SmallThinker: A Family of Efficient Large Language Models Natively Trained for Local Deployment
作者: Yixin Song, Zhenliang Xue, Dongliang Wei, Feiyang Chen, Jianxiang Gao, Junchen Liu, Hangyu Liang, Guangshuo Qin, Chengrong Tian, Bo Wen, Longyu Zhao, Xinrui Zheng, Zeyu Mi, Haibo Chen
分类: cs.LG, cs.AI
发布日期: 2025-07-28 (更新: 2025-07-30)
💡 一句话要点
SmallThinker:为本地部署原生设计的高效大语言模型家族
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 本地部署 模型压缩 混合专家模型 稀疏注意力
📋 核心要点
- 现有大语言模型部署受限于GPU云基础设施,无法充分利用本地设备算力。
- SmallThinker通过部署感知架构,结合稀疏MoE、预注意力路由和混合稀疏注意力,优化本地部署性能。
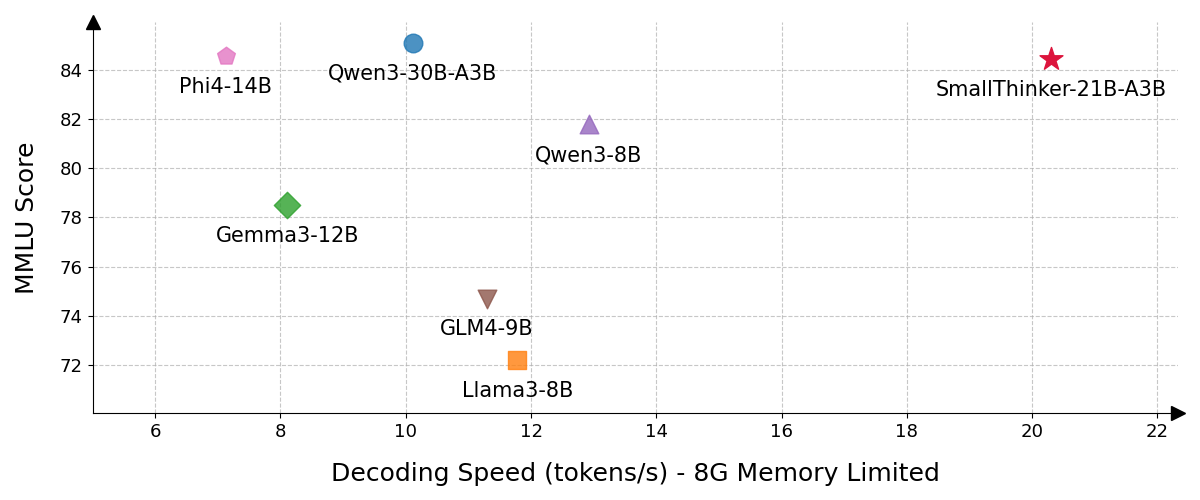
- SmallThinker在消费级CPU上实现了超过20 tokens/s的推理速度,内存占用极低,性能优于同等或更大模型。
📝 摘要(中文)
本文提出了SmallThinker,一个专为本地设备约束(计算能力弱、内存有限、存储慢)原生设计的大语言模型家族。与主要压缩云端模型的传统方法不同,SmallThinker从底层架构上针对这些限制进行了优化。其创新之处在于一种部署感知的架构,将约束转化为设计原则。首先,引入了结合细粒度混合专家(MoE)和稀疏前馈网络的双层稀疏结构,显著降低了计算需求,同时不牺牲模型容量。其次,为了克服慢速存储的I/O瓶颈,设计了一种预注意力路由,使协同设计的推理引擎能够在计算注意力时从存储中预取专家参数,有效隐藏了存储延迟。第三,为了提高内存效率,利用NoPE-RoPE混合稀疏注意力机制来减少KV缓存需求。发布的SmallThinker-4B-A0.6B和SmallThinker-21B-A3B实现了最先进的性能,甚至优于更大的LLM。值得注意的是,协同设计的系统几乎消除了对昂贵GPU硬件的需求:通过Q4_0量化,两个模型在普通消费级CPU上均超过20 tokens/s,同时分别仅消耗1GB和8GB的内存。
🔬 方法详解
问题定义:现有的大语言模型通常针对云计算环境设计,在计算能力、内存和存储资源受限的本地设备上部署时,面临着计算量大、内存占用高、I/O瓶颈等问题,导致推理速度慢,用户体验差。现有方法主要集中在模型压缩,但难以从根本上解决本地部署的固有约束。
核心思路:SmallThinker的核心思路是“部署感知设计”,即从一开始就将本地设备的约束(计算能力、内存、存储)纳入模型架构设计中,而不是在云端训练的模型上进行压缩或优化。通过协同设计模型架构和推理引擎,将硬件约束转化为设计原则,从而在本地设备上实现高效推理。
技术框架:SmallThinker的整体架构包含三个主要组成部分:双层稀疏结构、预注意力路由和混合稀疏注意力机制。双层稀疏结构通过细粒度MoE和稀疏前馈网络减少计算需求。预注意力路由使推理引擎能够在计算注意力时预取专家参数,隐藏存储延迟。混合稀疏注意力机制通过减少KV缓存需求来提高内存效率。这些组件协同工作,共同优化本地部署性能。
关键创新:SmallThinker的关键创新在于其“部署感知”的设计理念和协同优化方法。与传统的模型压缩方法不同,SmallThinker从底层架构上针对本地设备的约束进行了优化,实现了计算、内存和I/O的全面优化。预注意力路由是另一个重要的创新点,它有效地解决了本地设备上存储速度慢的瓶颈问题。
关键设计:SmallThinker采用了多种关键设计。双层稀疏结构中,MoE的专家数量和稀疏前馈网络的稀疏度是重要的参数。预注意力路由的设计需要仔细考虑预取策略和缓存大小。混合稀疏注意力机制中,NoPE和RoPE的比例需要根据具体任务进行调整。此外,模型量化也是提高推理速度和降低内存占用的关键技术。
🖼️ 关键图片

📊 实验亮点
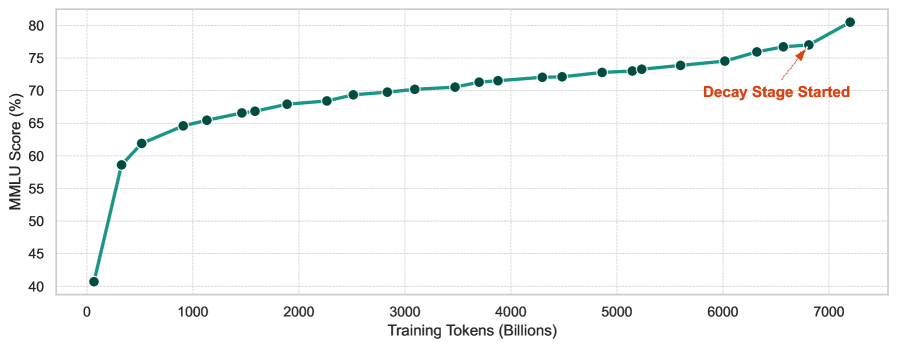
SmallThinker-4B-A0.6B和SmallThinker-21B-A3B在多个基准测试中取得了最先进的性能,甚至优于更大的LLM。在消费级CPU上,通过Q4_0量化,两个模型均实现了超过20 tokens/s的推理速度,同时分别仅消耗1GB和8GB的内存。这些结果表明,SmallThinker在本地设备上具有出色的性能和效率。
