Efficient Differentially Private Fine-Tuning of LLMs via Reinforcement Learning
作者: Afshin Khadangi, Amir Sartipi, Igor Tchappi, Ramin Bahmani, Gilbert Fridgen
分类: cs.LG, cs.AI, cs.CL
发布日期: 2025-07-30
💡 一句话要点
提出RLDP框架以优化大语言模型的差分隐私微调
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 差分隐私 深度强化学习 大语言模型 模型微调 隐私保护
📋 核心要点
- 现有的差分隐私优化方法在隐私保护与模型效用之间存在明显的权衡,导致模型性能受限。
- RLDP框架通过深度强化学习动态调整梯度裁剪和噪声注入,优化差分隐私的使用效率。
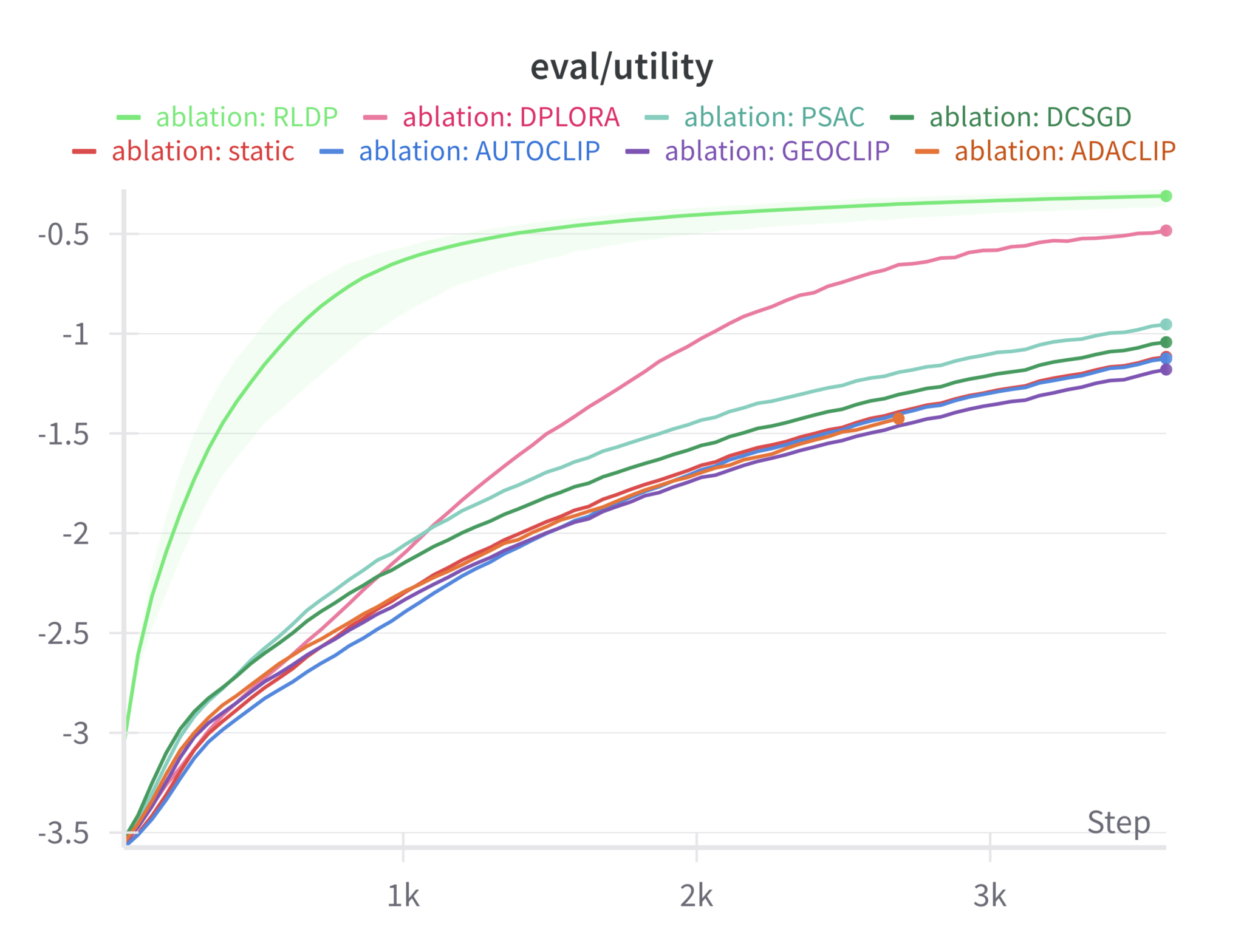
- 在超过1600次的实验中,RLDP在多个模型上实现了5.6%的效用提升,并大幅度减少了训练所需的梯度更新预算。
📝 摘要(中文)
数据隐私与模型效用之间的矛盾已成为大语言模型(LLMs)在敏感数据上应用的主要瓶颈。差分隐私随机梯度下降(DP-SGD)虽然保证了隐私,但却以牺牲样本效率和最终准确性为代价。现有方法的控制参数往往是硬编码的,无法适应优化过程的变化。本文提出RLDP框架,将差分隐私优化视为一个闭环控制问题,利用深度强化学习动态调整每个参数的梯度裁剪阈值和噪声大小。通过对多个模型的实验,RLDP在保持隐私约束的同时,显著提高了模型的效用和训练效率。
🔬 方法详解
问题定义:本文旨在解决大语言模型在差分隐私微调过程中,隐私保护与模型效用之间的矛盾。现有方法的控制参数往往是固定的,无法适应动态优化环境,导致隐私预算的浪费或模型性能的下降。
核心思路:RLDP框架将差分隐私优化视为闭环控制问题,利用深度强化学习实时感知学习动态,并根据需要调整每个参数的梯度裁剪阈值和噪声大小,从而优化隐私预算的分配。
技术框架:RLDP的整体架构包括在线训练的软演员-评论家(SAC)超策略,能够在微调过程中实时学习如何分配隐私预算。框架通过监测学习动态,选择合适的梯度裁剪和噪声注入策略。
关键创新:RLDP的主要创新在于将差分隐私优化转化为动态控制问题,利用深度强化学习实现了对隐私预算的智能分配,显著提高了模型的训练效率和最终效用。
关键设计:RLDP在设计上采用了动态调整的梯度裁剪阈值和高斯噪声注入策略,确保在满足($ε$, $δ$)-DP合同的同时,降低了对模型性能的影响。
🖼️ 关键图片


📊 实验亮点
实验结果表明,RLDP在多个模型上实现了1.3%至30.5%的困惑度降低(平均5.4%),并在下游任务中获得了平均5.6%的效用提升。此外,RLDP在达到基线模型最终效用时,仅需13%至43%的梯度更新预算,平均加速71%。
🎯 应用场景
该研究的潜在应用领域包括医疗、金融等对数据隐私要求严格的行业。通过优化大语言模型的差分隐私微调,RLDP能够在保护用户隐私的同时,提升模型的实用性和准确性,具有重要的实际价值和广泛的应用前景。
📄 摘要(原文)
