Improving Generative Ad Text on Facebook using Reinforcement Learning
作者: Daniel R. Jiang, Alex Nikulkov, Yu-Chia Chen, Yang Bai, Zheqing Zhu
分类: cs.LG
发布日期: 2025-07-29 (更新: 2025-12-15)
备注: D.J. and A.N. contributed equally, 41 pages, 6 figures
💡 一句话要点
提出基于强化学习的AdLlama模型,提升Facebook广告文本生成效果
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 广告文本生成 强化学习 大型语言模型 点击率优化 性能反馈 在线广告 A/B测试
📋 核心要点
- 现有广告文本生成模型难以充分利用历史广告效果数据,导致生成文本的点击率提升有限。
- 提出一种基于性能反馈的强化学习(RLPF)方法,利用历史广告数据作为奖励信号,优化广告文本生成模型。
- 实验结果表明,AdLlama模型在Facebook广告文本生成任务中,点击率相比基线模型提升了6.7%。
📝 摘要(中文)
生成式人工智能,特别是大型语言模型(LLMs),有望推动变革性的经济变化。LLMs在海量文本数据上进行预训练以学习通用语言模式,但随后的后训练阶段对于将其与特定的现实世界任务对齐至关重要。强化学习(RL)是主要的后训练技术,但其经济影响在很大程度上仍未被探索和量化。我们通过在Facebook上首次部署用于生成广告的RL训练LLM来研究这个问题。我们的模型“AdLlama”集成到Meta的文本生成功能中,为AI工具提供支持,该工具可帮助广告商创建人工撰写的广告文本的新变体。为了训练该模型,我们引入了具有性能反馈的强化学习(RLPF),这是一种使用历史广告性能数据作为奖励信号的后训练方法。在Facebook上为期10周的大规模A/B测试中,涵盖了近35,000名广告商和640,000个广告变体,我们发现与在精选广告上训练的有监督模仿模型相比,AdLlama将点击率提高了6.7%(p = 0.0296)。这代表了广告商在Facebook上的投资回报率的显着提高。我们还发现,使用AdLlama的广告商生成了更多的广告变体,表明他们对模型的输出更加满意。据我们所知,这是迄今为止在生态有效环境中对生成式AI的使用进行的最大规模的研究,为量化RL后训练的实际影响提供了一个重要的数据点。此外,结果表明,RLPF是一种有前途且可推广的度量驱动的后训练方法,可弥合功能强大的语言模型与有形结果之间的差距。
🔬 方法详解
问题定义:论文旨在解决广告文本生成领域中,如何有效利用历史广告效果数据来提升生成文本的点击率的问题。现有方法,例如有监督的模仿学习,通常依赖于人工标注或精选的广告数据,难以充分捕捉广告效果与文本之间的复杂关系,导致生成文本的点击率提升有限。
核心思路:论文的核心思路是将广告文本生成任务建模为一个强化学习问题,并利用历史广告效果数据作为奖励信号,通过强化学习算法来优化生成模型。这种方法能够直接优化广告的点击率等关键指标,从而生成更有效的广告文本。
技术框架:整体框架包含以下几个主要模块:1) 广告文本生成模型(AdLlama),基于大型语言模型;2) 奖励函数,基于历史广告的点击率等性能指标;3) 强化学习算法,用于优化生成模型,使其能够生成更高点击率的广告文本。具体流程是:AdLlama生成广告文本,在Facebook平台上进行投放,收集广告的点击率等数据,然后将这些数据作为奖励信号反馈给强化学习算法,用于更新AdLlama模型的参数。
关键创新:论文最重要的技术创新点在于提出了基于性能反馈的强化学习(RLPF)方法。与传统的强化学习方法不同,RLPF直接利用历史广告的性能数据作为奖励信号,避免了人工设计奖励函数的困难,并且能够更准确地反映广告效果与文本之间的关系。
关键设计:奖励函数的设计至关重要,论文使用历史广告的点击率作为奖励信号。此外,论文还采用了合适的强化学习算法,例如策略梯度算法,来优化AdLlama模型的参数。AdLlama模型基于Transformer架构,并进行了针对广告文本生成的微调。
🖼️ 关键图片

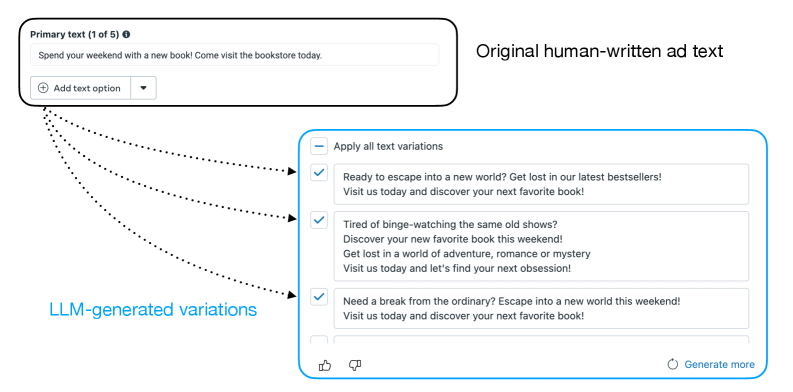
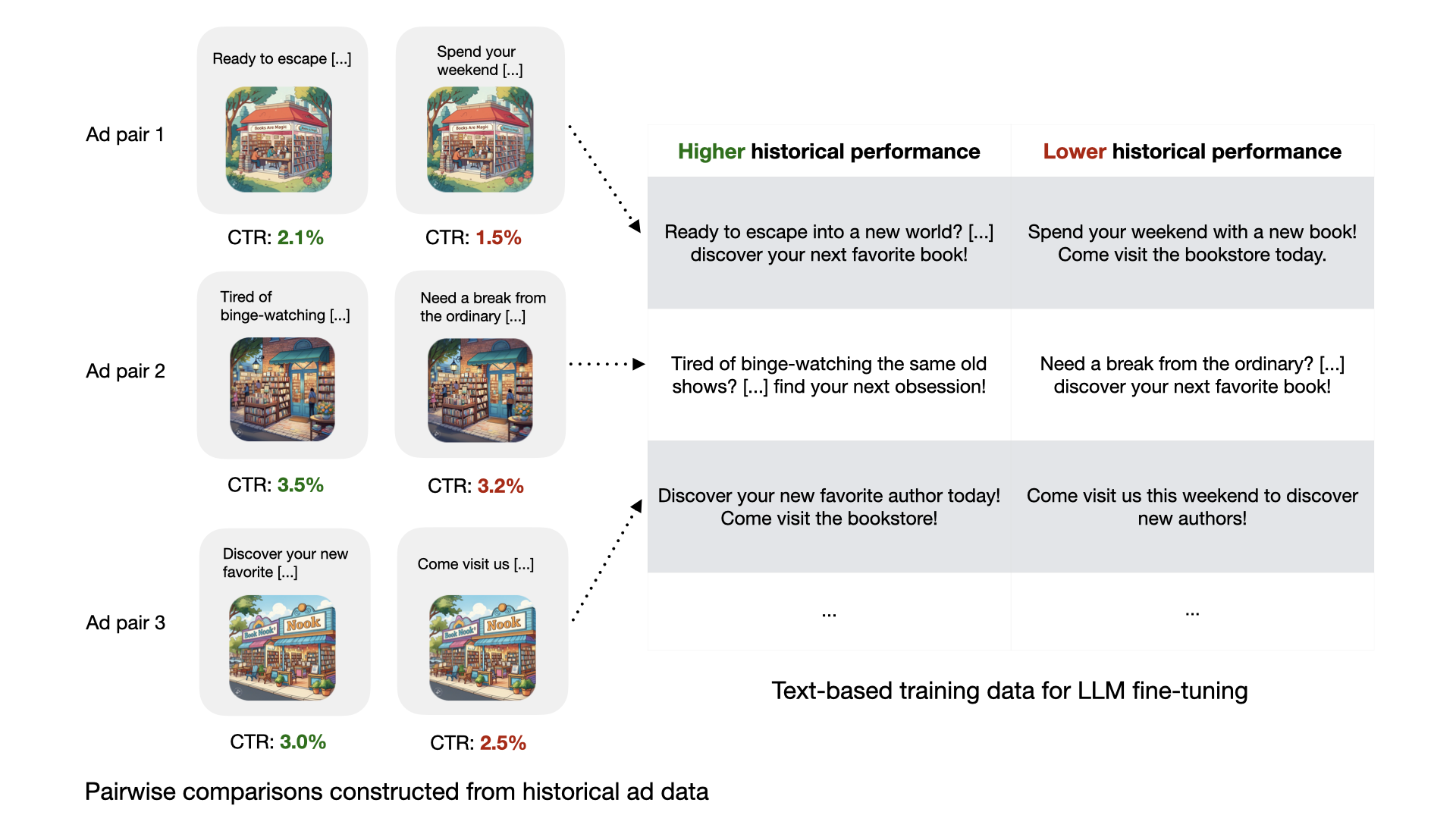
📊 实验亮点
