R-Zero: Self-Evolving Reasoning LLM from Zero Data
作者: Chengsong Huang, Wenhao Yu, Xiaoyang Wang, Hongming Zhang, Zongxia Li, Ruosen Li, Jiaxin Huang, Haitao Mi, Dong Yu
分类: cs.LG, cs.AI, cs.CL
发布日期: 2025-08-07 (更新: 2026-01-09)
💡 一句话要点
R-Zero:一种从零数据自进化的推理大语言模型框架
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 自进化学习 大语言模型 推理能力 零数据学习 挑战者-解决者模型
📋 核心要点
- 现有自进化LLM训练依赖大量人工标注数据,限制了AI超越人类智能的能力。
- R-Zero框架通过挑战者和解决者模型的交互,自主生成训练数据,实现自改进。
- 实验表明,R-Zero显著提升了LLM在数学和通用领域推理任务上的性能。
📝 摘要(中文)
自进化的大语言模型(LLMs)通过自主生成、改进和学习自身的经验,为实现超级智能提供了一条可扩展的路径。然而,现有的训练方法仍然严重依赖于大量人工标注的任务和标签,通常通过微调或强化学习实现,这对于推动人工智能系统超越人类智能的能力构成了根本性的瓶颈。为了克服这一限制,我们提出了R-Zero,一个完全自主的框架,可以从零开始生成自己的训练数据。从一个基础LLM开始,R-Zero初始化两个具有不同角色的独立模型,一个挑战者和一个解决者。这些模型被独立优化,并通过交互共同进化:挑战者因提出接近解决者能力边缘的任务而获得奖励,而解决者因解决挑战者提出的越来越具有挑战性的任务而获得奖励。这个过程产生了一个有针对性的、自我改进的课程,没有任何预先存在的任务和标签。实验表明,R-Zero显著提高了不同骨干LLM的推理能力,例如,在数学推理基准测试中,Qwen3-4B-Base提高了+6.49,在通用领域推理基准测试中提高了+7.54。
🔬 方法详解
问题定义:现有自进化LLM的训练方法依赖于大量人工标注的数据,这限制了模型能力的扩展,特别是超越人类智能的潜力。人工标注成本高昂,且难以覆盖所有可能的任务和场景,成为进一步提升LLM推理能力的瓶颈。
核心思路:R-Zero的核心思路是通过两个相互协作的模型(挑战者和解决者)来模拟一个自学习的环境。挑战者负责生成具有挑战性的任务,而解决者负责解决这些任务。通过奖励机制,鼓励挑战者生成更具挑战性的任务,同时鼓励解决者提升解决问题的能力,从而实现模型的共同进化。这种方式避免了对人工标注数据的依赖,实现了从零开始的自学习。
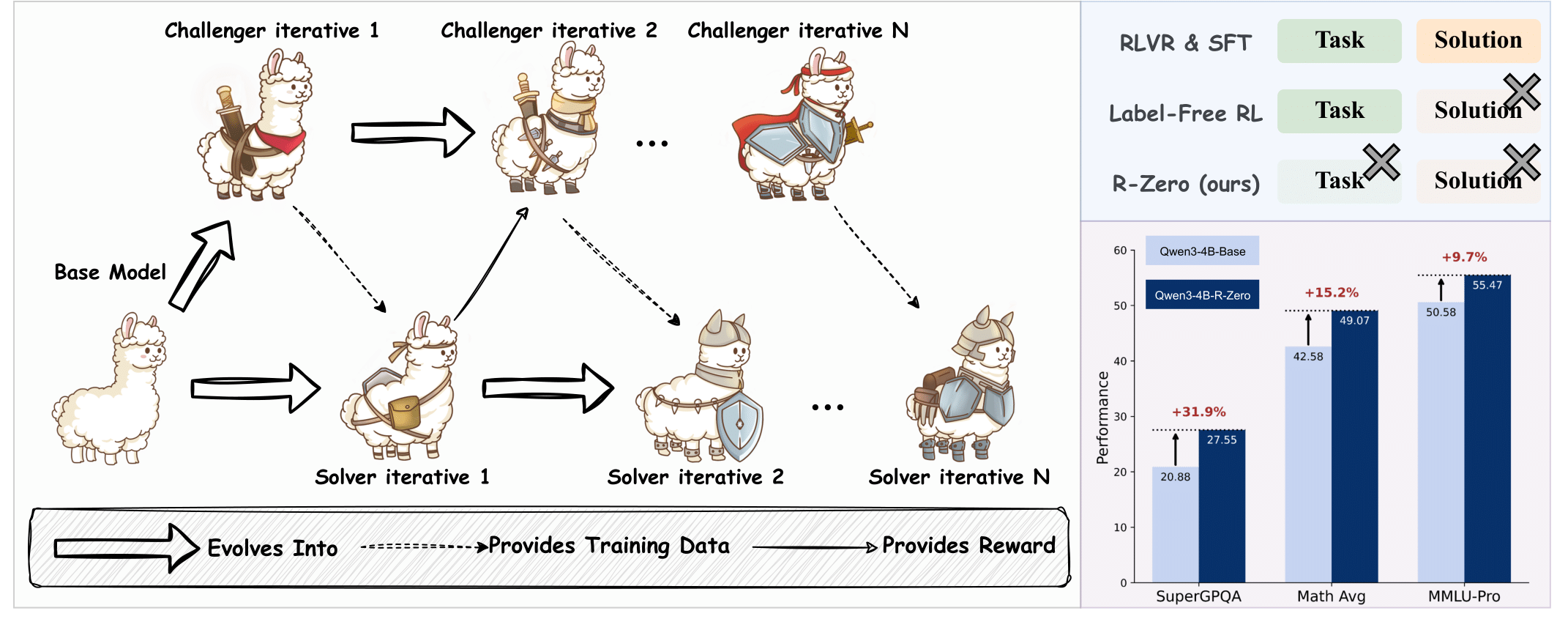
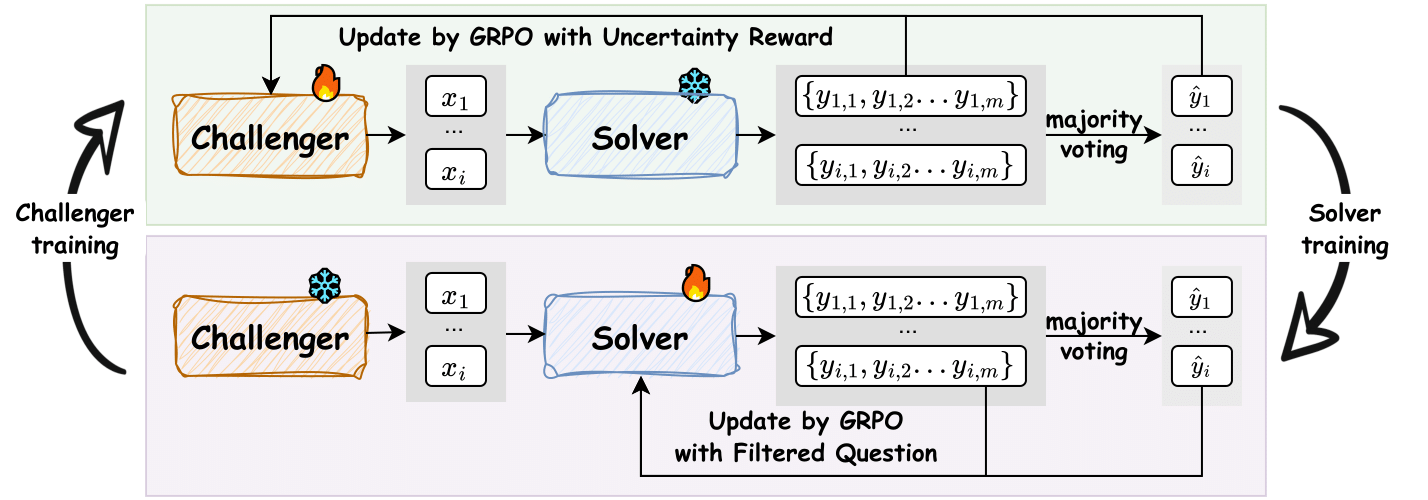
技术框架:R-Zero框架包含两个主要模块:挑战者模型和解决者模型。初始状态下,两个模型都是基于同一个基础LLM。挑战者模型负责生成任务,解决者模型负责解决任务。框架通过一个奖励机制来驱动模型的进化。挑战者根据解决者解决任务的难度获得奖励,解决者根据成功解决任务获得奖励。这个过程迭代进行,不断提升模型的推理能力。
关键创新:R-Zero的关键创新在于其完全自主的数据生成和学习方式。与传统的依赖人工标注数据的训练方法不同,R-Zero能够从零开始生成自己的训练数据,并根据模型的表现动态调整训练目标。这种方式使得模型能够不断探索新的任务和场景,从而实现更强的泛化能力和推理能力。
关键设计:R-Zero的关键设计包括:1) 挑战者模型的任务生成策略,需要保证生成的任务既具有挑战性,又在解决者模型的能力范围内;2) 解决者模型的训练策略,需要保证模型能够有效地学习和解决挑战者生成的任务;3) 奖励机制的设计,需要能够有效地驱动挑战者和解决者模型的共同进化。具体的参数设置和损失函数选择需要根据具体的任务和模型进行调整。
