Calibrated Language Models and How to Find Them with Label Smoothing
作者: Jerry Huang, Peng Lu, Qiuhao Zeng
分类: cs.LG, cs.AI, stat.ML
发布日期: 2025-08-01 (更新: 2025-10-24)
备注: Accepted to the Forty-second International Conference on Machine Learning (ICML) 2025. First two authors contributed equally. Official proceedings version available at https://proceedings.mlr.press/v267/huang25w.html
💡 一句话要点
使用标签平滑校准指令微调后大语言模型的置信度
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 置信度校准 指令微调 标签平滑 监督微调 内存优化 定制内核
📋 核心要点
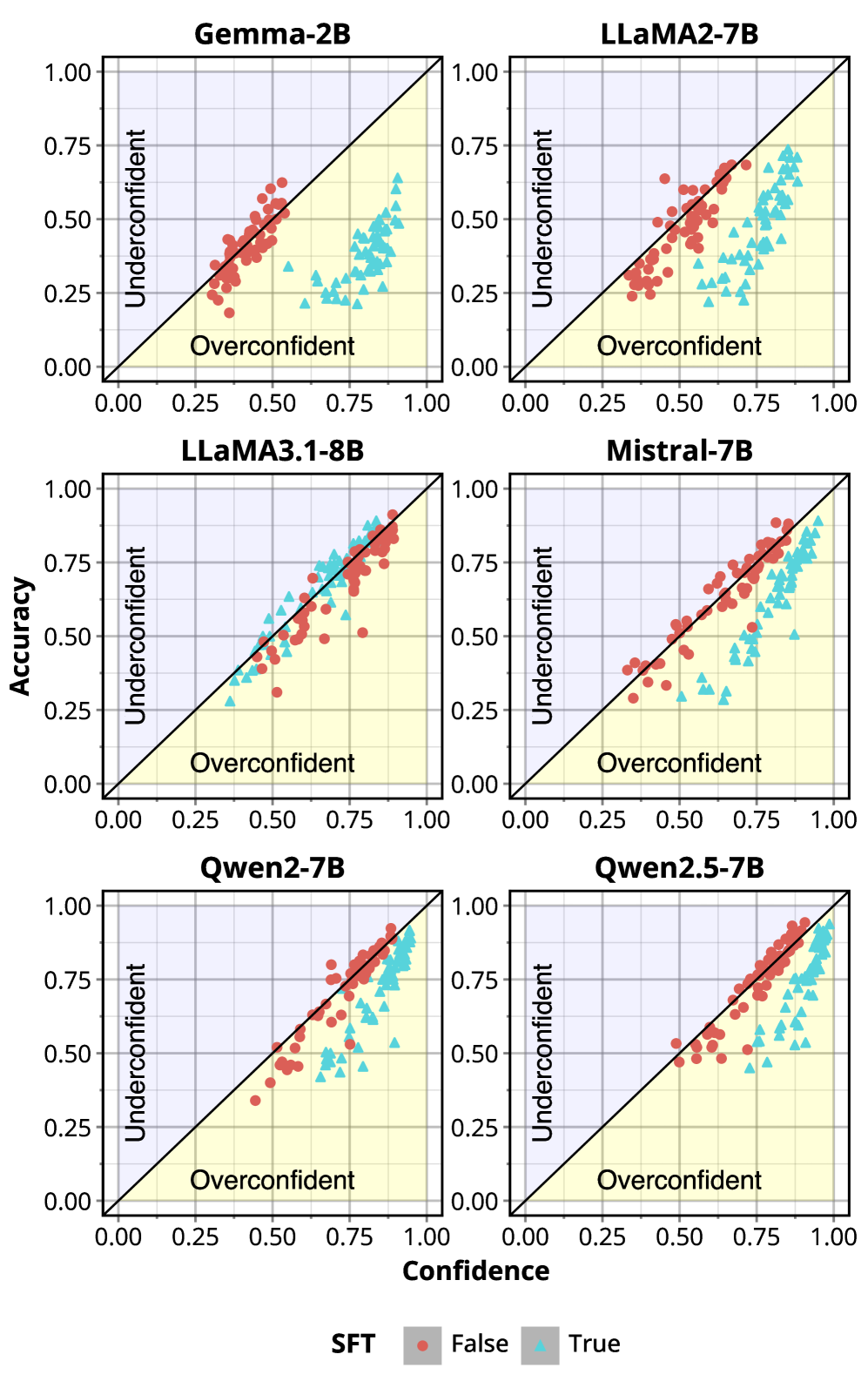
- 指令微调提升LLM交互能力,但会显著降低模型置信度校准,影响可靠性。
- 采用标签平滑正则化,维持SFT过程中LLM的校准,避免过度自信。
- 针对大词汇LLM,设计定制内核,降低标签平滑损失计算的内存占用。
📝 摘要(中文)
自然语言处理的最新进展为通过改进指令遵循能力,使微调后的大型语言模型(LLM)表现为更强大的交互式代理提供了更多机会。然而,对于这种改进如何影响可靠模型输出的置信度校准,尚未进行充分研究。本文研究了各种开源LLM,发现指令微调后每个模型的校准都显著退化。为了寻求实用的解决方案,我们转向标签平滑,它已被证明是正则化过度自信预测的有效方法,但尚未在LLM的监督微调(SFT)中得到广泛应用。我们首先深入了解为什么标签平滑足以在整个SFT过程中保持校准。然而,在某些情况下,平滑的效果会严重降低,尤其是在大型词汇LLM(LV-LLM)中。我们认为其原因是模型变得过度自信的能力,这与隐藏层大小和词汇量大小直接相关,并通过理论和实验证明了这一点。最后,我们解决了一个关于标签平滑损失设置中交叉熵损失计算的内存占用问题,设计了一个定制内核,与非平滑损失的现有解决方案相比,可以显著减少内存消耗,而不会牺牲速度或性能。
🔬 方法详解
问题定义:论文旨在解决指令微调后大型语言模型(LLM)置信度校准退化的问题。现有方法在指令微调过程中,模型容易过度自信,导致预测概率与实际准确率不匹配,影响模型输出的可靠性。尤其是在大型词汇LLM(LV-LLM)中,这个问题更加突出。
