Multimodal LLM-assisted Evolutionary Search for Programmatic Control Policies
作者: Qinglong Hu, Xialiang Tong, Mingxuan Yuan, Fei Liu, Zhichao Lu, Qingfu Zhang
分类: cs.LG, cs.NE
发布日期: 2025-08-07 (更新: 2025-10-31)
💡 一句话要点
提出MLES:利用多模态LLM辅助进化搜索生成可解释程序化控制策略
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态学习 大语言模型 进化搜索 程序化控制 可解释性
📋 核心要点
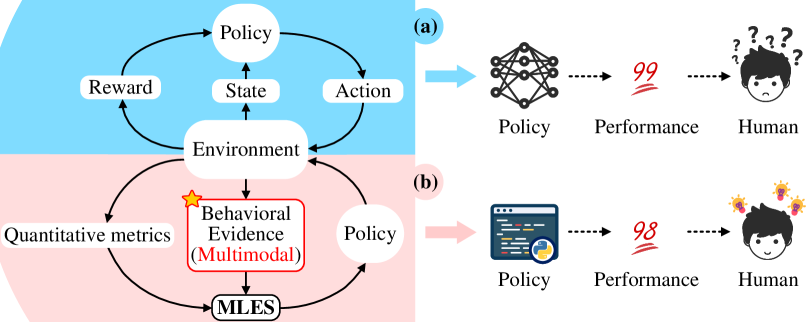
- 深度强化学习策略不透明,难以理解和调试,限制了其在实际控制任务中的应用。
- MLES利用多模态LLM生成程序化策略,结合进化搜索和视觉反馈,提升策略发现效率。
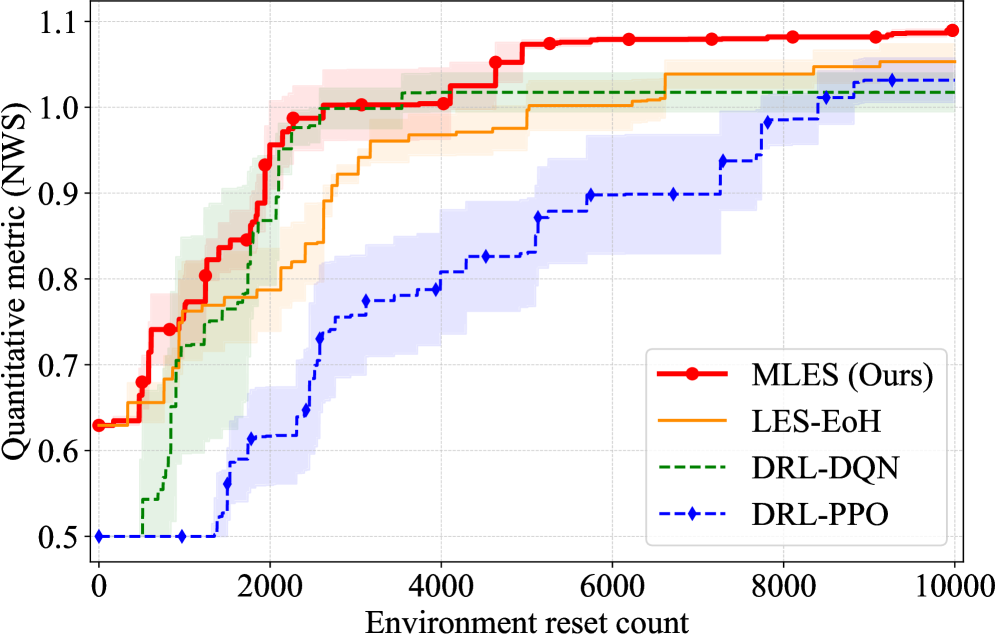
- 实验表明,MLES在性能上与PPO相当,同时提供了透明的控制逻辑和可追溯的设计过程。
📝 摘要(中文)
深度强化学习在控制任务中取得了显著成功,但其策略通常表示为不透明的神经网络,难以理解、验证和调试,从而降低了信任度并阻碍了实际部署。本文提出了一种新的程序化控制策略发现方法,称为多模态大语言模型辅助进化搜索(MLES)。MLES利用多模态大语言模型作为程序化策略生成器,并结合进化搜索来自动化策略生成。它在策略生成过程中集成了视觉反馈驱动的行为分析,以识别失败模式并指导有针对性的改进,从而提高策略发现效率并生成适应性强、符合人类认知的策略。实验结果表明,MLES在两个标准控制任务中实现了与近端策略优化(PPO)相当的性能,同时提供了透明的控制逻辑和可追溯的设计过程。该方法还克服了预定义的领域特定语言的局限性,促进了知识转移和重用,并且可以在各种任务中扩展,显示出作为开发透明且可验证的控制策略的新范例的潜力。
🔬 方法详解
问题定义:现有深度强化学习方法生成的控制策略通常以神经网络的形式存在,缺乏透明性和可解释性。这使得人类难以理解策略的决策过程,难以验证策略的正确性,也难以在出现问题时进行调试。因此,需要一种能够生成可解释、可验证的控制策略的方法。
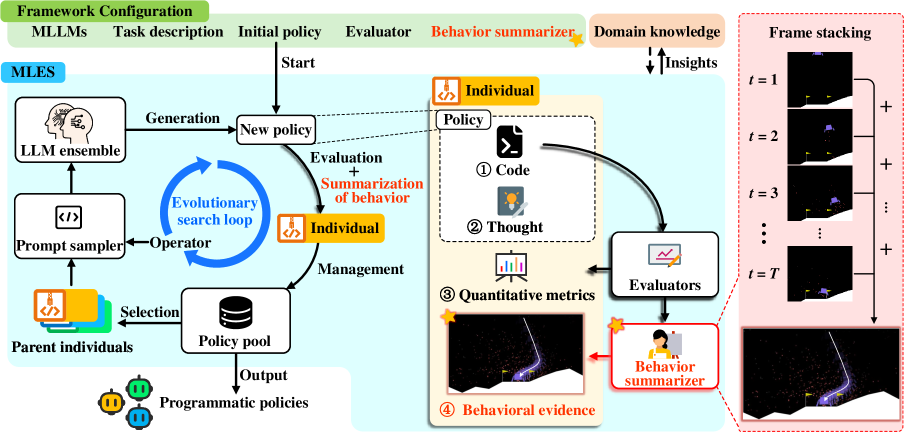
核心思路:MLES的核心思路是利用多模态大语言模型(LLM)作为程序化策略的生成器,并结合进化搜索算法来自动发现有效的控制策略。通过LLM生成易于理解和修改的程序化代码,并通过进化搜索来优化这些代码,使其在控制任务中表现良好。视觉反馈驱动的行为分析用于识别策略的不足之处,并指导LLM生成更有效的策略。
技术框架:MLES的整体框架包含以下几个主要模块:1) 多模态LLM策略生成器:接收任务描述和视觉反馈,生成程序化的控制策略代码。2) 进化搜索算法:使用遗传算法等进化策略来搜索最优的策略参数。3) 环境交互模块:将生成的策略部署到控制环境中,并收集环境反馈。4) 视觉反馈分析模块:分析策略在环境中的行为,提取视觉特征,并识别失败模式,为LLM提供改进策略的指导。
关键创新:MLES的关键创新在于将多模态LLM与进化搜索相结合,用于生成程序化的控制策略。与传统的深度强化学习方法相比,MLES生成的策略具有更高的透明性和可解释性。此外,MLES利用视觉反馈驱动的行为分析来指导策略的改进,从而提高了策略发现的效率。与预定义的领域特定语言相比,MLES利用LLM可以生成更灵活、更通用的控制策略。
关键设计:MLES的关键设计包括:1) 多模态LLM的选择和训练:选择具有代码生成能力的LLM,并使用控制任务相关的数据进行微调,使其能够生成有效的控制策略代码。2) 视觉反馈的表示和利用:使用卷积神经网络等方法提取环境的视觉特征,并将其作为LLM的输入,指导策略的改进。3) 进化搜索算法的参数设置:设置合适的种群大小、交叉概率和变异概率等参数,以保证进化搜索的效率和效果。4) 奖励函数的设计:设计能够反映控制任务目标的奖励函数,引导策略向期望的方向进化。
