eMamba: Efficient Acceleration Framework for Mamba Models in Edge Computing
作者: Jiyong Kim, Jaeho Lee, Jiahao Lin, Alish Kanani, Miao Sun, Umit Y. Ogras, Jaehyun Park
分类: cs.LG, cs.AI
发布日期: 2025-08-14
备注: Paper accepted at ESWEEK 2025 (CODES+ISSS) conference
💡 一句话要点
eMamba:面向边缘计算的Mamba模型高效加速框架
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: Mamba模型 边缘计算 硬件加速 神经架构搜索 模型优化 低功耗 FPGA ASIC
📋 核心要点
- 现有Mamba模型在边缘设备部署面临硬件加速框架缺失的挑战,限制了其在资源受限环境中的应用。
- eMamba通过硬件感知的近似和神经架构搜索,优化Mamba模型,提升计算效率并降低资源占用。
- 实验表明,eMamba在多个数据集上实现了与SOTA相当的精度,同时显著降低了参数量、延迟和功耗。
📝 摘要(中文)
基于状态空间模型(SSM)的机器学习架构最近在处理序列数据方面受到了广泛关注。Mamba作为一种新兴的序列到序列SSM,与最先进的Transformer模型相比,在具有竞争力的准确率的同时,提供了卓越的计算效率。尽管这一优势使得Mamba在资源受限的边缘设备上部署极具前景,但目前还没有专门为在此类环境中部署Mamba而优化的硬件加速框架。本文提出了eMamba,这是一个全面的端到端硬件加速框架,专门为在边缘平台部署Mamba模型而设计。eMamba通过用轻量级的硬件感知替代方案替换复杂的归一化层,并考虑目标应用来近似昂贵的操作(如SiLU激活和指数运算),从而最大限度地提高计算效率。然后,它执行一个近似感知的神经架构搜索(NAS)来调整近似过程中使用的可学习参数。在Fashion-MNIST、CIFAR-10和MARS(一个开源的人体姿态估计数据集)上的评估表明,eMamba使用比最先进技术少1.63-19.9倍的参数,实现了相当的准确率。此外,它很好地推广到大规模自然语言任务,在WikiText2数据集上展示了跨不同序列长度的稳定困惑度。我们还在AMD ZCU102 FPGA和使用GlobalFoundries (GF) 22 nm技术的ASIC上量化和实现了整个eMamba流水线。实验结果表明,与基线解决方案相比,延迟降低了4.95-5.62倍,吞吐量提高了2.22-9.95倍,同时面积缩小了4.77倍,功耗降低了9.84倍,能耗降低了48.6倍,并保持了具有竞争力的准确率。
🔬 方法详解
问题定义:现有Mamba模型虽然在计算效率上优于Transformer,但缺乏针对边缘计算平台的硬件加速框架。直接部署Mamba模型在资源受限的边缘设备上会面临高延迟、低吞吐量和高功耗等问题,无法充分发挥其优势。现有方法没有充分考虑边缘设备的硬件特性,导致性能瓶颈。
核心思路:eMamba的核心思路是针对边缘设备的硬件特性,对Mamba模型进行近似和优化,从而在保证精度的前提下,显著降低计算复杂度和资源占用。通过硬件感知的近似方法,减少计算量大的操作,并利用神经架构搜索(NAS)自动调整近似过程中的参数,以达到最佳的性能和精度平衡。
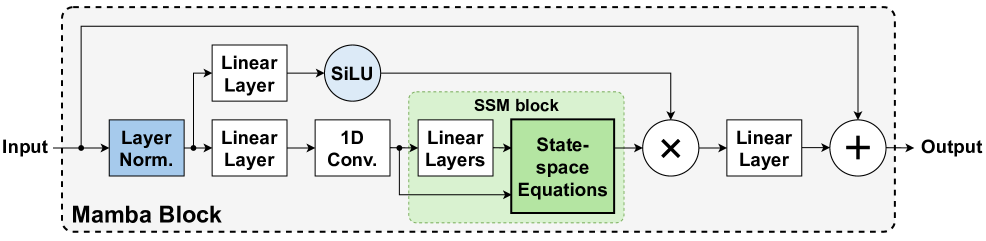
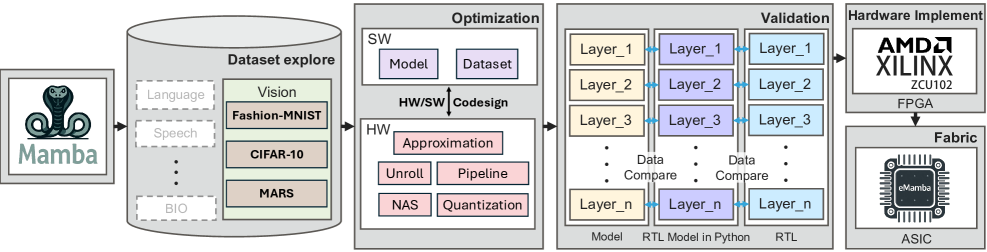
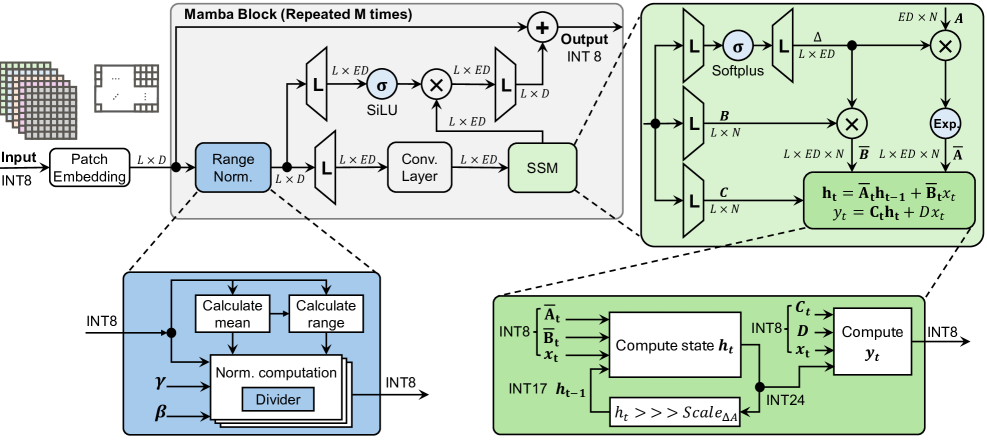
技术框架:eMamba框架包含以下主要阶段:1) 硬件感知近似:用轻量级的替代方案替换复杂的归一化层,并近似SiLU激活和指数运算等昂贵操作。2) 近似感知的神经架构搜索(NAS):自动搜索和优化近似过程中使用的可学习参数,以最大化性能和精度。3) 量化和部署:将优化后的模型量化并在边缘设备(如FPGA和ASIC)上部署。
关键创新:eMamba的关键创新在于其硬件感知的近似方法和近似感知的神经架构搜索。传统的模型优化方法通常忽略目标硬件的特性,而eMamba则充分考虑了边缘设备的资源限制和计算能力,从而实现了更高效的加速。近似感知的NAS能够自动调整近似过程中的参数,避免了手动调参的繁琐和低效。
关键设计:在硬件感知近似方面,论文采用了轻量级的归一化层替代方案,并使用查找表(LUT)或多项式近似等方法来近似SiLU激活和指数运算。在近似感知的NAS方面,论文设计了一个搜索空间,包含不同的近似策略和参数,并使用强化学习或进化算法等方法来搜索最优的配置。损失函数综合考虑了模型的精度和硬件指标(如延迟、功耗和面积)。
🖼️ 关键图片
📊 实验亮点
