Cross-LoRA: A Data-Free LoRA Transfer Framework across Heterogeneous LLMs
作者: Feifan Xia, Mingyang Liao, Yuyang Fang, Defang Li, Yantong Xie, Weikang Li, Yang Li, Deguo Xia, Jizhou Huang
分类: cs.LG
发布日期: 2025-08-07
💡 一句话要点
提出Cross-LoRA,解决异构LLM间LoRA模块免数据迁移问题
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 参数高效微调 LoRA迁移 异构LLM 免数据学习 子空间对齐
📋 核心要点
- 现有LoRA等参数高效微调方法与基础模型架构紧密耦合,限制了其在异构预训练LLM间的应用。
- Cross-LoRA通过LoRA-Align进行子空间对齐,并利用LoRA-Shift将源LoRA权重更新投影到目标模型,实现免数据迁移。
- 实验表明,Cross-LoRA在多个常识推理任务上取得了显著的性能提升,甚至可以媲美直接训练的LoRA适配器。
📝 摘要(中文)
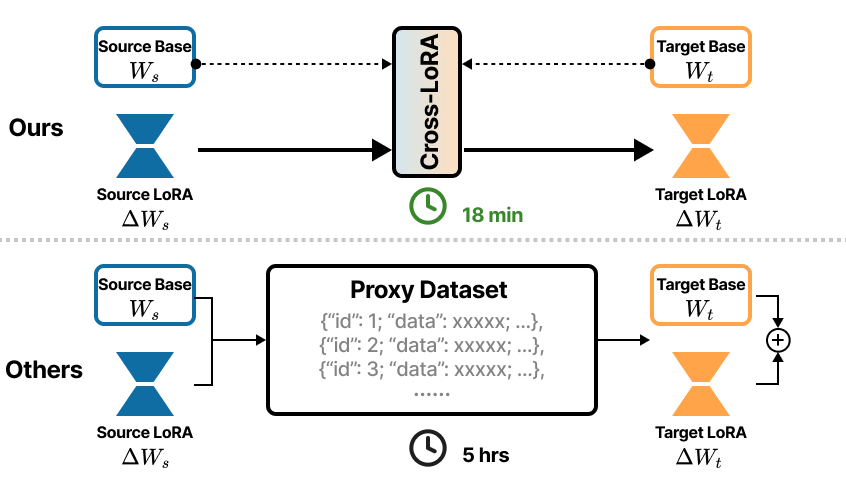
本文提出Cross-LoRA,一个免数据的框架,用于在异构大型语言模型(LLM)之间迁移LoRA模块,无需额外训练数据。Cross-LoRA包含两个关键组件:(a) LoRA-Align,通过秩截断奇异值分解(SVD)和Frobenius最优线性变换,在源模型和目标模型之间执行子空间对齐,确保维度不匹配时的兼容性;(b) LoRA-Shift,将对齐的子空间应用于将源LoRA权重更新投影到目标模型参数空间。这两个组件都是免数据的、免训练的,并且能够在消费级GPU上以轻量级的方式在20分钟内完成适配。在ARCs、OBOA和HellaSwag上的实验表明,Cross-LoRA相对于基础模型实现了高达5.26%的相对增益。在其他常识推理基准测试中,Cross-LoRA保持了与直接训练的LoRA适配器相当的性能。
🔬 方法详解
问题定义:现有参数高效微调方法(如LoRA)严重依赖于特定的大型语言模型架构,导致训练好的LoRA模块无法直接迁移到架构不同的其他LLM上。这限制了LoRA的通用性和可复用性,阻碍了知识在不同模型间的有效传递。因此,需要一种方法能够在异构LLM之间迁移LoRA模块,而无需重新训练或使用额外的数据。
核心思路:Cross-LoRA的核心思路是找到源模型和目标模型之间LoRA子空间的对应关系,并将源模型的LoRA权重映射到目标模型的参数空间。通过子空间对齐,解决维度不匹配的问题;通过权重投影,实现知识的有效迁移。整个过程无需额外数据,从而保证了高效性和通用性。
技术框架:Cross-LoRA框架主要包含两个阶段:LoRA-Align和LoRA-Shift。首先,LoRA-Align模块利用秩截断奇异值分解(SVD)和Frobenius最优线性变换,对源模型和目标模型的LoRA子空间进行对齐,解决维度不匹配问题。然后,LoRA-Shift模块将对齐后的子空间用于将源LoRA权重更新投影到目标模型的参数空间,完成知识迁移。
关键创新:Cross-LoRA的关键创新在于提出了一个完全免数据的LoRA迁移框架,能够在异构LLM之间实现知识共享。与传统的LoRA微调方法相比,Cross-LoRA无需额外训练数据,大大降低了迁移成本。此外,通过子空间对齐和权重投影,Cross-LoRA能够有效地解决维度不匹配问题,保证了迁移后的性能。