🖼️ 关键图片
📊 实验亮点
实验结果表明,MLES在两个标准控制任务(CartPole和Acrobot)中取得了与PPO相当的性能。更重要的是,MLES生成的策略具有更高的透明性和可解释性,并且可以通过视觉反馈进行改进。例如,在CartPole任务中,MLES能够生成清晰的平衡杆的程序化控制策略,并且可以通过分析杆的倾斜角度和角速度来调整策略参数。
🎯 应用场景
MLES具有广泛的应用前景,例如在机器人控制、自动驾驶、智能制造等领域。它可以用于生成可解释、可验证的控制策略,提高系统的可靠性和安全性。此外,MLES还可以促进人机协作,使人类能够更容易地理解和调试控制策略,从而提高工作效率。
📄 摘要(原文)
Deep reinforcement learning has achieved impressive success in control tasks. However, its policies, represented as opaque neural networks, are often difficult for humans to understand, verify, and debug, which undermines trust and hinders real-world deployment. This work addresses this challenge by introducing a novel approach for programmatic control policy discovery, called Multimodal Large Language Model-assisted Evolutionary Search (MLES). MLES utilizes multimodal large language models as programmatic policy generators, combining them with evolutionary search to automate policy generation. It integrates visual feedback-driven behavior analysis within the policy generation process to identify failure patterns and guide targeted improvements, thereby enhancing policy discovery efficiency and producing adaptable, human-aligned policies. Experimental results demonstrate that MLES achieves performance comparable to Proximal Policy Optimization (PPO) across two standard control tasks while providing transparent control logic and traceable design processes. This approach also overcomes the limitations of predefined domain-specific languages, facilitates knowledge transfer and reuse, and is scalable across various tasks, showing promise as a new paradigm for developing transparent and verifiable control policies.