Merging Memory and Space: A State Space Neural Operator
作者: Nodens Koren, Samuel Lanthaler
分类: cs.LG
发布日期: 2025-07-31 (更新: 2025-09-28)
💡 一句话要点
提出状态空间神经算子(SS-NO)用于高效学习时变偏微分方程的解算子。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱八:物理动画 (Physics-based Animation)
关键词: 神经算子 状态空间模型 偏微分方程 时空建模 自适应阻尼
📋 核心要点
- 现有神经算子在处理时变偏微分方程时,往往面临参数量大、难以捕捉长程依赖等问题。
- SS-NO通过引入自适应阻尼和可学习频率调制,将结构化状态空间模型扩展到时空建模,从而高效捕捉长程依赖。
- 实验表明,SS-NO在多个PDE基准上取得了领先性能,且参数量显著低于现有方法,验证了其有效性。
📝 摘要(中文)
本文提出了一种紧凑的架构——状态空间神经算子(SS-NO),用于学习时变偏微分方程(PDEs)的解算子。该方法将结构化状态空间模型(SSMs)扩展到联合时空建模,并引入了两个关键机制:自适应阻尼,通过定位感受野来稳定学习;以及可学习的频率调制,从而实现数据驱动的频谱选择。这些组件提供了一个统一的框架,以参数高效的方式捕获长程依赖关系。理论上,我们建立了SSMs和神经算子之间的联系,证明了具有全视野卷积架构的通用性定理。在经验上,SS-NO在各种PDE基准测试中实现了最先进的性能,包括1D Burgers'和Kuramoto-Sivashinsky方程,以及2D Navier-Stokes和可压缩Euler流,同时使用的参数明显少于竞争方法。SS-NO的分解变体进一步证明了在具有挑战性的2D问题上的可扩展性能。我们的结果突出了阻尼和频率学习在算子建模中的有效性,同时表明轻量级分解为高效的大规模PDE学习提供了一条补充途径。
🔬 方法详解
问题定义:论文旨在解决时变偏微分方程(PDEs)解算子的学习问题。现有神经算子方法,如DeepONet和FNO,在处理复杂PDEs时,通常需要大量的参数才能捕捉到时空中的长程依赖关系,计算成本高昂,泛化能力受限。因此,如何设计一种参数高效且能有效捕捉长程依赖的神经算子是亟待解决的问题。
核心思路:论文的核心思路是将结构化状态空间模型(SSMs)与神经算子相结合,利用SSMs在序列建模方面的优势来捕捉PDE解的时序演化,同时通过引入自适应阻尼和可学习频率调制机制,增强模型对时空信息的表达能力。这种设计旨在实现参数效率和性能之间的平衡。
技术框架:SS-NO的整体架构基于状态空间模型,将输入数据映射到高维状态空间,然后通过线性变换和非线性激活函数进行状态更新,最终将状态空间的信息映射回输出空间。关键模块包括:1) 输入嵌入层,将输入数据映射到状态空间;2) SSM层,包含状态转移矩阵、输入矩阵、输出矩阵和阻尼参数;3) 输出映射层,将状态空间的信息映射回输出空间。整个流程可以看作是一个encoder-decoder结构,encoder将输入映射到状态空间,decoder从状态空间重建输出。
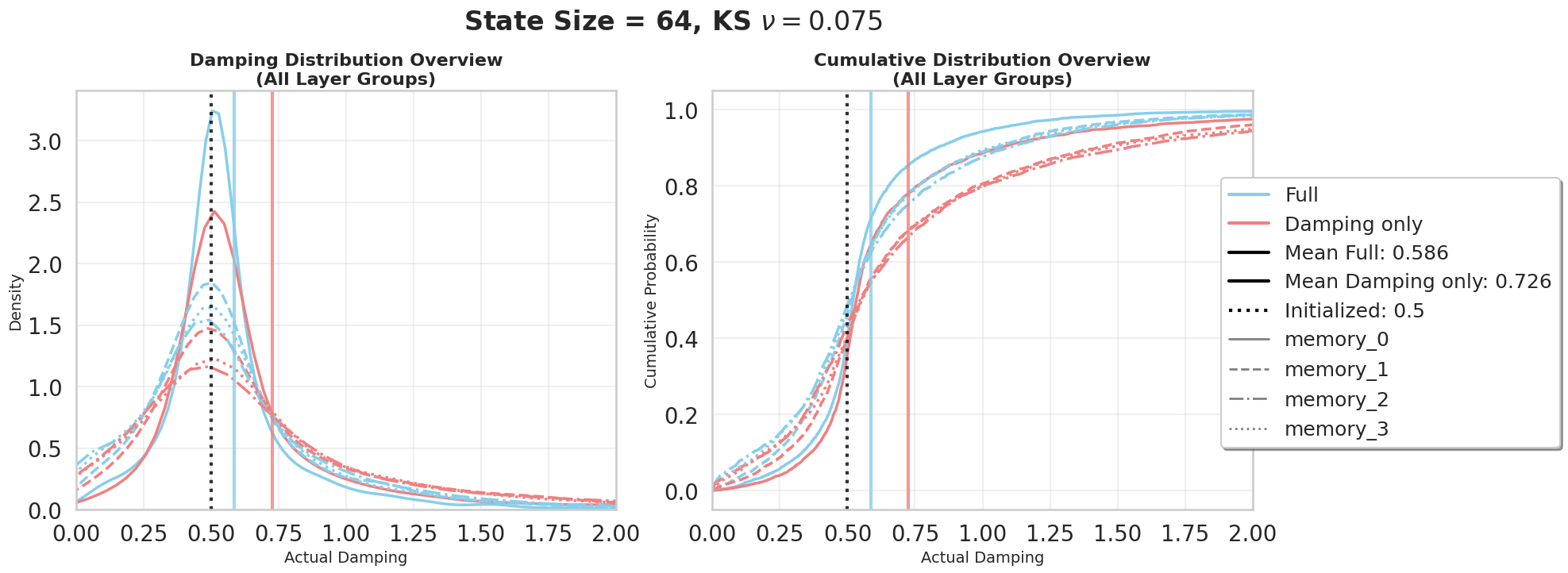
关键创新:SS-NO的关键创新在于:1) 将SSMs扩展到时空建模,使其能够同时处理空间和时间维度上的信息;2) 引入自适应阻尼机制,通过局部化感受野来稳定学习,并提高模型的泛化能力;3) 引入可学习的频率调制机制,允许模型根据数据自适应地选择重要的频谱分量,从而提高模型的表达能力。这些创新使得SS-NO能够以更少的参数捕捉到PDE解的长程依赖关系。
关键设计:自适应阻尼参数通过一个神经网络学习得到,该网络以输入数据为条件,动态调整阻尼强度。可学习频率调制通过在频域上对状态转移矩阵进行调制来实现,调制参数也是通过一个神经网络学习得到。损失函数通常采用均方误差(MSE)或其变体,用于衡量模型预测结果与真实解之间的差异。网络结构方面,可以使用卷积神经网络(CNN)或Transformer等作为输入和输出映射层。
