One-Step Flow Policy Mirror Descent
作者: Tianyi Chen, Haitong Ma, Na Li, Kai Wang, Bo Dai
分类: cs.LG
发布日期: 2025-07-31 (更新: 2025-10-16)
💡 一句话要点
提出FPMD算法,实现Flow Policy单步采样,加速在线强化学习推理。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: Flow Matching 扩散策略 在线强化学习 单步采样 策略优化 Mirror Descent 机器人控制
📋 核心要点
- 扩散策略推理依赖迭代采样,速度慢,限制了在线强化学习的响应性。
- FPMD算法利用分布方差与单步采样误差的理论联系,实现flow policy的单步采样。
- 实验表明,FPMD在性能上与扩散策略相当,但推理计算成本显著降低。
📝 摘要(中文)
扩散策略在在线强化学习(RL)中因其强大的表达能力而取得了巨大成功。然而,扩散策略模型的推理依赖于缓慢的迭代采样过程,这限制了它们的响应速度。为了克服这个限制,我们提出了Flow Policy Mirror Descent(FPMD),一种在线RL算法,可以在flow policy推理期间实现单步采样。我们的方法利用了直线插值flow matching模型中分布方差与单步采样离散化误差之间的理论联系,并且不需要额外的蒸馏或一致性训练。我们分别提出了基于rectified flow policy和MeanFlow policy的两种算法变体。在MuJoCo和视觉DeepMind Control Suite基准上的大量经验评估表明,我们的算法表现出与扩散策略基线相当的强大性能,同时在推理期间所需的计算成本降低了几个数量级。
🔬 方法详解
问题定义:扩散策略在在线强化学习中表现出色,但其推理过程依赖于耗时的迭代采样,这严重限制了策略的响应速度,使其难以应用于需要快速决策的场景。现有方法通常需要额外的蒸馏或一致性训练来加速推理,增加了训练的复杂性。
核心思路:该论文的核心思路是利用Flow Matching模型中分布方差与单步采样离散化误差之间的理论联系,直接通过单步采样实现策略推理。通过控制Flow Matching模型的方差,可以减少单步采样带来的误差,从而在保证性能的同时显著加速推理过程。
技术框架:FPMD算法的整体框架包括以下几个主要步骤:1) 使用Flow Matching模型学习策略;2) 利用分布方差与单步采样误差的理论关系,优化Flow Matching模型;3) 在线强化学习过程中,使用单步采样进行策略推理和更新。该框架包含两个变体:基于Rectified Flow Policy和基于MeanFlow Policy。
关键创新:该论文的关键创新在于建立了Flow Matching模型中分布方差与单步采样误差之间的理论联系,并基于此提出了FPMD算法,实现了flow policy的单步采样推理。与现有方法相比,FPMD无需额外的蒸馏或一致性训练,简化了训练流程,同时显著降低了推理计算成本。
关键设计:FPMD算法的关键设计包括:1) 使用Mirror Descent方法进行策略更新;2) 基于Rectified Flow或MeanFlow构建Flow Matching模型;3) 通过控制Flow Matching模型的方差来优化单步采样性能。具体的损失函数设计和网络结构选择取决于所使用的Flow Matching模型变体(Rectified Flow或MeanFlow)。
