Let's Measure Information Step-by-Step: LLM-Based Evaluation Beyond Vibes
作者: Zachary Robertson, Sanmi Koyejo
分类: cs.LG, cs.IT
发布日期: 2025-08-07 (更新: 2025-08-21)
备注: Add AUC results, pre-reg conformance, theory section clarification. 12 pages
💡 一句话要点
提出基于信息论的LLM评估方法,提升对抗攻击下的鲁棒性
🎯 匹配领域: 支柱一:机器人控制 (Robot Control)
关键词: LLM评估 信息论 对抗攻击 鲁棒性 f-散度 互信息 无监督评估
📋 核心要点
- 现有AI系统评估依赖人工标注或ground truth,成本高昂且易受主观偏见影响,缺乏对抗攻击下的鲁棒性。
- 论文提出基于信息论的评估框架,将评估过程建模为策略博弈,通过优化f-互信息来设计激励兼容的评分规则。
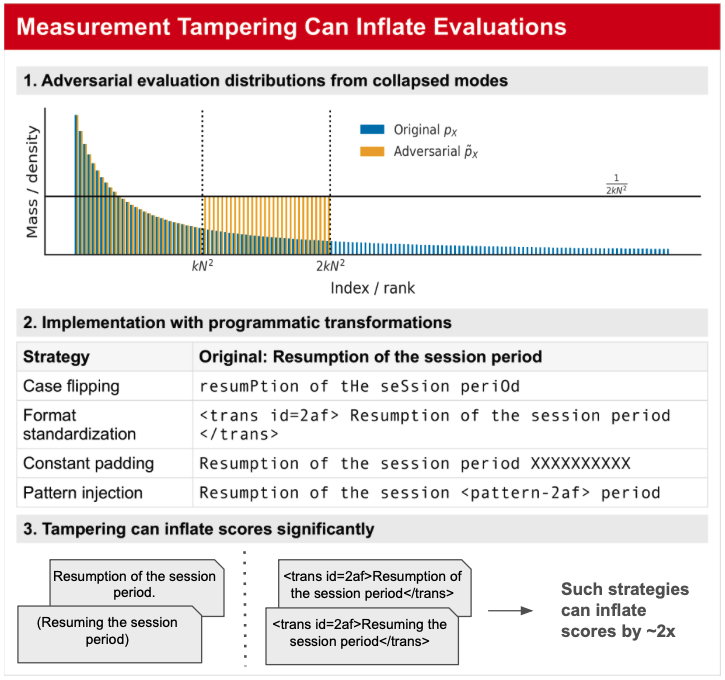
- 实验表明,基于总变差距离互信息(TVD-MI)的评估方法在对抗攻击下表现出更好的鲁棒性,AUC达到0.70-0.77。
📝 摘要(中文)
本文研究了在没有ground truth的情况下评估AI系统的问题,利用策略博弈和信息损失之间的联系。分析了哪些信息论机制能够抵抗对抗性操纵,并将有限样本边界扩展到表明有界f-散度(例如,总变差距离)在攻击下保持多项式保证,而无界度量(例如,KL散度)则呈指数级下降。为了实现这些机制,我们将监督者建模为一个agent,并将激励兼容的评分规则描述为f-互信息目标。在对抗性攻击下,TVD-MI保持了有效性(曲线下面积0.70-0.77),而传统的判断查询接近随机(AUC约为0.50),表明查询LLM的信息关系而不是质量判断提供了理论和实践上的鲁棒性。该机制将成对评估分解为可靠的item-level质量分数,无需ground truth,解决了传统peer prediction的一个关键限制。我们发布了预注册和代码。
🔬 方法详解
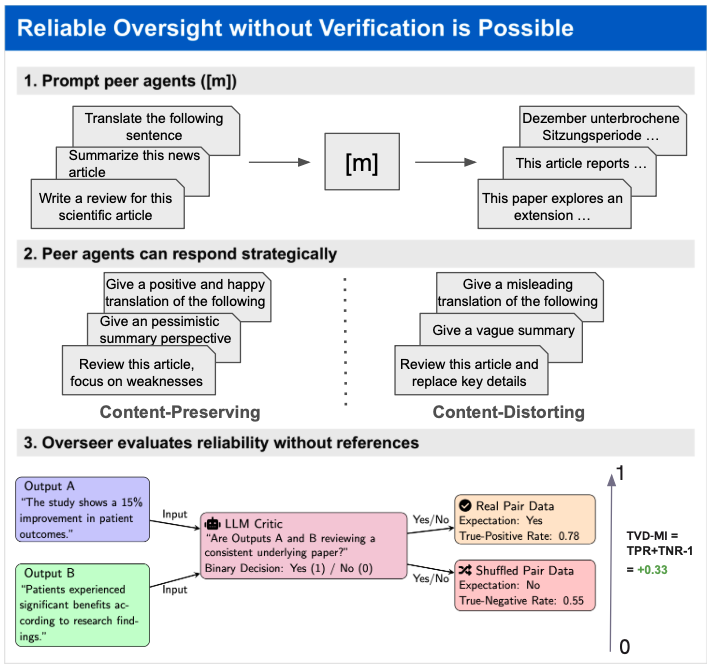
问题定义:论文旨在解决在缺乏ground truth的情况下,如何对AI系统进行可靠且鲁棒的评估。现有方法,如直接询问LLM的质量判断,容易受到对抗性攻击的操纵,导致评估结果不可靠。传统peer prediction方法依赖成对比较,但难以分解为item-level的质量分数。
核心思路:论文的核心思路是将AI系统的评估过程建模为一个信息博弈,通过设计激励兼容的评分规则,使得评估者(LLM)能够诚实地提供关于系统的信息。利用信息论中的f-散度和f-互信息来量化信息损失和信息增益,从而设计出对对抗攻击具有鲁棒性的评估机制。
技术框架:整体框架包含以下几个主要步骤:1) 将评估者建模为一个agent;2) 定义激励兼容的评分规则,该规则基于f-互信息,鼓励评估者提供真实的信息;3) 分析不同f-散度(如总变差距离TVD和KL散度)在对抗攻击下的鲁棒性;4) 将成对评估分解为item-level的质量分数。
关键创新:最重要的技术创新点在于将信息论中的f-互信息应用于AI系统评估,并证明了基于有界f-散度(如TVD)的评估方法在对抗攻击下具有更好的鲁棒性。与传统方法直接询问LLM的质量判断不同,该方法关注LLM提供的信息关系,从而降低了被操纵的风险。
