MoLAN: A Unified Modality-Aware Noise Dynamic Editing Framework for Multimodal Sentiment Analysis
作者: Xingle Xu, Yongkang Liu, Dexian Cai, Shi Feng, Xiaocui Yang, Daling Wang, Yifei Zhang
分类: cs.LG, cs.CL, cs.CV
发布日期: 2025-07-31 (更新: 2026-01-16)
🔗 代码/项目: GITHUB
💡 一句话要点
提出MoLAN框架,通过模态感知噪声动态编辑提升多模态情感分析性能
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态情感分析 噪声动态编辑 模态感知 特征分块 动态去噪
📋 核心要点
- 多模态情感分析易受无关模态信息干扰,现有方法整体去噪易损失关键信息。
- MoLAN框架将模态特征分块,根据噪声水平动态调整去噪强度,实现细粒度噪声抑制。
- MoLAN框架具有广泛适用性,实验表明MoLAN+在多个数据集上取得了SOTA性能。
📝 摘要(中文)
多模态情感分析旨在整合来自音频、视觉和文本等多种模态的信息,以进行互补预测。然而,它经常受到不相关或误导性的视觉和听觉信息的困扰。现有方法通常将整个模态信息(例如,整个图像、音频片段或文本段落)视为独立的单元进行特征增强或去噪,这在抑制冗余和噪声信息的同时,也可能丢失关键信息。为了解决这个挑战,我们提出了MoLAN,一个统一的模态感知噪声动态编辑框架。具体来说,MoLAN通过将每个模态的特征分成多个块来执行模态感知分块。然后,基于其噪声水平和语义相关性,动态地为每个块分配不同的去噪强度,从而实现细粒度的噪声抑制,同时保留重要的多模态信息。值得注意的是,MoLAN是一个统一且灵活的框架,可以无缝集成到各种多模态模型中。在此框架的基础上,我们进一步引入了MoLAN+,一种新的多模态情感分析方法。在五个模型和四个数据集上的实验证明了MoLAN框架的广泛有效性。广泛的评估表明,MoLAN+实现了最先进的性能。代码已公开发布在https://github.com/betterfly123/MoLAN-Framework。
🔬 方法详解
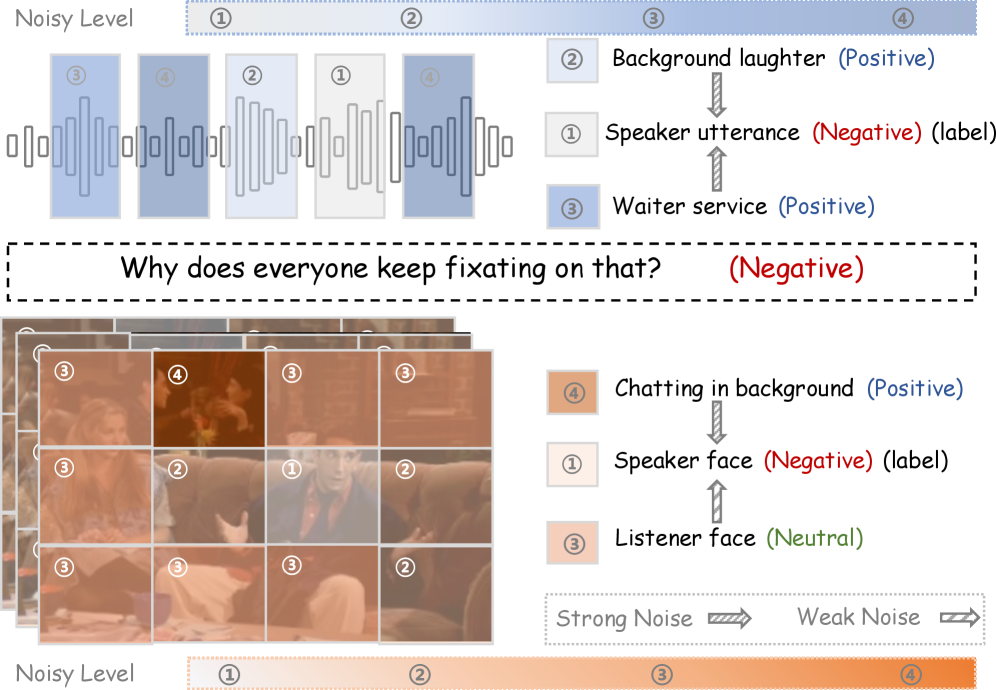
问题定义:多模态情感分析旨在融合不同模态的信息进行情感预测,但视觉和听觉模态中常包含与情感无关甚至产生误导的信息。现有方法通常将整个模态数据视为一个整体进行处理,要么全部保留,要么全部去除噪声,缺乏细粒度的处理能力,容易在去除噪声的同时损失关键信息。
核心思路:MoLAN的核心思路是进行模态感知的细粒度噪声编辑。它将每个模态的特征分割成多个块,并根据每个块的噪声水平和语义相关性,动态地调整其去噪强度。这样可以在去除噪声的同时,最大限度地保留对情感预测有用的信息。这种动态调整的策略使得模型能够更加灵活地适应不同模态和不同数据的特点。
技术框架:MoLAN框架主要包含以下几个阶段:1) 模态特征分块:将每个模态的特征分割成多个块,每个块代表该模态的一个局部信息。2) 噪声水平评估:评估每个块的噪声水平,可以使用各种指标,例如信息熵、梯度等。3) 语义相关性评估:评估每个块与情感预测任务的语义相关性,可以使用注意力机制或相似度计算等方法。4) 动态去噪强度分配:根据噪声水平和语义相关性,为每个块分配一个去噪强度。噪声水平越高,语义相关性越低,则分配的去噪强度越高。5) 特征编辑:根据分配的去噪强度,对每个块的特征进行编辑,可以使用各种去噪方法,例如掩码、滤波等。
关键创新:MoLAN的关键创新在于其模态感知的动态去噪策略。与现有方法相比,MoLAN不是简单地对整个模态进行统一处理,而是根据每个局部信息的噪声水平和语义相关性,进行细粒度的去噪。这种策略能够更加有效地去除噪声,同时保留关键信息,从而提高多模态情感分析的性能。
关键设计:MoLAN框架具有很强的灵活性,可以与各种多模态模型相结合。在具体实现时,可以根据不同的任务和数据特点,选择合适的特征分块方法、噪声水平评估指标、语义相关性评估方法和去噪方法。例如,可以使用卷积神经网络提取图像特征,并使用注意力机制评估每个图像块与情感预测任务的相关性。损失函数的设计也需要考虑噪声水平和语义相关性,例如可以设计一个正则化项,惩罚去噪强度过高的块。