关键设计:LoRA-Align模块使用秩截断SVD来提取源模型和目标模型LoRA子空间的主要成分,并通过Frobenius最优线性变换来最小化对齐误差。LoRA-Shift模块利用对齐后的子空间,将源LoRA权重更新投影到目标模型的参数空间。具体而言,LoRA-Align的目标是找到一个线性变换矩阵,使得源模型和目标模型的LoRA子空间尽可能接近。这个线性变换矩阵可以通过求解一个最小化Frobenius范数的优化问题得到。
🖼️ 关键图片

📊 实验亮点
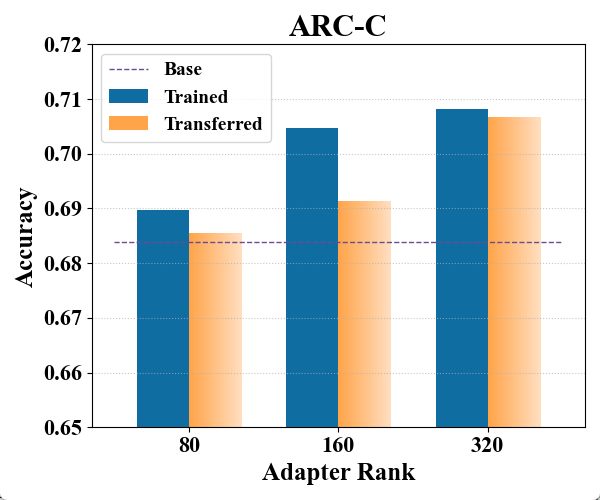
实验结果表明,Cross-LoRA在ARCs、OBOA和HellaSwag等常识推理基准测试上,相对于基础模型实现了高达5.26%的相对增益。更重要的是,在其他常识推理基准测试中,Cross-LoRA保持了与直接训练的LoRA适配器相当的性能,证明了其在异构LLM之间迁移知识的有效性。
🎯 应用场景
Cross-LoRA在实际应用中具有广泛的潜力,例如,可以将针对特定任务在某个LLM上训练好的LoRA模块迁移到资源受限的设备上运行的轻量级LLM,实现知识的快速部署和迁移。此外,Cross-LoRA还可以用于构建一个共享的LoRA模块库,方便用户在不同的LLM之间共享和复用知识,加速LLM的应用和发展。
📄 摘要(原文)
Traditional parameter-efficient fine-tuning (PEFT) methods such as LoRA are tightly coupled with the base model architecture, which constrains their applicability across heterogeneous pretrained large language models (LLMs). To address this limitation, we introduce Cross-LoRA, a data-free framework for transferring LoRA modules between diverse base models without requiring additional training data. Cross-LoRA consists of two key components: (a) LoRA-Align, which performs subspace alignment between source and target base models through rank-truncated singular value decomposition (SVD) and Frobenius-optimal linear transformation, ensuring compatibility under dimension mismatch; and (b) LoRA-Shift, which applies the aligned subspaces to project source LoRA weight updates into the target model parameter space. Both components are data-free, training-free, and enable lightweight adaptation on a commodity GPU in 20 minutes. Experiments on ARCs, OBOA and HellaSwag show that Cross-LoRA achieves relative gains of up to 5.26% over base models. Across other commonsense reasoning benchmarks, Cross-LoRA maintains performance comparable to that of directly trained LoRA adapters.