FlowState: Sampling Rate Invariant Time Series Forecasting
作者: Lars Graf, Thomas Ortner, Stanisław Woźniak, Angeliki Pantazi
分类: cs.LG, cs.AI
发布日期: 2025-08-07 (更新: 2025-08-19)
备注: Currently under review
💡 一句话要点
FlowState:一种采样率不变的时间序列预测框架,提升泛化性和效率。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 时间序列预测 状态空间模型 采样率不变性 基础模型 零样本学习
📋 核心要点
- 现有时间序列基础模型难以泛化到不同采样率和预测长度,且计算效率低。
- FlowState采用基于状态空间模型的编码器和函数基解码器,实现连续时间建模和动态时间尺度调整。
- FlowState在GIFT-ZS和Chronos-ZS基准测试中表现SOTA,并能在线适应不同采样率。
📝 摘要(中文)
基础模型(FMs)已经变革了自然语言处理领域,但其成功尚未转化为时间序列预测。现有的时间序列基础模型(TSFMs),通常基于Transformer变体,难以在不同的上下文和目标长度上泛化,缺乏对不同采样率的适应性,并且计算效率低下。我们引入FlowState,一种新颖的TSFM架构,通过两个关键创新来解决这些挑战:基于状态空间模型(SSM)的编码器和函数基解码器。这种设计实现了连续时间建模和动态时间尺度调整,使FlowState能够固有地泛化到所有可能的时间分辨率,并动态调整预测范围。与其他最先进的TSFM相比,FlowState不需要跨所有可能的采样率的训练数据来记忆每个尺度的模式,而是固有地将其内部动态适应于输入尺度,从而减少了模型大小、数据需求并提高了效率。我们进一步提出了一种有效的预训练策略,以提高鲁棒性并加速训练。尽管是最小的模型,FlowState优于所有其他模型,并且是GIFT-ZS和Chronos-ZS基准测试的最新技术。消融研究证实了其组件的有效性,并且我们证明了其在线适应不同输入采样率的独特能力。
🔬 方法详解
问题定义:现有的时间序列预测模型,特别是基于Transformer的TSFM,在处理不同采样率的时间序列数据时存在泛化能力不足的问题。它们通常需要针对每种采样率进行单独训练,导致模型体积庞大、训练数据需求高,且难以适应动态变化的采样率。此外,这些模型在处理不同长度的上下文和预测目标时也面临挑战。
核心思路:FlowState的核心思路是利用状态空间模型(SSM)的连续时间建模能力,以及函数基解码器的灵活性,构建一个采样率不变的时间序列预测模型。通过将时间序列数据编码到连续的状态空间中,FlowState能够学习到与采样率无关的内在动态,从而实现对不同采样率数据的统一处理。函数基解码器则允许模型动态调整预测范围,适应不同的预测目标长度。
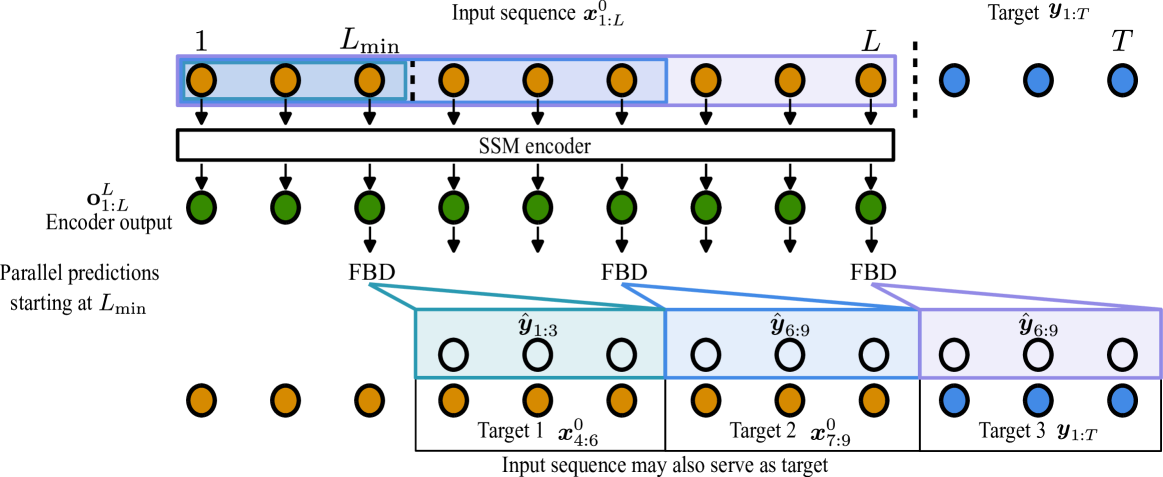
技术框架:FlowState的整体架构包括两个主要模块:一个基于状态空间模型(SSM)的编码器和一个函数基解码器。编码器将输入的时间序列数据映射到连续的状态空间中,提取与采样率无关的特征表示。解码器则利用这些特征表示,结合函数基,生成预测的时间序列。预训练阶段采用一种高效的策略,以提高模型的鲁棒性和加速训练。
关键创新:FlowState最重要的技术创新在于其采样率不变性。与需要针对每种采样率进行单独训练的现有方法不同,FlowState能够自动适应不同的采样率,无需额外的训练数据。这种能力源于其基于状态空间模型的编码器,该编码器能够学习到与采样率无关的内在动态。此外,函数基解码器的设计也使得模型能够灵活地调整预测范围。
关键设计:FlowState的关键设计包括:1) 使用HiPPO算子构建状态空间模型,以有效地捕捉时间序列的长期依赖关系;2) 采用函数基(如多项式基或傅里叶基)作为解码器的输出,以实现对预测时间序列的灵活表示;3) 设计了一种对比学习的预训练策略,通过最大化不同时间尺度下时间序列表示的一致性,提高模型的鲁棒性。具体的参数设置和网络结构细节在论文中有详细描述,但此处未知。
🖼️ 关键图片

📊 实验亮点
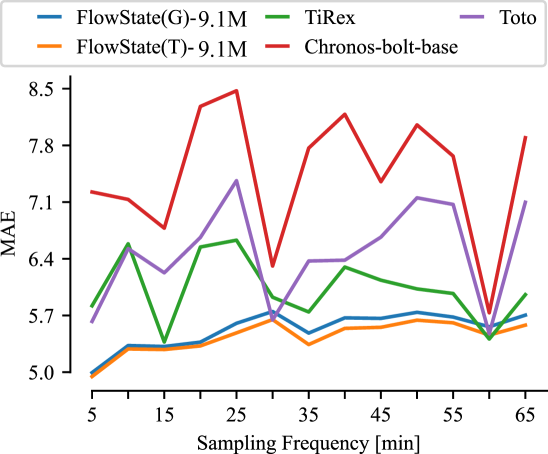