🖼️ 关键图片

📊 实验亮点
R-Zero在多个推理基准测试中取得了显著的性能提升。例如,在Qwen3-4B-Base模型上,R-Zero在数学推理基准测试中提升了+6.49,在通用领域推理基准测试中提升了+7.54。这些结果表明,R-Zero能够有效地提升LLM的推理能力,并且具有良好的泛化能力。
🎯 应用场景
R-Zero具有广泛的应用前景,例如可以用于开发更智能的对话系统、自动编程工具、以及科学研究助手。通过自主学习和进化,R-Zero可以不断提升自身的能力,从而更好地服务于人类。此外,R-Zero还可以用于探索人工智能的极限,推动人工智能技术的发展。
📄 摘要(原文)
Self-evolving Large Language Models (LLMs) offer a scalable path toward super-intelligence by autonomously generating, refining, and learning from their own experiences. However, existing methods for training such models still rely heavily on vast human-curated tasks and labels, typically via fine-tuning or reinforcement learning, which poses a fundamental bottleneck to advancing AI systems toward capabilities beyond human intelligence. To overcome this limitation, we introduce R-Zero, a fully autonomous framework that generates its own training data from scratch. Starting from a single base LLM, R-Zero initializes two independent models with distinct roles, a Challenger and a Solver. These models are optimized separately and co-evolve through interaction: the Challenger is rewarded for proposing tasks near the edge of the Solver capability, and the Solver is rewarded for solving increasingly challenging tasks posed by the Challenger. This process yields a targeted, self-improving curriculum without any pre-existing tasks and labels. Empirically, R-Zero substantially improves reasoning capability across different backbone LLMs, e.g., boosting the Qwen3-4B-Base by +6.49 on math-reasoning benchmarks and +7.54 on general-domain reasoning benchmarks.