Stop Evaluating AI with Human Tests, Develop Principled, AI-specific Tests instead
作者: Tom Sühr, Florian E. Dorner, Olawale Salaudeen, Augustin Kelava, Samira Samadi
分类: cs.LG, cs.AI
发布日期: 2025-07-30
💡 一句话要点
呼吁停止使用人类测试评估AI,转而开发AI专属的、基于原则的测试方法
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: AI评估 大型语言模型 心理测量学 基准测试 类人智能
📋 核心要点
- 现有AI评估方法主要依赖于针对人类设计的测试,这可能导致对AI能力的错误解读和不准确评估。
- 论文提出应开发专门针对AI系统的评估框架,这些框架应基于明确的原则,并充分考虑AI的独特性质。
- 该研究强调了理论基础和经验验证的重要性,以确保AI评估的有效性和可靠性,避免对AI能力进行不合理的推断。
📝 摘要(中文)
大型语言模型(LLMs)在各种标准化测试中取得了显著成果,这些测试最初旨在评估人类的认知和心理特征,如智力和个性。虽然这些结果通常被解释为LLMs具有类人特征的有力证据,但本文认为这种解释构成了一种本体论错误。人类心理和教育测试是理论驱动的测量工具,针对特定的人群进行校准。在没有经验验证的情况下将这些测试应用于非人类主体,可能会错误地描述所测量的内容。此外,一种日益增长的趋势是将AI在基准测试中的表现视为对诸如“智力”等特征的测量,尽管存在有效性、数据污染、文化偏见以及对表面提示变化的敏感性等已知问题。我们认为,将基准测试性能解释为对类人特征的测量,缺乏足够的理论和经验依据。因此,我们提出:停止使用人类测试评估AI,转而开发AI专属的、基于原则的测试方法。我们呼吁开发针对AI系统量身定制的、基于原则的AI专属评估框架。这些框架可以建立在现有的心理测量学测试构建和验证框架之上,或者完全从头开始创建,以适应AI的独特环境。
🔬 方法详解
问题定义:当前AI评估领域过度依赖为人类设计的心理和教育测试,这些测试在应用于AI时,由于缺乏理论基础和经验验证,可能导致对AI能力的误判。现有方法未能充分考虑AI与人类在认知结构和学习方式上的根本差异,导致评估结果缺乏有效性和可靠性。此外,将AI在基准测试中的表现直接解读为类人智能,忽视了数据污染、文化偏见等潜在问题。
核心思路:论文的核心在于倡导停止使用人类测试来评估AI,并呼吁开发专门为AI设计的、基于原则的评估框架。这种框架应充分考虑AI的独特性质,并借鉴心理测量学的严谨方法,确保评估结果的有效性和可靠性。核心思路是建立一套能够真正反映AI能力的评估体系,避免将AI与人类进行不恰当的比较。
技术框架:论文并未提出一个具体的AI评估框架,而是提供了一个概念性的指导方向。建议的框架构建思路包括:1) 借鉴现有心理测量学测试的构建和验证方法;2) 从零开始创建全新的评估体系,以适应AI的独特环境。框架应包含明确的评估指标、标准化的测试流程,以及严格的验证方法,以确保评估结果的客观性和可重复性。
关键创新:该论文的关键创新在于其批判性地指出了当前AI评估方法的局限性,并提出了开发AI专属评估框架的必要性。与以往关注AI在人类测试中表现的研究不同,该论文强调了评估方法本身的合理性和有效性。这种转变有助于推动AI评估领域朝着更加科学和严谨的方向发展。
关键设计:由于论文主要关注评估理念的转变,并未涉及具体的算法或模型设计。然而,在构建AI专属评估框架时,需要考虑以下关键设计:1) 评估指标的选择应与AI系统的具体任务和目标相符;2) 测试数据的设计应具有代表性和多样性,以避免数据偏差;3) 评估流程应标准化,以确保评估结果的可重复性;4) 评估结果的解释应谨慎,避免过度解读和不合理的推断。
🖼️ 关键图片