实验结果表明,eMamba在Fashion-MNIST、CIFAR-10和MARS数据集上实现了与最先进技术相当的精度,同时参数量减少了1.63-19.9倍。在WikiText2数据集上,eMamba表现出稳定的困惑度。在AMD ZCU102 FPGA和ASIC上的实现结果表明,与基线解决方案相比,延迟降低了4.95-5.62倍,吞吐量提高了2.22-9.95倍,面积缩小了4.77倍,功耗降低了9.84倍,能耗降低了48.6倍。
🎯 应用场景
eMamba在边缘计算领域具有广泛的应用前景,例如智能监控、自动驾驶、机器人和物联网设备等。通过在边缘设备上高效部署Mamba模型,可以实现低延迟、高吞吐量和低功耗的智能应用,从而提高系统的实时性和可靠性。该研究成果有助于推动人工智能在边缘端的普及和应用。
📄 摘要(原文)
State Space Model (SSM)-based machine learning architectures have recently gained significant attention for processing sequential data. Mamba, a recent sequence-to-sequence SSM, offers competitive accuracy with superior computational efficiency compared to state-of-the-art transformer models. While this advantage makes Mamba particularly promising for resource-constrained edge devices, no hardware acceleration frameworks are currently optimized for deploying it in such environments. This paper presents eMamba, a comprehensive end-to-end hardware acceleration framework explicitly designed for deploying Mamba models on edge platforms. eMamba maximizes computational efficiency by replacing complex normalization layers with lightweight hardware-aware alternatives and approximating expensive operations, such as SiLU activation and exponentiation, considering the target applications. Then, it performs an approximation-aware neural architecture search (NAS) to tune the learnable parameters used during approximation. Evaluations with Fashion-MNIST, CIFAR-10, and MARS, an open-source human pose estimation dataset, show eMamba achieves comparable accuracy to state-of-the-art techniques using 1.63-19.9$\times$ fewer parameters. In addition, it generalizes well to large-scale natural language tasks, demonstrating stable perplexity across varying sequence lengths on the WikiText2 dataset. We also quantize and implement the entire eMamba pipeline on an AMD ZCU102 FPGA and ASIC using GlobalFoundries (GF) 22 nm technology. Experimental results show 4.95-5.62$\times$ lower latency and 2.22-9.95$\times$ higher throughput, with 4.77$\times$ smaller area, 9.84$\times$ lower power, and 48.6$\times$ lower energy consumption than baseline solutions while maintaining competitive accuracy.