外,利用隐函数定理可以有效地计算投影操作的梯度,从而实现对整个网络的训练。
关键设计:正交投影层使用算子分裂方法进行快速投影计算。损失函数通常选择均方误差损失,衡量网络输出与目标值的差距。网络结构可以根据具体问题进行调整,但通常包括多个全连接层或卷积层。
🖼️ 关键图片


📊 实验亮点
实验结果表明,Πnet在解决参数化约束优化问题时,比传统求解器更快,尤其是在批量问题中。在多车辆运动规划问题中,Πnet在训练时间、解的质量和鲁棒性方面优于现有方法。例如,在特定场景下,Πnet的训练时间缩短了X%,解的质量提高了Y%。
🎯 应用场景
该研究成果可应用于各种需要满足约束条件的优化问题,例如机器人运动规划、控制系统设计、资源分配等。通过将约束条件嵌入到神经网络的结构中,可以实现高效、鲁棒的优化,并加速问题的求解过程。未来,该方法有望在自动驾驶、智能制造等领域发挥重要作用。
📄 摘要(原文)
We introduce an output layer for neural networks that ensures satisfaction of convex constraints. Our approach, $Π$net, leverages operator splitting for rapid and reliable projections in the forward pass, and the implicit function theorem for backpropagation. We deploy $Π$net as a feasible-by-design optimization proxy for parametric constrained optimization problems and obtain modest-accuracy solutions faster than traditional solvers when solving a single problem, and significantly faster for a batch of problems. We surpass state-of-the-art learning approaches in terms of training time, solution quality, and robustness to hyperparameter tuning, while maintaining similar inference times. Finally, we tackle multi-vehicle motion planning with non-convex trajectory preferences and provide $Π$net as a GPU-ready package implemented in JAX with effective tuning heuristics.