Reasoning through Exploration: A Reinforcement Learning Framework for Robust Function Calling
作者: Bingguang Hao, Zengzhuang Xu, Maolin Wang, Yuntao Wen, Yicheng Chen, Cunyin Peng, Long Chen, Dong Wang, Xiangyu Zhao, Jinjie Gu, Chenyi Zhuang, Ji Zhang
分类: cs.LG, cs.AI, cs.CL
发布日期: 2025-08-07 (更新: 2025-10-10)
💡 一句话要点
提出基于探索性推理的强化学习框架EGPO,提升LLM函数调用能力
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 函数调用 强化学习 大型语言模型 探索性推理 策略优化
📋 核心要点
- 现有监督微调(SFT)方法难以使LLM具备鲁棒的推理能力,而传统强化学习(RL)方法则面临探索效率低下的问题。
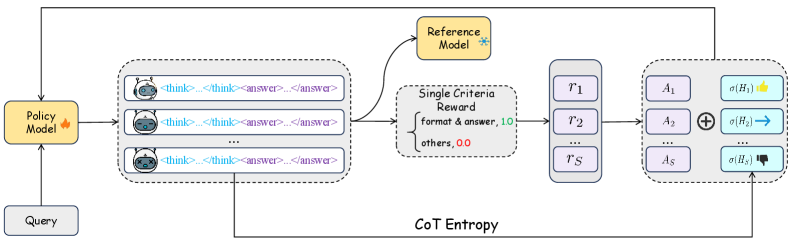
- EGPO通过引入熵增强的优势函数,鼓励模型探索多样化的推理策略,并使用裁剪机制约束熵奖励,维持优化方向。
- 实验表明,EGPO训练的4B参数模型在BFCL上超越了GPT-4o和Gemini-2.5等模型,达到了新的SOTA。
📝 摘要(中文)
本文提出了一种新的强化学习框架EGPO,用于解决大型语言模型(LLM)在函数调用训练中面临的挑战,即如何在复杂推理路径的探索与稳定策略优化之间取得平衡。EGPO构建于Group Relative Policy Optimization (GRPO)之上,其核心在于一个熵增强的优势函数,该函数将模型的思维链(CoT)熵值整合到策略梯度计算中,从而鼓励生成多样化的推理策略。为了维持优化方向,熵奖励通过一个裁剪机制进行约束。结合严格的二元奖励信号,EGPO有效地引导模型发现结构化和准确的工具调用模式。在具有挑战性的Berkeley Function Calling Leaderboard (BFCL)上,一个使用EGPO训练的40亿参数模型在同等规模的模型中取得了新的state-of-the-art,超越了包括GPT-4o和Gemini-2.5在内的一系列强劲竞争对手。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLM)在函数调用任务中,如何有效探索复杂推理路径并进行稳定策略优化的问题。现有方法,如监督微调(SFT),无法赋予模型鲁棒的推理能力;而传统强化学习(RL)方法在探索过程中效率低下,难以找到最优的函数调用模式。
核心思路:论文的核心思路是利用强化学习,并结合熵正则化来鼓励模型进行更广泛的探索,同时通过裁剪机制来保证策略优化的稳定性。通过这种方式,模型能够学习到更有效、更准确的函数调用策略。
技术框架:EGPO框架基于Group Relative Policy Optimization (GRPO)。主要流程包括:首先,LLM生成思维链(CoT),进行推理;然后,计算熵增强的优势函数,该函数将CoT的熵值纳入考虑;接着,使用裁剪机制约束熵奖励,防止策略偏移过大;最后,根据二元奖励信号更新模型参数。
关键创新:EGPO的关键创新在于熵增强的优势函数和裁剪机制。熵增强的优势函数鼓励模型探索不同的推理路径,而裁剪机制则保证了策略优化的稳定性。与传统RL方法相比,EGPO能够更有效地探索复杂推理路径,并学习到更鲁棒的函数调用策略。
关键设计:EGPO的关键设计包括:1) 熵增强的优势函数,具体形式未知,但其核心是将CoT的熵值纳入优势函数计算中;2) 裁剪机制,用于限制熵奖励的范围,防止策略偏移过大;3) 二元奖励信号,用于指导模型学习正确的函数调用模式。具体参数设置和网络结构细节未知。
🖼️ 关键图片

📊 实验亮点
EGPO训练的4B参数模型在Berkeley Function Calling Leaderboard (BFCL)上取得了显著成果,超越了包括GPT-4o和Gemini-2.5在内的多个强大基线模型,在同等规模模型中达到了新的state-of-the-art。这表明EGPO能够有效提升LLM的函数调用能力,使其在复杂任务中表现更出色。
🎯 应用场景
该研究成果可应用于智能助手、自动化客服、智能家居等领域,提升LLM在复杂任务中的问题解决能力。通过更有效地利用外部工具和API,LLM可以更好地理解用户意图,并提供更准确、更个性化的服务,从而提高用户体验和工作效率。未来,该方法有望扩展到更多需要复杂推理和决策的任务中。
📄 摘要(原文)
The effective training of Large Language Models (LLMs) for function calling faces a critical challenge: balancing exploration of complex reasoning paths with stable policy optimization. Standard methods like Supervised Fine-Tuning (SFT) fail to instill robust reasoning, and traditional Reinforcement Learning (RL) struggles with inefficient exploration. We propose \textbf{EGPO}, a new RL framework built upon Group Relative Policy Optimization (GRPO), designed to address this challenge directly. The core of EGPO is an entropy-enhanced advantage function that integrates the entropy of the model's Chain-of-Thought (CoT) into the policy gradient computation. This encourages the generation of diverse reasoning strategies. To maintain optimization direction, the entropy bonus is carefully constrained by a clipping mechanism. Complemented by a strict, binary reward signal, EGPO effectively guides the model towards discovering structured and accurate tool invocation patterns. On the challenging Berkeley Function Calling Leaderboard (BFCL), a 4B-parameter model trained with EGPO sets a new state-of-the-art among models of comparable size, surpassing a range of strong competitors, including GPT-4o and Gemini-2.5.