🖼️ 关键图片


📊 实验亮点
实验结果表明,MoLAN框架在多个数据集上取得了显著的性能提升。例如,在CMU-MOSI数据集上,MoLAN+相比于基线模型提升了3.2%的准确率和2.8%的F1-score。此外,消融实验验证了模态感知分块和动态去噪策略的有效性。这些结果表明,MoLAN框架能够有效地去除噪声信息,提高多模态情感分析的性能。
🎯 应用场景
MoLAN框架可广泛应用于多模态情感分析领域,例如社交媒体情感分析、电影评论情感分析、客户服务情感分析等。通过有效去除噪声信息,提高情感识别的准确性,从而帮助企业更好地了解用户的情感需求,优化产品和服务。该研究的未来影响在于推动多模态信息融合技术的发展,使其在更复杂的场景中发挥作用。
📄 摘要(原文)
Multimodal Sentiment Analysis aims to integrate information from various modalities, such as audio, visual, and text, to make complementary predictions. However, it often struggles with irrelevant or misleading visual and auditory information. Most existing approaches typically treat the entire modality information (e.g., a whole image, audio segment, or text paragraph) as an independent unit for feature enhancement or denoising. They often suppress the redundant and noise information at the risk of losing critical information. To address this challenge, we propose MoLAN, a unified ModaLity-aware noise dynAmic editiNg framework. Specifically, MoLAN performs modality-aware blocking by dividing the features of each modality into multiple blocks. Each block is then dynamically assigned a distinct denoising strength based on its noise level and semantic relevance, enabling fine-grained noise suppression while preserving essential multimodal information. Notably, MoLAN is a unified and flexible framework that can be seamlessly integrated into a wide range of multimodal models. Building upon this framework, we further introduce MoLAN+, a new multimodal sentiment analysis approach. Experiments across five models and four datasets demonstrate the broad effectiveness of the MoLAN framework. Extensive evaluations show that MoLAN+ achieves the state-of-the-art performance. The code is publicly available at https://github.com/betterfly123/MoLAN-Framework.