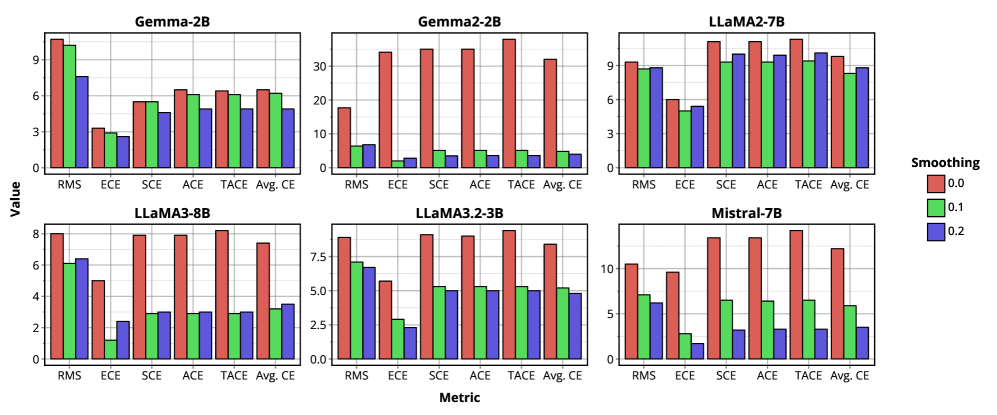
核心思路:论文的核心思路是利用标签平滑(Label Smoothing)作为一种正则化方法,在监督微调(SFT)过程中抑制模型的过度自信,从而维持或改善模型的置信度校准。标签平滑通过软化目标标签,降低模型对错误预测的惩罚,鼓励模型学习更平滑的概率分布。
技术框架:论文主要包含以下几个阶段:1) 评估指令微调对LLM校准的影响;2) 分析标签平滑在SFT中维持校准的有效性;3) 针对LV-LLM,理论分析过度自信的原因,并验证其与隐藏层大小和词汇量大小的关系;4) 设计定制内核,优化标签平滑损失计算的内存占用。
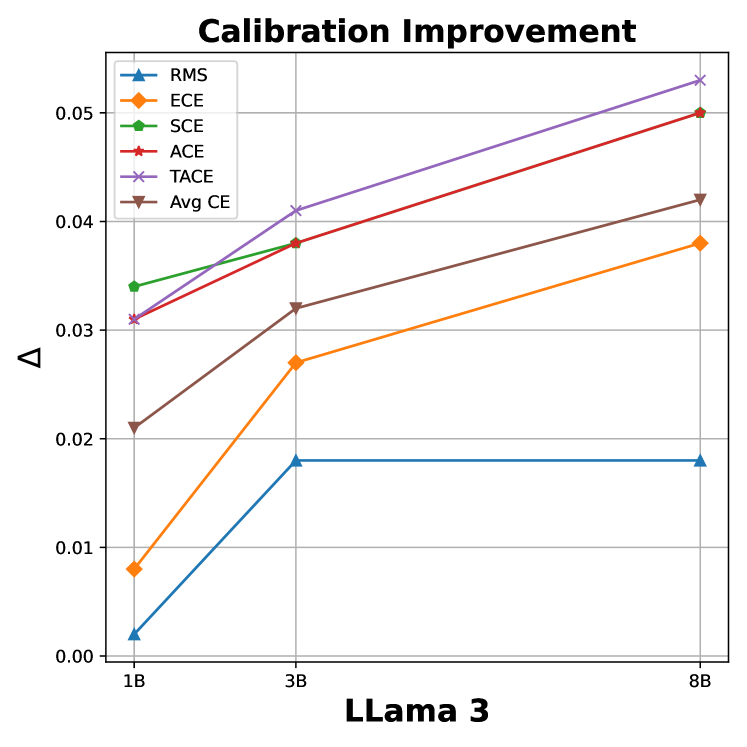
关键创新:论文的关键创新在于:1) 深入分析了指令微调对LLM校准的影响,揭示了校准退化的普遍性;2) 提出了标签平滑作为一种简单有效的校准方法,并解释了其有效性;3) 针对LV-LLM,理论分析并实验验证了过度自信与模型大小的关系;4) 设计了定制内核,解决了标签平滑损失计算的内存瓶颈。
关键设计:论文的关键设计包括:1) 标签平滑的平滑系数设置,需要根据具体任务和模型进行调整;2) 定制内核的设计,通过优化内存访问模式和计算流程,降低内存占用;3) 实验评估中,选择了多种开源LLM和数据集,以验证方法的泛化能力。
🖼️ 关键图片
📊 实验亮点
论文通过实验验证了标签平滑在维持LLM校准方面的有效性。实验结果表明,在指令微调后,使用标签平滑可以显著改善模型的置信度校准,尤其是在大型词汇LLM中。此外,定制内核的内存优化效果显著,可以在不牺牲速度和性能的前提下,大幅降低内存占用。
🎯 应用场景
该研究成果可应用于各种需要高可靠性的大型语言模型应用场景,例如智能客服、医疗诊断、金融风控等。通过校准模型置信度,可以提高模型决策的准确性和可信度,降低误判风险,并为用户提供更可靠的服务。未来的研究可以探索更有效的校准方法,并将其应用于更复杂的LLM应用中。
📄 摘要(原文)
Recent advances in natural language processing (NLP) have opened up greater opportunities to enable fine-tuned large language models (LLMs) to behave as more powerful interactive agents through improved instruction-following ability. However, understanding how this impacts confidence calibration for reliable model output has not been researched in full. In this work, we examine various open-sourced LLMs, identifying significant calibration degradation after instruction tuning in each. Seeking a practical solution, we look towards label smoothing, which has been shown as an effective method to regularize for overconfident predictions but has yet to be widely adopted in the supervised fine-tuning (SFT) of LLMs. We first provide insight as to why label smoothing is sufficient to maintain calibration throughout the SFT process. However, settings remain where the effectiveness of smoothing is severely diminished, in particular the case of large vocabulary LLMs (LV-LLMs). We posit the cause to stem from the ability to become over-confident, which has a direct relationship with the hidden size and vocabulary size, and justify this theoretically and experimentally. Finally, we address an outstanding issue regarding the memory footprint of the cross-entropy loss computation in the label smoothed loss setting, designing a customized kernel to dramatically reduce memory consumption without sacrificing speed or performance in comparison to existing solutions for non-smoothed losses.