🖼️ 关键图片


📊 实验亮点
SS-NO在1D Burgers'、Kuramoto-Sivashinsky方程以及2D Navier-Stokes和可压缩Euler流等多个PDE基准测试中取得了state-of-the-art的性能,同时使用的参数量显著少于其他神经算子方法。例如,在某些任务上,SS-NO的参数量比FNO减少了几个数量级,但性能却与之相当甚至更好。此外,SS-NO的分解变体在2D问题上展现了良好的可扩展性。
🎯 应用场景
SS-NO在科学计算领域具有广泛的应用前景,例如流体动力学、气候模拟、材料科学等。它可以用于加速PDE求解过程,提高计算效率,并为复杂物理系统的建模和预测提供新的工具。此外,该方法还可以应用于其他时空数据建模任务,例如视频预测、交通流量预测等。
📄 摘要(原文)
We propose the State Space Neural Operator (SS-NO), a compact architecture for learning solution operators of time-dependent partial differential equations (PDEs). Our formulation extends structured state space models (SSMs) to joint spatiotemporal modeling, introducing two key mechanisms: adaptive damping, which stabilizes learning by localizing receptive fields, and learnable frequency modulation, which enables data-driven spectral selection. These components provide a unified framework for capturing long-range dependencies with parameter efficiency. Theoretically, we establish connections between SSMs and neural operators, proving a universality theorem for convolutional architectures with full field-of-view. Empirically, SS-NO achieves state-of-the-art performance across diverse PDE benchmarks-including 1D Burgers' and Kuramoto-Sivashinsky equations, and 2D Navier-Stokes and compressible Euler flows-while using significantly fewer parameters than competing approaches. A factorized variant of SS-NO further demonstrates scalable performance on challenging 2D problems. Our results highlight the effectiveness of damping and frequency learning in operator modeling, while showing that lightweight factorization provides a complementary path toward efficient large-scale PDE learning.