Filtering with Self-Attention and Storing with MLP: One-Layer Transformers Can Provably Acquire and Extract Knowledge
作者: Ruichen Xu, Kexin Chen
分类: cs.LG, cs.CL
发布日期: 2025-07-28 (更新: 2025-11-25)
💡 一句话要点
通过自注意力过滤和MLP存储:单层Transformer可证明地获取和提取知识
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: Transformer 知识获取 知识提取 预训练 微调 泛化能力 幻觉 单层Transformer
📋 核心要点
- 现有理论研究忽略了MLP在知识存储中的作用、OOD适应性和next-token预测目标,导致对LLM知识获取和提取机制理解不全面。
- 论文提出一个基于单层Transformer的理论框架,分析其在预训练和微调阶段的知识获取和提取能力,并考虑了MLP、OOD适应性和next-token预测。
- 实验结果验证了理论分析,表明Transformer在满足特定条件下能够有效获取和提取知识,并解释了幻觉现象产生的原因。
📝 摘要(中文)
大型语言模型(LLMs)在知识密集型任务上表现出色,但预训练期间知识获取(存储和记忆)以及微调后推理期间知识提取(检索和回忆)的理论机制仍不清楚。以往的理论研究通过分析训练动态来探索这些过程,但忽略了关键组成部分:(1) 多层感知机(MLP),经验表明它是知识存储的主要模块;(2) 分布外(OOD)适应性,使LLMs能够泛化到预训练后未见过的场景;(3) 下一个token预测,这是将知识编码为条件概率的标准自回归目标。本文提出了首个理论框架,通过研究单层Transformer的训练动态来解决这些局限性。在正则性假设下,证明了:(i) Transformer在预训练期间达到接近最优的训练损失,表明有效的知识获取;(ii) 给定足够大的微调数据集和适当的数据重数条件,Transformer在预训练期间获取但未在微调中重新访问的事实知识上实现了较低的泛化误差,表明强大的知识提取;(iii) 违反这些条件会导致泛化误差升高,表现为幻觉。分析涵盖了完全微调和低秩微调,深入了解了低秩自适应方法的有效性。通过在合成数据集和真实世界的PopQA基准上使用GPT-2和Llama-3.2-1B模型进行的实验验证了理论结果。
🔬 方法详解
问题定义:现有理论研究未能充分解释大型语言模型(LLMs)在预训练阶段如何存储知识,以及在微调后如何提取知识,尤其是在面对分布外(OOD)数据时。以往研究忽略了MLP在知识存储中的关键作用,以及next-token预测这一标准自回归目标的影响。这些局限性导致对LLM知识获取和提取机制的理解不完整。
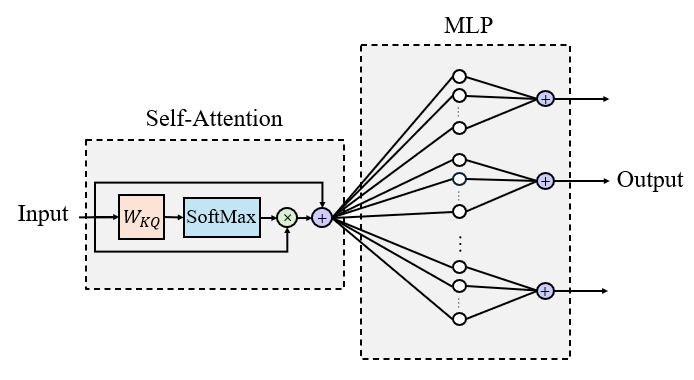
核心思路:论文的核心思路是通过分析单层Transformer的训练动态,来揭示知识获取和提取的理论机制。单层Transformer结构简单,便于进行数学分析,同时保留了自注意力和MLP这两个关键模块。通过研究其在预训练和微调阶段的行为,可以深入理解知识是如何被存储在MLP中,以及如何通过自注意力机制进行过滤和提取。
技术框架:该研究的技术框架主要包括以下几个阶段:1) 建立单层Transformer的数学模型,包括自注意力机制和MLP;2) 分析预训练阶段的训练动态,证明Transformer能够有效地获取知识并达到接近最优的训练损失;3) 分析微调阶段的泛化能力,证明在满足一定条件下,Transformer能够提取预训练阶段获取的知识,并在OOD数据上表现良好;4) 探讨违反这些条件时可能出现的幻觉现象。
关键创新:论文的关键创新在于:1) 首次将MLP、OOD适应性和next-token预测纳入到LLM知识获取和提取的理论框架中;2) 通过分析单层Transformer的训练动态,为理解LLM的知识存储和提取机制提供了新的视角;3) 提出了导致幻觉现象的理论解释,并给出了避免幻觉的条件。
关键设计:论文的关键设计包括:1) 使用单层Transformer作为研究对象,简化了数学分析的复杂度;2) 对数据分布和模型参数进行了一定的正则性假设,以便进行理论推导;3) 考虑了全量微调和低秩微调两种微调策略,并分析了它们的优缺点;4) 使用合成数据集和真实数据集(PopQA)进行实验验证,以验证理论结果的有效性。
🖼️ 关键图片

📊 实验亮点
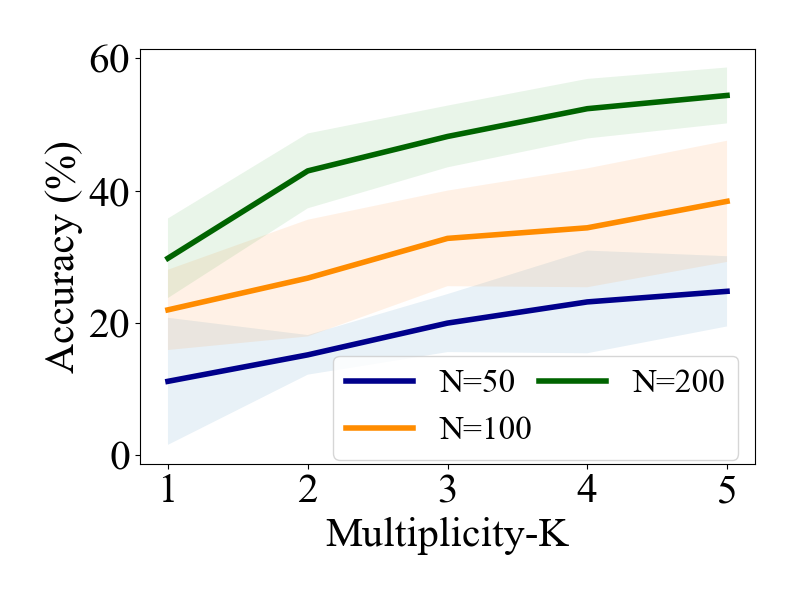