FlowState在GIFT-ZS和Chronos-ZS零样本时间序列预测基准测试中取得了SOTA结果,显著优于其他TSFM模型。实验结果表明,FlowState在模型尺寸最小的情况下,依然能够达到最佳的预测精度,验证了其高效性和泛化能力。消融实验进一步证实了状态空间模型编码器和函数基解码器对模型性能的贡献。此外,论文还展示了FlowState能够在线适应不同输入采样率的独特能力。
🎯 应用场景
FlowState具有广泛的应用前景,包括金融时间序列预测、物联网传感器数据分析、医疗健康监测等领域。其采样率不变性使其能够处理来自不同来源、具有不同采样率的数据,从而降低了数据预处理的复杂性。此外,FlowState还可以应用于在线时间序列预测,实时适应动态变化的采样率,具有重要的实际价值。未来,FlowState有望成为时间序列基础模型的重要组成部分,推动时间序列分析技术的进一步发展。
📄 摘要(原文)
Foundation models (FMs) have transformed natural language processing, but their success has not yet translated to time series forecasting. Existing time series foundation models (TSFMs), often based on transformer variants, struggle with generalization across varying context and target lengths, lack adaptability to different sampling rates, and are computationally inefficient. We introduce FlowState, a novel TSFM architecture that addresses these challenges through two key innovations: a state space model (SSM) based encoder and a functional basis decoder. This design enables continuous-time modeling and dynamic time-scale adjustment, allowing FlowState to inherently generalize across all possible temporal resolutions, and dynamically adjust the forecasting horizons. In contrast to other state-of-the-art TSFMs, which require training data across all possible sampling rates to memorize patterns at each scale, FlowState inherently adapts its internal dynamics to the input scale, enabling smaller models, reduced data requirements, and improved efficiency. We further propose an efficient pretraining strategy that improves robustness and accelerates training. Despite being the smallest model, FlowState outperforms all other models and is state-of-the-art for the GIFT-ZS and the Chronos-ZS benchmarks. Ablation studies confirm the effectiveness of its components, and we demonstrate its unique ability to adapt online to varying input sampling rates.