KLLM: Fast LLM Inference with K-Means Quantization
作者: Xueying Wu, Baijun Zhou, Zhihui Gao, Yuzhe Fu, Qilin Zheng, Yintao He, Hai Li
分类: cs.LG, cs.AR
发布日期: 2025-07-30 (更新: 2025-09-09)
💡 一句话要点
KLLM:基于K-Means量化的快速LLM推理加速器
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 LLM推理 量化 K-Means量化 加速器 硬件加速 异常值检测
📋 核心要点
- 现有LLM推理面临内存和计算瓶颈,低精度量化虽能缓解,但均匀量化精度损失大,非均匀量化(如K-Means)难以高效执行。
- KLLM提出一种基于K-Means量化的LLM推理加速器,通过索引计算避免反量化,并集成轻量级在线异常值检测引擎Orizuru。
- KLLM采用索引计算高效执行K-Means量化数据的矩阵乘法和非线性操作,并使用Orizuru进行在线异常值检测,提升推理效率。
📝 摘要(中文)
大语言模型(LLM)推理因其巨大的内存和计算需求而面临严峻挑战。权重和激活量化(WAQ)通过减少内存占用和算术复杂度提供了一种有前景的解决方案。传统的WAQ设计依赖于硬件友好的均匀整数量化,但通常在低精度下会遭受显著的模型性能下降。相比之下,K-Means量化作为一种非均匀技术,通过与LLM中权重和激活的类高斯分布对齐,实现了更高的精度。然而,两个关键挑战阻碍了基于K-Means的WAQ设计在LLM推理中的高效部署:(1)K-Means量化数据的非均匀结构阻碍了在低精度计算单元上的直接执行,需要在推理期间进行反量化和浮点矩阵乘法(MatMul)。(2)激活异常值阻碍了有效的低精度量化。用于异常值检测的离线阈值方法会显著降低模型性能,而现有的在线检测技术会引入显著的运行时开销。为了解决上述挑战并充分释放基于K-Means的WAQ在LLM推理中的潜力,本文提出KLLM,一种LLM推理加速器,用于高效执行K-Means量化的权重和激活。KLLM采用基于索引的计算方案,用于高效执行K-Means量化数据上的MatMul和非线性运算,从而避免了大部分反量化和全精度计算。此外,KLLM还包含一个轻量级的异常值检测引擎Orizuru,可以在在线推理期间高效地识别激活数据流中前k个最大和最小的元素。
🔬 方法详解
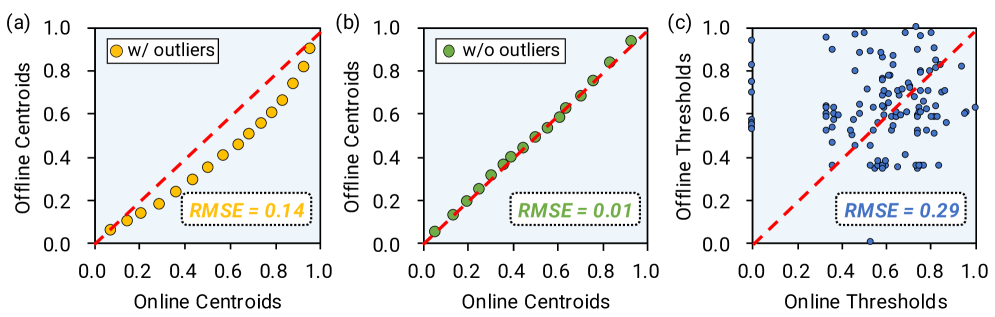
问题定义:论文旨在解决大语言模型(LLM)推理过程中,使用K-Means量化后,由于其非均匀特性导致的计算效率低下问题。现有方法要么采用均匀量化,精度损失大;要么采用K-Means量化,但需要反量化后进行浮点运算,计算开销大。此外,激活值中的异常值也会影响量化效果,离线检测影响模型性能,在线检测开销大。
核心思路:论文的核心思路是设计一种专门的加速器架构,能够直接在K-Means量化后的数据上进行计算,避免反量化过程。同时,设计一个轻量级的在线异常值检测引擎,实时处理激活值中的异常值,从而提高量化效果和推理速度。这样设计的目的是充分利用K-Means量化带来的精度优势,同时克服其计算效率上的劣势。
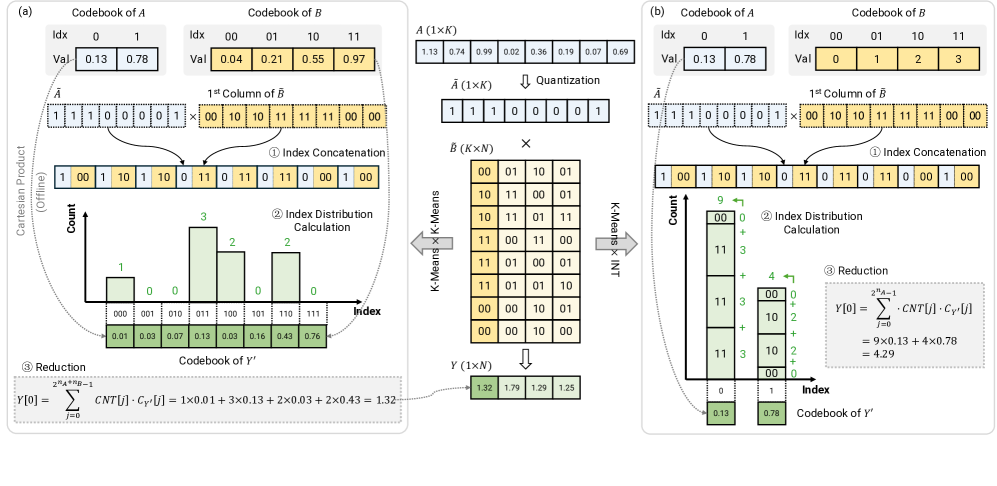
技术框架:KLLM加速器的整体框架包含以下几个主要模块:1) 存储模块:用于存储K-Means量化后的权重和激活值,以及码本。2) 基于索引的计算模块:该模块是KLLM的核心,它根据激活值的索引,直接从码本中查找对应的权重值,进行矩阵乘法等运算,避免了反量化过程。3) Orizuru异常值检测引擎:该引擎负责在线检测激活值中的异常值,并进行相应的处理,以提高量化效果。4) 控制模块:负责协调各个模块的工作,控制数据流的走向。
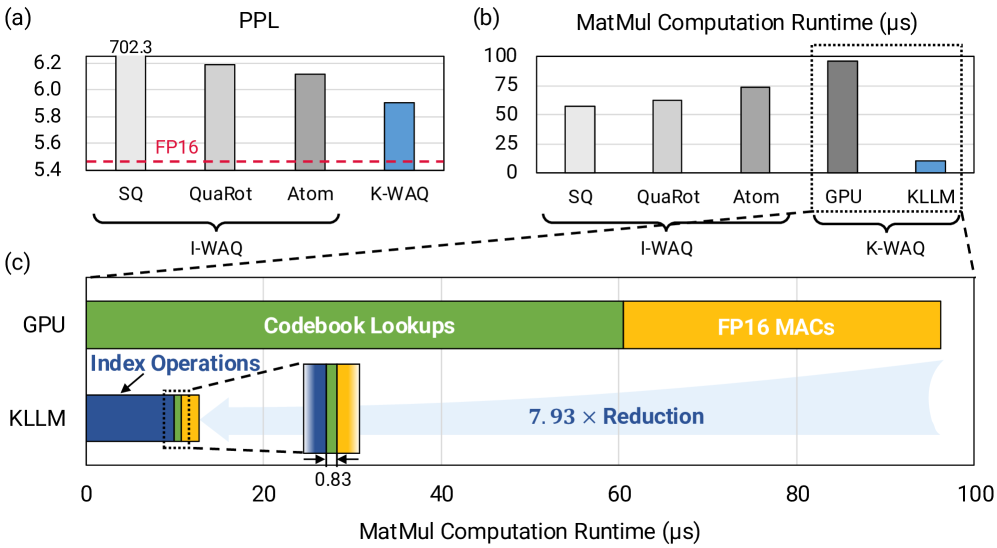
关键创新:KLLM最重要的技术创新点在于其基于索引的计算方案。传统的K-Means量化需要先将量化后的数据反量化回浮点数,然后再进行计算。而KLLM通过索引直接在码本中查找对应的浮点数值进行计算,避免了反量化过程,大大提高了计算效率。此外,Orizuru异常值检测引擎也具有轻量级和在线处理的特点,能够在不引入过多开销的情况下提高量化效果。
关键设计:KLLM的关键设计包括:1) 码本的设计:码本的大小和结构会影响量化精度和计算效率,需要根据具体的模型和硬件平台进行优化。2) 索引计算的实现:如何高效地根据索引查找码本中的值,是提高计算效率的关键。3) Orizuru异常值检测引擎的算法:需要选择合适的算法,在保证检测精度的同时,尽量减少计算开销。4) 数据流的优化:如何合理地安排数据在各个模块之间的流动,以减少访存开销,也是一个重要的设计考虑。