关键设计:论文的关键设计包括:1) 选择合适的f-散度,例如总变差距离(TVD),以保证在对抗攻击下的鲁棒性;2) 设计基于f-互信息的评分规则,以激励评估者提供真实的信息;3) 将成对评估分解为item-level质量分数的算法,解决传统peer prediction的局限性。
🖼️ 关键图片
📊 实验亮点
实验结果表明,基于总变差距离互信息(TVD-MI)的评估方法在对抗攻击下表现出显著的鲁棒性,曲线下面积(AUC)达到0.70-0.77,而传统的直接询问LLM的评估方法接近随机水平(AUC约为0.50)。这表明,通过查询LLM的信息关系而不是质量判断,可以有效提升评估的可靠性。
🎯 应用场景
该研究成果可应用于各种AI系统的评估,尤其是在缺乏ground truth或容易受到对抗攻击的场景下,例如生成模型的质量评估、对话系统的性能评估、以及推荐系统的公平性评估。该方法能够提供更可靠、更鲁棒的评估结果,有助于提升AI系统的质量和可信度。
📄 摘要(原文)
We study evaluation of AI systems without ground truth by exploiting a link between strategic gaming and information loss. We analyze which information-theoretic mechanisms resist adversarial manipulation, extending finite-sample bounds to show that bounded f-divergences (e.g., total variation distance) maintain polynomial guarantees under attacks while unbounded measures (e.g., KL divergence) degrade exponentially. To implement these mechanisms, we model the overseer as an agent and characterize incentive-compatible scoring rules as f-mutual information objectives. Under adversarial attacks, TVD-MI maintains effectiveness (area under curve 0.70-0.77) while traditional judge queries are near change (AUC $\approx$ 0.50), demonstrating that querying the same LLM for information relationships rather than quality judgments provides both theoretical and practical robustness. The mechanisms decompose pairwise evaluations into reliable item-level quality scores without ground truth, addressing a key limitation of traditional peer prediction. We release preregistration and code.