Iterative Learning of Computable Phenotypes for Treatment Resistant Hypertension using Large Language Models
作者: Guilherme Seidyo Imai Aldeia, Daniel S. Herman, William G. La Cava
分类: cs.LG, cs.AI, cs.CL
发布日期: 2025-08-07
备注: To appear in PMLR, Volume 298, Machine Learning for Healthcare, 2025
💡 一句话要点
利用大语言模型迭代学习可计算表型,解决难治性高血压问题
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 可计算表型 难治性高血压 迭代学习 临床决策支持
📋 核心要点
- 现有方法难以利用大型语言模型生成可解释且准确的可计算表型,尤其是在医学领域。
- 提出一种“综合、执行、调试、指导”的迭代学习策略,利用数据驱动反馈改进LLM生成的可计算表型。
- 实验结果表明,该方法在少量训练数据下,性能接近甚至超过现有机器学习方法,且具有良好的可解释性。
📝 摘要(中文)
大型语言模型(LLM)在医学问答和编程方面表现出卓越的能力,但其生成可解释的可计算表型(CP)的潜力尚未得到充分探索。本文研究了LLM是否能为六种不同复杂程度的临床表型生成准确而简洁的CP,这些CP可用于实现可扩展的临床决策支持,从而改善难治性高血压患者的护理。除了评估零样本性能外,我们还提出并测试了一种“综合、执行、调试、指导”策略,该策略利用LLM生成CP,并使用数据驱动的反馈进行迭代改进。结果表明,LLM与迭代学习相结合,可以生成可解释且相当准确的程序,在需要显著更少的训练样本的情况下,性能接近最先进的机器学习方法。
🔬 方法详解
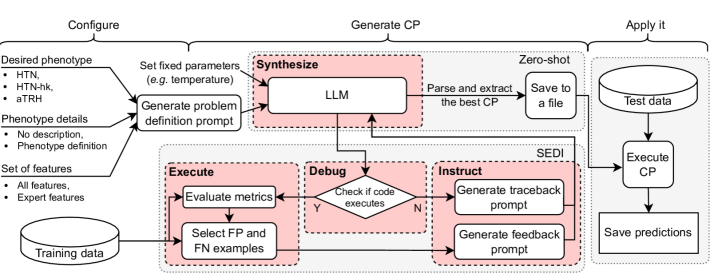
问题定义:论文旨在解决难治性高血压的临床决策支持问题,具体而言,是利用大型语言模型自动生成可计算的表型(CP)。现有方法要么依赖专家知识手动构建CP,要么使用黑盒机器学习模型,缺乏可解释性,且需要大量训练数据。
核心思路:论文的核心思路是利用大型语言模型的代码生成能力,结合迭代学习框架,让LLM在数据驱动的反馈下逐步优化生成的CP。通过“综合、执行、调试、指导”的循环,LLM可以从错误中学习,提高CP的准确性和简洁性。
技术框架:整体框架包含以下几个主要阶段:1) 综合 (Synthesize):LLM根据给定的表型描述,生成初始的CP代码。2) 执行 (Execute):在真实或模拟的医疗数据上执行生成的CP代码。3) 调试 (Debug):分析执行结果,识别CP代码中的错误或不足。4) 指导 (Instruct):根据调试结果,向LLM提供反馈,指导其改进CP代码。这个循环迭代进行,直到CP的性能达到预定的标准。
关键创新:最重要的创新点在于将大型语言模型的代码生成能力与迭代学习框架相结合,实现可计算表型的自动生成和优化。与传统的机器学习方法相比,该方法需要的训练数据更少,且生成的CP具有良好的可解释性。
关键设计:论文使用了特定的提示工程技术来引导LLM生成CP代码。例如,提示中包含了表型的详细描述、输入数据的格式、以及期望的输出结果。此外,论文还设计了有效的反馈机制,用于指导LLM进行代码调试。具体的参数设置和损失函数等技术细节在论文中没有详细描述,属于未知信息。
🖼️ 关键图片


📊 实验亮点
实验结果表明,该方法在六种不同复杂程度的临床表型上均取得了良好的效果。与传统的机器学习方法相比,该方法在需要显著更少的训练样本的情况下,性能接近甚至超过了最先进的机器学习方法。这表明该方法具有很强的泛化能力和实用价值。
🎯 应用场景
该研究成果可应用于临床决策支持系统,帮助医生更准确地识别和诊断难治性高血压患者,并制定个性化的治疗方案。此外,该方法还可以推广到其他疾病的表型分析和临床决策支持,具有广阔的应用前景。未来,该技术有望降低医疗成本,提高医疗质量。
📄 摘要(原文)
Large language models (LLMs) have demonstrated remarkable capabilities for medical question answering and programming, but their potential for generating interpretable computable phenotypes (CPs) is under-explored. In this work, we investigate whether LLMs can generate accurate and concise CPs for six clinical phenotypes of varying complexity, which could be leveraged to enable scalable clinical decision support to improve care for patients with hypertension. In addition to evaluating zero-short performance, we propose and test a synthesize, execute, debug, instruct strategy that uses LLMs to generate and iteratively refine CPs using data-driven feedback. Our results show that LLMs, coupled with iterative learning, can generate interpretable and reasonably accurate programs that approach the performance of state-of-the-art ML methods while requiring significantly fewer training examples.