Deep Reinforcement Learning in Factor Investment
作者: Junlin Liu
分类: cs.CE, cs.LG
发布日期: 2025-07-30
💡 一句话要点
提出CAFPO,利用深度强化学习解决低频因子投资组合构建问题
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 深度强化学习 因子投资 投资组合优化 自编码器 表征学习
📋 核心要点
- 传统低频因子投资组合构建面临高维、不平衡状态空间的挑战,难以直接应用深度强化学习。
- CAFPO通过条件自编码器学习股票回报的潜在因子表示,降低状态空间维度,并融入公司特征信息。
- 实验表明,CAFPO在美股市场表现优于多种基线方法,实现了更高的复合回报和夏普比率。
📝 摘要(中文)
深度强化学习在交易执行方面展现出潜力,但其在低频因子投资组合构建中的应用仍未被充分探索。一个关键障碍是由于股票进入和退出可投资范围而产生的高维、不平衡状态空间。本文提出了一种条件自编码因子投资组合优化(CAFPO)方法,该方法将股票层面的回报压缩成一小组潜在因子,这些因子以94个公司特定特征为条件。这些因子被输入到使用PPO和DDPG实现的DRL代理中,以生成连续的多空权重。在美国20年(2000-2020)的股票数据上,CAFPO优于等权重、价值权重、马科维茨、原始DRL和Fama-French驱动的DRL,实现了24.6%的复合回报和0.94的样本外夏普比率。SHAP分析进一步揭示了经济上直观的因子归因。结果表明,因子感知的表征学习可以使DRL在机构低换手率投资组合管理中具有实用性。
🔬 方法详解
问题定义:论文旨在解决低频因子投资组合构建问题,即如何利用深度强化学习自动生成投资组合权重,以获得更高的收益。现有方法,如直接使用股票价格或因子作为状态输入,会导致状态空间维度过高,难以训练有效的DRL代理;同时,股票池的动态变化(股票的加入和退出)进一步加剧了状态空间的不平衡性。
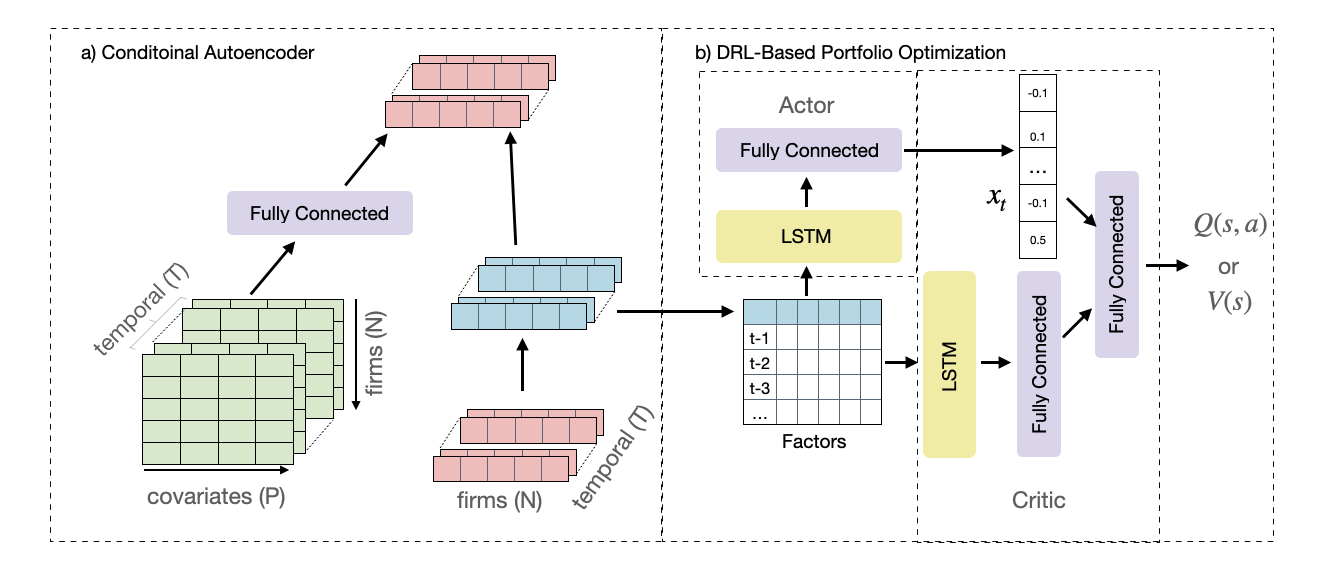
核心思路:论文的核心思路是利用条件自编码器(Conditional Autoencoder)学习股票回报的低维潜在因子表示。通过将高维的股票回报压缩到低维的因子空间,并以公司特征为条件,可以有效地降低状态空间的维度,并捕捉股票之间的相关性。然后,将这些因子作为DRL代理的状态输入,从而实现更有效的投资组合优化。
技术框架:CAFPO框架主要包含两个模块:条件自编码器(CAE)和深度强化学习代理(DRL Agent)。CAE负责将股票回报压缩为潜在因子,并以公司特征为条件。DRL Agent接收这些因子作为状态输入,并输出投资组合权重。整个流程如下:首先,使用历史数据训练CAE,学习股票回报的潜在因子表示。然后,使用训练好的CAE将当前时刻的股票回报压缩为因子表示,并将其作为DRL Agent的状态输入。DRL Agent根据当前状态,输出投资组合权重。最后,根据投资组合权重和股票回报,计算投资组合的收益,并将其作为DRL Agent的奖励信号,用于更新DRL Agent的策略。
关键创新:论文的关键创新在于提出了条件自编码因子投资组合优化(CAFPO)方法。与传统的DRL方法相比,CAFPO通过引入条件自编码器,有效地降低了状态空间的维度,并融入了公司特征信息。与传统的因子投资方法相比,CAFPO可以自动学习因子表示,并利用DRL优化投资组合权重,从而实现更高的收益。
