Repairing vulnerabilities without invisible hands. A differentiated replication study on LLMs
作者: Maria Camporese, Fabio Massacci
分类: cs.SE, cs.CR, cs.LG
发布日期: 2025-07-28 (更新: 2026-01-14)
💡 一句话要点
通过差异化复现研究揭示LLM自动修复漏洞的潜在因素
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 自动漏洞修复 大型语言模型 程序修复 漏洞定位 复现研究
📋 核心要点
- 现有自动漏洞修复方法依赖LLM,但其有效性可能受到训练数据泄露等因素的影响。
- 该研究通过人为引入定位误差,探究LLM修复漏洞是否依赖于记忆而非真正理解。
- 通过控制实验,评估LLM在不同定位误差下的修复能力,并分析其潜在的局限性。
📝 摘要(中文)
背景:自动漏洞修复(AVR)是程序修复领域中一个快速发展的分支。最近的研究表明,大型语言模型(LLM)在代码生成和故障检测方面的表现优于传统技术,扩展了其成功应用范围。假设:这些优势可能受到隐藏因素的影响,例如训练数据泄露或完美的故障定位,使得LLM能够重现人工编写的相同代码修复。目标:我们通过在提示中故意添加错误到报告的漏洞位置,在受控条件下复现先前的AVR研究。如果LLM仅仅是复述记忆中的修复,那么无论定位误差大小,都应该产生相同数量的正确补丁,因为任何偏移都应该使模型偏离原始修复。方法:我们的流程修复了Vul4J和VJTrans基准测试中的漏洞,方法是将故障位置从真实值移动n行。首先,一个LLM生成补丁,第二个LLM审查它,我们使用回归测试和漏洞证明测试来验证结果。最后,我们手动审核一个补丁样本,并使用Agresti-Coull-Wilson方法估计错误率。
🔬 方法详解
问题定义:论文旨在研究大型语言模型(LLM)在自动漏洞修复(AVR)任务中的真实能力,特别是要验证LLM是否仅仅依赖于记忆训练数据中的修复方案,而非真正理解漏洞并进行修复。现有方法在评估LLM的AVR能力时,可能存在“隐形之手”因素,例如训练数据泄露或完美的故障定位,导致评估结果偏高。
核心思路:核心思路是通过人为引入故障定位误差,即在提示LLM进行漏洞修复时,故意将漏洞位置偏移一定行数。如果LLM仅仅是复述记忆中的修复方案,那么无论偏移量大小,其修复效果应该相似。反之,如果LLM能够真正理解漏洞并进行修复,那么随着偏移量的增大,修复效果应该下降。
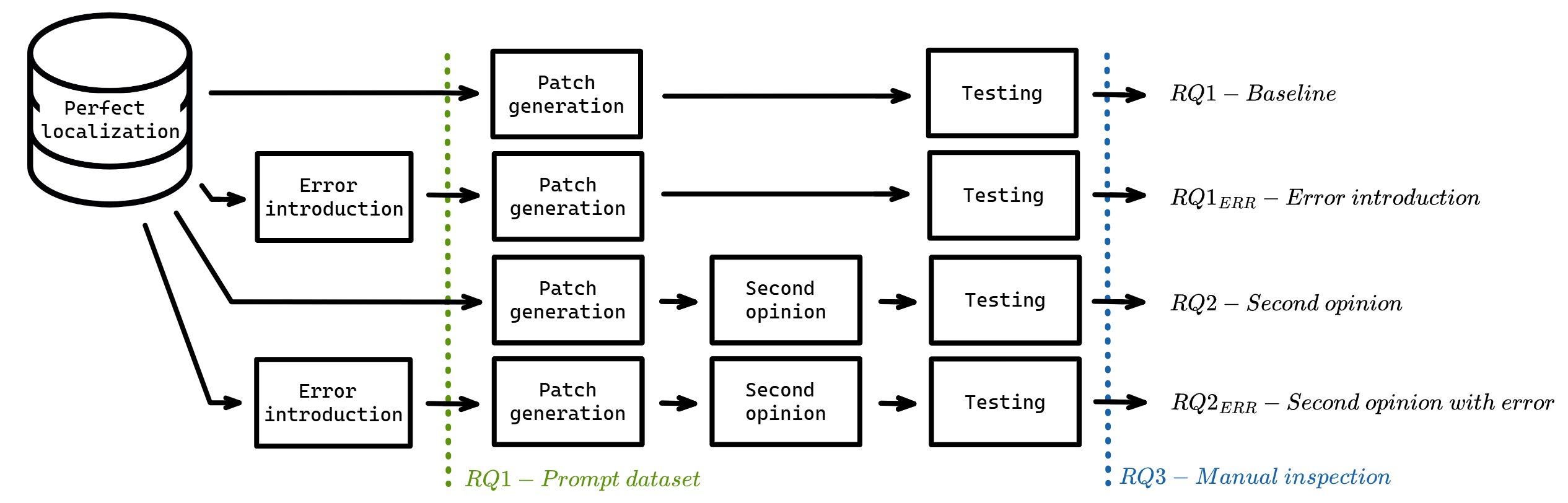
技术框架:整体流程包括以下几个步骤:1) 从Vul4J和VJTrans基准测试中选取漏洞;2) 将漏洞的真实位置偏移n行(n为可控变量);3) 使用第一个LLM(patch generation LLM)根据偏移后的位置生成补丁;4) 使用第二个LLM(patch review LLM)对生成的补丁进行审查;5) 使用回归测试和漏洞证明测试验证补丁的有效性;6) 手动审核一部分补丁,并使用Agresti-Coull-Wilson方法估计错误率。
关键创新:该研究的关键创新在于通过引入可控的故障定位误差,来区分LLM是依赖于记忆还是真正理解漏洞。这种方法能够更准确地评估LLM在AVR任务中的真实能力,并揭示其潜在的局限性。