🖼️ 关键图片


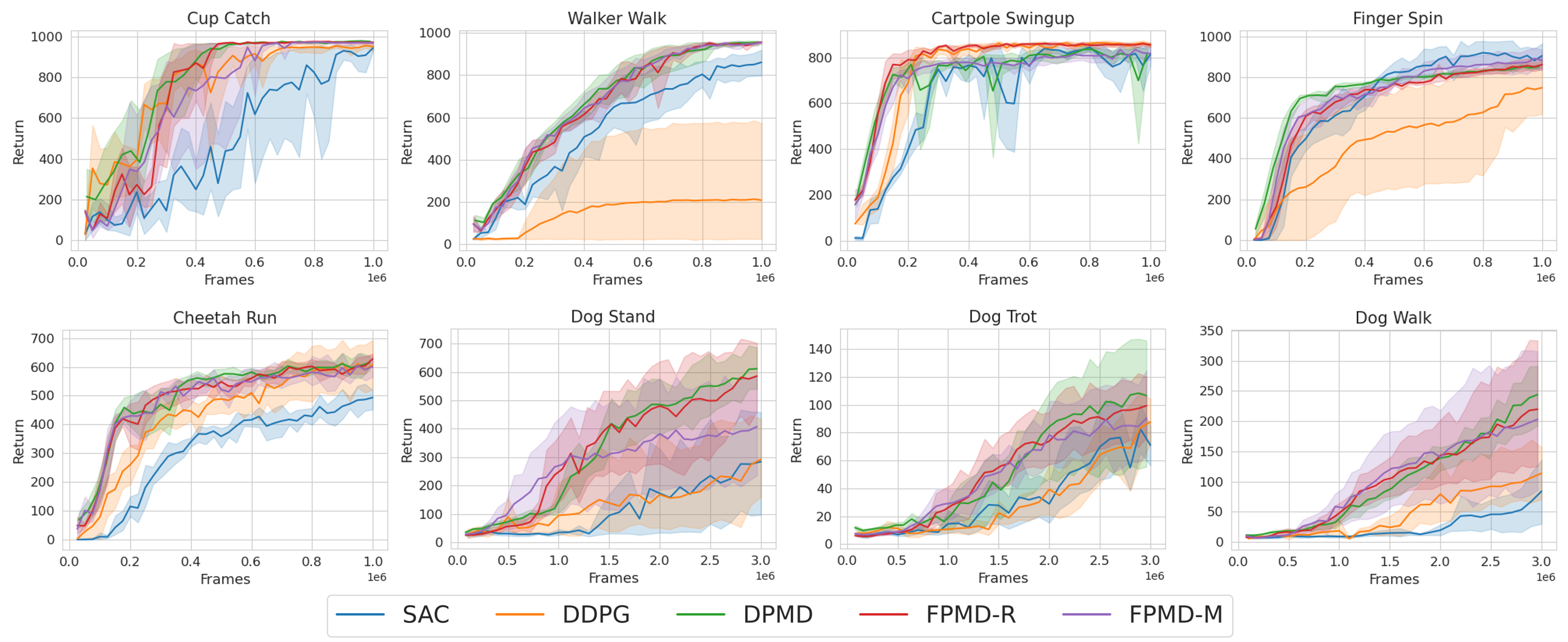
📊 实验亮点
在MuJoCo和视觉DeepMind Control Suite基准测试中,FPMD算法表现出与扩散策略基线相当的性能,同时在推理过程中所需的计算成本降低了几个数量级。这表明FPMD算法在保证性能的同时,显著提高了策略推理的效率,使其更适用于在线强化学习。
🎯 应用场景
该研究成果可广泛应用于需要快速响应的在线强化学习场景,例如机器人控制、自动驾驶、游戏AI等。通过降低策略推理的计算成本,可以使强化学习算法更易于部署在资源受限的设备上,并提高系统的实时性。未来,该方法有望扩展到更复杂的任务和环境,推动强化学习在实际应用中的发展。
📄 摘要(原文)
Diffusion policies have achieved great success in online reinforcement learning (RL) due to their strong expressive capacity. However, the inference of diffusion policy models relies on a slow iterative sampling process, which limits their responsiveness. To overcome this limitation, we propose Flow Policy Mirror Descent (FPMD), an online RL algorithm that enables 1-step sampling during flow policy inference. Our approach exploits a theoretical connection between the distribution variance and the discretization error of single-step sampling in straight interpolation flow matching models, and requires no extra distillation or consistency training. We present two algorithm variants based on rectified flow policy and MeanFlow policy, respectively. Extensive empirical evaluations on MuJoCo and visual DeepMind Control Suite benchmarks demonstrate that our algorithms show strong performance comparable to diffusion policy baselines while requiring orders of magnitude less computational cost during inference.