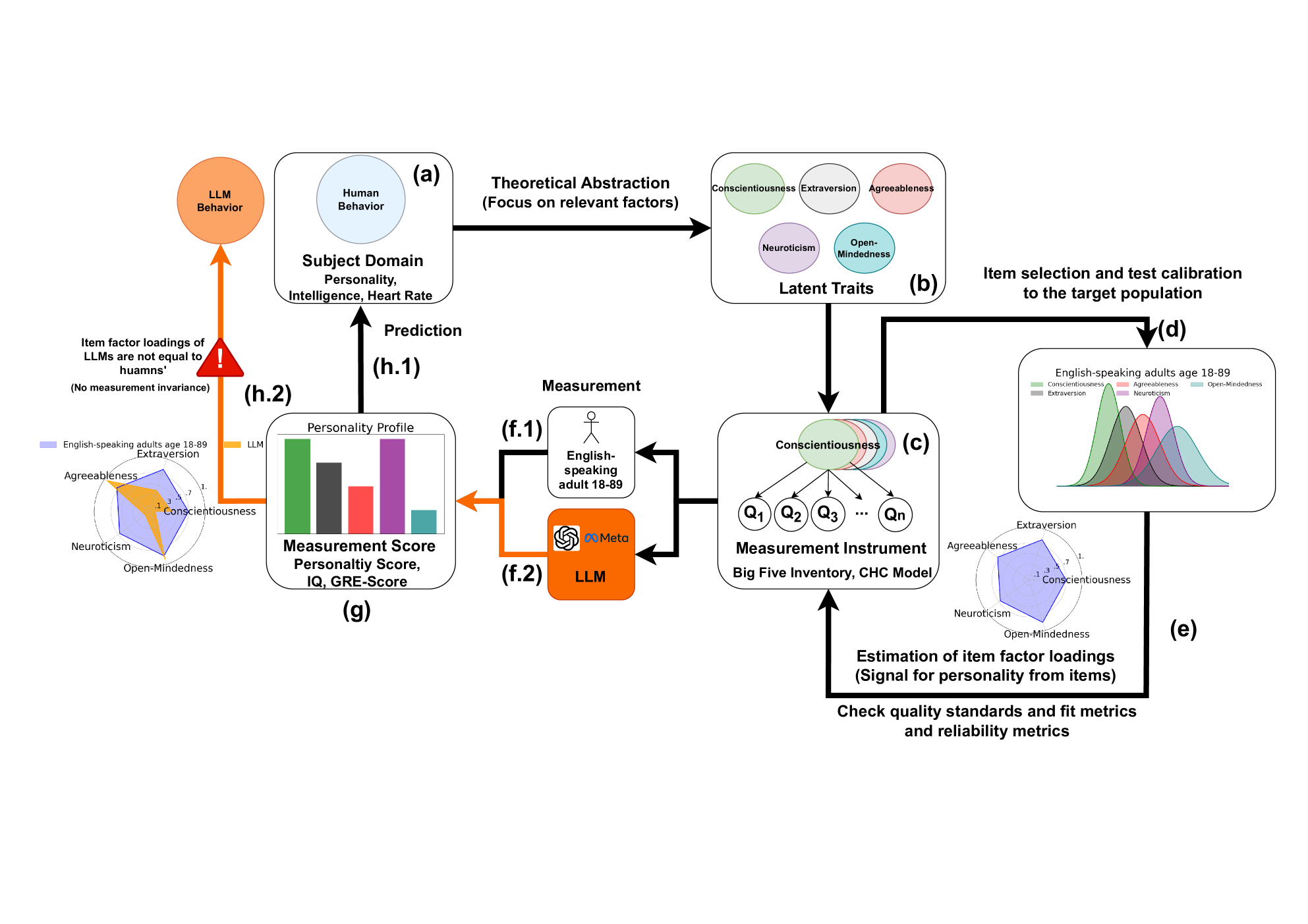
📊 实验亮点
该论文的核心贡献在于对现有AI评估体系的批判性反思,并明确指出使用人类测试评估AI的局限性。虽然没有提供具体的实验结果,但其提出的“停止使用人类测试评估AI,转而开发AI专属的、基于原则的测试方法”的观点,为AI评估领域的研究方向提供了新的思路和指导。
🎯 应用场景
该研究成果对AI领域的评估体系建设具有重要指导意义,可应用于各种AI系统的性能评估,例如大型语言模型、计算机视觉模型和强化学习智能体。通过开发更科学、更严谨的AI专属评估方法,可以更准确地了解AI的能力和局限性,从而促进AI技术的健康发展和负责任的应用。
📄 摘要(原文)
Large Language Models (LLMs) have achieved remarkable results on a range of standardized tests originally designed to assess human cognitive and psychological traits, such as intelligence and personality. While these results are often interpreted as strong evidence of human-like characteristics in LLMs, this paper argues that such interpretations constitute an ontological error. Human psychological and educational tests are theory-driven measurement instruments, calibrated to a specific human population. Applying these tests to non-human subjects without empirical validation, risks mischaracterizing what is being measured. Furthermore, a growing trend frames AI performance on benchmarks as measurements of traits such as ``intelligence'', despite known issues with validity, data contamination, cultural bias and sensitivity to superficial prompt changes. We argue that interpreting benchmark performance as measurements of human-like traits, lacks sufficient theoretical and empirical justification. This leads to our position: Stop Evaluating AI with Human Tests, Develop Principled, AI-specific Tests instead. We call for the development of principled, AI-specific evaluation frameworks tailored to AI systems. Such frameworks might build on existing frameworks for constructing and validating psychometrics tests, or could be created entirely from scratch to fit the unique context of AI.