🎯 应用场景
SmallThinker适用于各种需要在本地设备上运行大语言模型的场景,例如智能手机、嵌入式设备、边缘服务器等。它可以用于离线翻译、本地对话、智能助手、内容生成等应用,在保护用户隐私的同时,提供快速、高效的AI服务。该研究的成果将推动大语言模型在资源受限环境下的普及应用。
📄 摘要(原文)
While frontier large language models (LLMs) continue to push capability boundaries, their deployment remains confined to GPU-powered cloud infrastructure. We challenge this paradigm with SmallThinker, a family of LLMs natively designed - not adapted - for the unique constraints of local devices: weak computational power, limited memory, and slow storage. Unlike traditional approaches that mainly compress existing models built for clouds, we architect SmallThinker from the ground up to thrive within these limitations. Our innovation lies in a deployment-aware architecture that transforms constraints into design principles. First, We introduce a two-level sparse structure combining fine-grained Mixture-of-Experts (MoE) with sparse feed-forward networks, drastically reducing computational demands without sacrificing model capacity. Second, to conquer the I/O bottleneck of slow storage, we design a pre-attention router that enables our co-designed inference engine to prefetch expert parameters from storage while computing attention, effectively hiding storage latency that would otherwise cripple on-device inference. Third, for memory efficiency, we utilize NoPE-RoPE hybrid sparse attention mechanism to slash KV cache requirements. We release SmallThinker-4B-A0.6B and SmallThinker-21B-A3B, which achieve state-of-the-art performance scores and even outperform larger LLMs. Remarkably, our co-designed system mostly eliminates the need for expensive GPU hardware: with Q4_0 quantization, both models exceed 20 tokens/s on ordinary consumer CPUs, while consuming only 1GB and 8GB of memory respectively. SmallThinker is publicly available at hf.co/PowerInfer/SmallThinker-4BA0.6B-Instruct and hf.co/PowerInfer/SmallThinker-21BA3B-Instruct.