The tension between data privacy and model utility has become the defining bottleneck for the practical deployment of large language models (LLMs) trained on sensitive corpora including healthcare. Differentially private stochastic gradient descent (DP-SGD) guarantees formal privacy, yet it does so at a pronounced cost: gradients are forcibly clipped and perturbed with noise, degrading sample efficiency and final accuracy. Numerous variants have been proposed to soften this trade-off, but they all share a handicap: their control knobs are hard-coded, global, and oblivious to the evolving optimization landscape. Consequently, practitioners are forced either to over-spend privacy budget in pursuit of utility, or to accept mediocre models in order to stay within privacy constraints. We present RLDP, the first framework to cast DP optimization itself as a closed-loop control problem amenable to modern deep reinforcement learning (RL). RLDP continuously senses rich statistics of the learning dynamics and acts by selecting fine-grained per parameter gradient-clipping thresholds as well as the magnitude of injected Gaussian noise. A soft actor-critic (SAC) hyper-policy is trained online during language model fine-tuning; it learns, from scratch, how to allocate the privacy budget where it matters and when it matters. Across more than 1,600 ablation experiments on GPT2-small, Llama-1B, Llama-3B, and Mistral-7B, RLDP delivers perplexity reductions of 1.3-30.5% (mean 5.4%) and an average 5.6% downstream utility gain. RLDP reaches each baseline's final utility after only 13-43% of the gradient-update budget (mean speed-up 71%), all while honoring the same ($ε$, $δ$)-DP contract and exhibiting equal or lower susceptibility to membership-inference and canary-extraction attacks.