在Facebook平台上进行的大规模A/B测试表明,AdLlama模型相比于有监督的模仿学习模型,点击率提升了6.7% (p=0.0296)。该实验涵盖了近35,000名广告商和640,000个广告变体,证明了AdLlama模型在实际应用中的有效性和优越性。
🎯 应用场景
该研究成果可广泛应用于在线广告领域,帮助广告商生成更具吸引力的广告文本,提高广告点击率和转化率,从而提升广告投放效果和投资回报率。此外,该方法还可以推广到其他文本生成任务中,例如社交媒体内容生成、产品描述生成等,具有广阔的应用前景。
📄 摘要(原文)
Generative artificial intelligence (AI), in particular large language models (LLMs), is poised to drive transformative economic change. LLMs are pre-trained on vast text data to learn general language patterns, but a subsequent post-training phase is critical to align them for specific real-world tasks. Reinforcement learning (RL) is the leading post-training technique, yet its economic impact remains largely underexplored and unquantified. We examine this question through the lens of the first deployment of an RL-trained LLM for generative advertising on Facebook. Integrated into Meta's Text Generation feature, our model, "AdLlama," powers an AI tool that helps advertisers create new variations of human-written ad text. To train this model, we introduce reinforcement learning with performance feedback (RLPF), a post-training method that uses historical ad performance data as a reward signal. In a large-scale 10-week A/B test on Facebook spanning nearly 35,000 advertisers and 640,000 ad variations, we find that AdLlama improves click-through rates by 6.7% (p=0.0296) compared to a supervised imitation model trained on curated ads. This represents a substantial improvement in advertiser return on investment on Facebook. We also find that advertisers who used AdLlama generated more ad variations, indicating higher satisfaction with the model's outputs. To our knowledge, this is the largest study to date on the use of generative AI in an ecologically valid setting, offering an important data point quantifying the tangible impact of RL post-training. Furthermore, the results show that RLPF is a promising and generalizable approach for metric-driven post-training that bridges the gap between highly capable language models and tangible outcomes.