关键设计:关键设计包括:1) 使用Vul4J和VJTrans这两个常用的漏洞修复基准测试;2) 使用两个LLM,一个用于生成补丁,另一个用于审查补丁,以提高修复的可靠性;3) 使用回归测试和漏洞证明测试来验证补丁的有效性;4) 手动审核一部分补丁,以更准确地评估修复的质量;5) 使用Agresti-Coull-Wilson方法估计错误率,以提供更可靠的统计结果。
🖼️ 关键图片

📊 实验亮点
该研究通过控制故障定位误差,发现LLM在自动漏洞修复中可能过度依赖记忆,而非真正理解漏洞。实验结果表明,即使引入较小的定位误差,LLM的修复效果也会显著下降,这表明现有LLM在AVR任务中存在一定的局限性,需要进一步改进。
🎯 应用场景
该研究成果可应用于评估和改进现有自动漏洞修复系统的可靠性。通过了解LLM在不同场景下的修复能力,可以更好地利用LLM进行漏洞修复,并开发更有效的漏洞修复工具。此外,该研究也为未来LLM在程序理解和修复方面的研究提供了新的思路。
📄 摘要(原文)
Background: Automated Vulnerability Repair (AVR) is a fast-growing branch of program repair. Recent studies show that large language models (LLMs) outperform traditional techniques, extending their success beyond code generation and fault detection. Hypothesis: These gains may be driven by hidden factors -- "invisible hands" such as training-data leakage or perfect fault localization -- that let an LLM reproduce human-authored fixes for the same code. Objective: We replicate prior AVR studies under controlled conditions by deliberately adding errors to the reported vulnerability location in the prompt. If LLMs merely regurgitate memorized fixes, both small and large localization errors should yield the same number of correct patches, because any offset should divert the model from the original fix. Method: Our pipeline repairs vulnerabilities from the Vul4J and VJTrans benchmarks after shifting the fault location by n lines from the ground truth. A first LLM generates a patch, a second LLM reviews it, and we validate the result with regression and proof-of-vulnerability tests. Finally, we manually audit a sample of patches and estimate the error rate with the Agresti-Coull-Wilson method.