实验结果表明,在合成数据集和PopQA数据集上,GPT-2和Llama-3.2-1B模型验证了理论分析的有效性。研究表明,在满足特定数据条件下,Transformer能够有效提取预训练知识,否则可能产生幻觉。此外,研究还深入分析了低秩微调的有效性,为实际应用提供了指导。
🎯 应用场景
该研究成果有助于更好地理解大型语言模型的内部机制,为模型设计和训练提供理论指导。通过避免幻觉,可以提高LLM在知识密集型任务中的可靠性。此外,该研究对于开发更高效的微调方法,例如低秩自适应,具有重要的指导意义,从而降低LLM的部署成本。
📄 摘要(原文)
Modern large language models (LLMs) demonstrate exceptional performance on knowledge-intensive tasks, yet the theoretical mechanisms underlying knowledge acquisition (storage and memorization) during pre-training and extraction (retrieval and recall) during inference after fine-tuning remain poorly understood. Although prior theoretical studies have explored these processes through analyses of training dynamics, they overlook critical components essential for a comprehensive theory: (1) the multi-layer perceptron (MLP), empirically identified as the primary module for knowledge storage; (2) out-of-distribution (OOD) adaptivity, which enables LLMs to generalize to unseen scenarios post-pre-training; and (3) next-token prediction, the standard autoregressive objective that encodes knowledge as conditional probabilities. In this work, we introduce, to the best of our knowledge, the first theoretical framework that addresses these limitations by examining the training dynamics of one-layer transformers. Under regularity assumptions, we establish that: (i) transformers attain near-optimal training loss during pre-training, demonstrating effective knowledge acquisition; (ii) given a sufficiently large fine-tuning dataset and appropriate data multiplicity conditions, transformers achieve low generalization error on factual knowledge acquired during pre-training but not revisited in fine-tuning, indicating robust knowledge extraction; and (iii) violation of these conditions leads to elevated generalization error, manifesting as hallucinations. Our analysis encompasses both full fine-tuning and low-rank fine-tuning, yielding insights into the efficacy of practical low-rank adaptation methods. We validate our theoretical findings through experiments on synthetic datasets and the real-world PopQA benchmark, employing GPT-2 and Llama-3.2-1B models.