🖼️ 关键图片
📊 实验亮点
论文提出的KLLM加速器通过索引计算和在线异常值检测,显著提高了K-Means量化LLM的推理效率。具体性能数据未知,但核心在于避免了反量化和全精度计算,并降低了异常值检测的开销,从而在保证模型精度的前提下,提升了推理速度。
🎯 应用场景
KLLM加速器可应用于各种需要高性能LLM推理的场景,如边缘设备上的自然语言处理、智能助手、对话系统等。通过提高推理速度和降低功耗,KLLM能够使LLM在资源受限的环境中得到更广泛的应用,并推动人工智能技术在移动设备和嵌入式系统中的发展。
📄 摘要(原文)
Large language model (LLM) inference poses significant challenges due to its intensive memory and computation demands. Weight and activation quantization (WAQ) offers a promising solution by reducing both memory footprint and arithmetic complexity. Traditional WAQ designs rely on uniform integer quantization for hardware efficiency, but often suffer from significant model performance degradation at low precision. In contrast, K-Means quantization, a non-uniform technique, achieves higher accuracy by aligning with the Gaussian-like distributions of weights and activations in LLMs. However, two key challenges prevent the efficient deployment of K-Means-based WAQ designs for LLM inference: (1) The non-uniform structure of K-Means-quantized data precludes direct execution on low-precision compute units, necessitating dequantization and floating-point matrix multiplications (MatMuls) during inference. (2) Activation outliers hinder effective low-precision quantization. Offline thresholding methods for outlier detection degrade model performance substantially, while existing online detection techniques introduce significant runtime overhead. To address the aforementioned challenges and fully unleash the potential of K-Means-based WAQ for LLM inference, in this paper, we propose KLLM, an LLM inference accelerator for efficient execution with K-Means-quantized weights and activations. KLLM features an index-based computation scheme for efficient execution of MatMuls and nonlinear operations on K-Means-quantized data, which avoids most of the dequantization and full-precision computations. Moreover, KLLM incorporates a lightweight outlier detection engine, Orizuru, that efficiently identifies the top-$k$ largest and smallest elements in the activation data stream during online inference.