关键设计:CAE使用多层感知机(MLP)作为编码器和解码器,损失函数包括重构损失和正则化项。DRL Agent使用PPO和DDPG两种算法实现,奖励函数为投资组合的收益。公司特征包括94个财务指标,用于作为CAE的条件输入。实验中,使用了20年的美国股票数据(2000-2020)进行训练和测试。
🖼️ 关键图片
📊 实验亮点
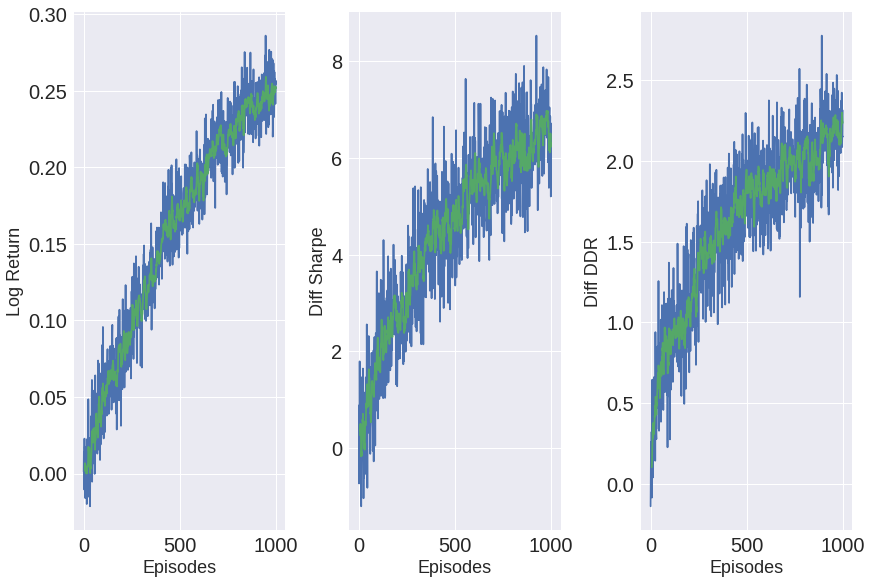
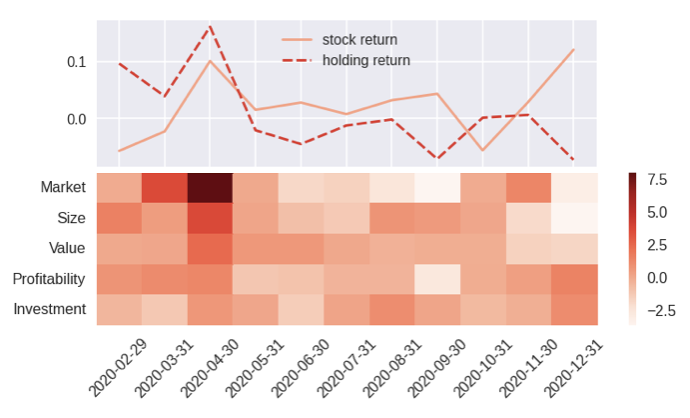
实验结果表明,CAFPO在2000-2020年的美国股票数据上,优于等权重、价值权重、马科维茨、原始DRL和Fama-French驱动的DRL等基线方法,实现了24.6%的复合回报和0.94的样本外夏普比率。SHAP分析进一步验证了因子归因的经济直觉。
🎯 应用场景
该研究成果可应用于机构投资者的低换手率投资组合管理。通过自动学习因子表示和优化投资组合权重,可以提高投资组合的收益和风险调整后收益。此外,该方法还可以应用于其他金融领域,如风险管理、资产配置等。
📄 摘要(原文)
Deep reinforcement learning has shown promise in trade execution, yet its use in low-frequency factor portfolio construction remains under-explored. A key obstacle is the high-dimensional, unbalanced state space created by stocks that enter and exit the investable universe. We introduce Conditional Auto-encoded Factor-based Portfolio Optimisation (CAFPO), which compresses stock-level returns into a small set of latent factors conditioned on 94 firm-specific characteristics. The factors feed a DRL agent implemented with both PPO and DDPG to generate continuous long-short weights. On 20 years of U.S. equity data (2000--2020), CAFPO outperforms equal-weight, value-weight, Markowitz, vanilla DRL, and Fama--French-driven DRL, delivering a 24.6\% compound return and a Sharpe ratio of 0.94 out of sample. SHAP analysis further reveals economically intuitive factor attributions. Our results demonstrate that factor-aware representation learning can make DRL practical for institutional, low-turnover portfolio management.